Download as PDF, PPTX


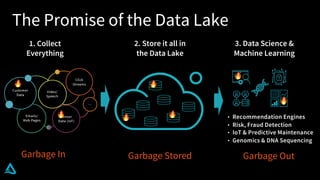

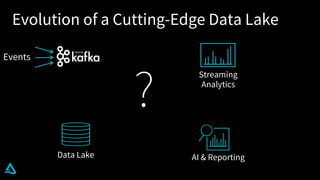
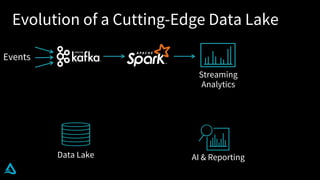
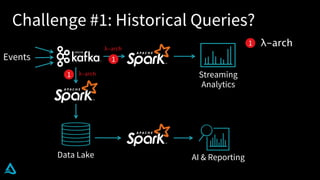
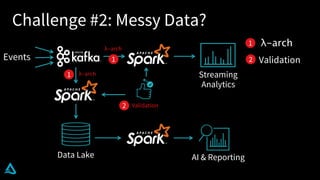





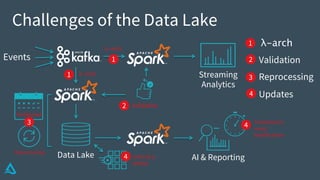
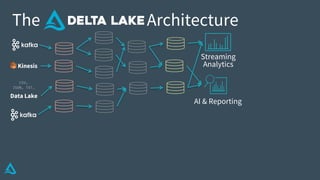
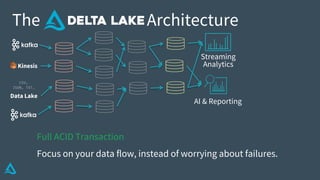
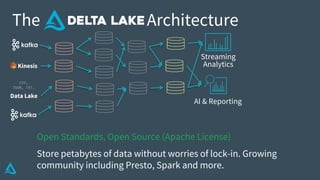
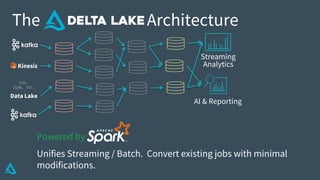
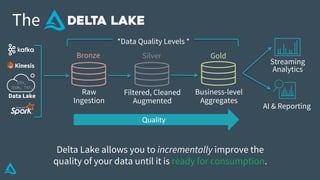
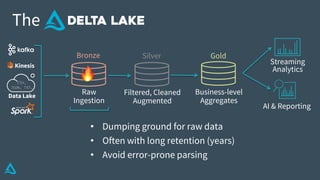
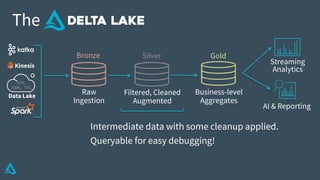
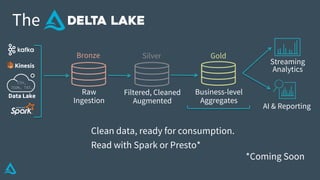
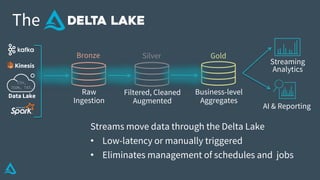
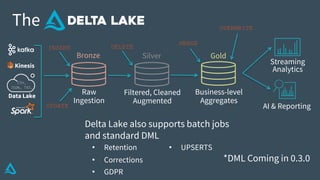
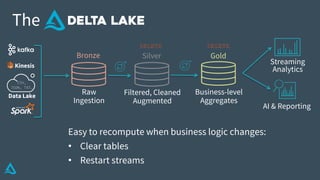

















The document discusses the enhancement of Apache Spark with Delta Lake, focusing on the integration of data lakes for machine learning and data analytics. It outlines the challenges associated with data lakes, such as messy data and updates, and presents Delta Lake as a solution that improves data quality and processing efficiency. The document also emphasizes Delta Lake's capabilities for handling large datasets and its growing adoption among organizations worldwide.























































































