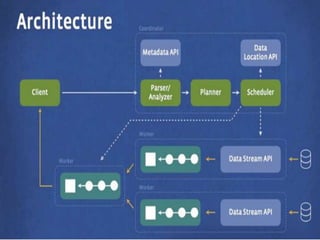
Presto is an open source distributed SQL query engine that allows querying large datasets ranging from gigabytes to petabytes faster and more interactively. It employs a custom query execution engine with pipelined operators designed for SQL semantics, avoiding unnecessary I/O and latency overhead. The Presto coordinator parses, analyzes, and plans queries, assigning work to nodes closest to data and monitoring progress, while clients pull results from output stages. Presto developers claim it is 10x better than Hive/MapReduce for most queries in terms of efficiency and latency.