Downloaded 18 times




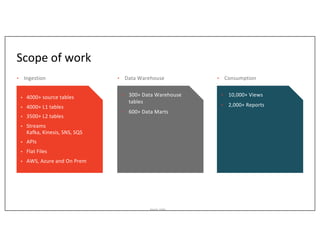

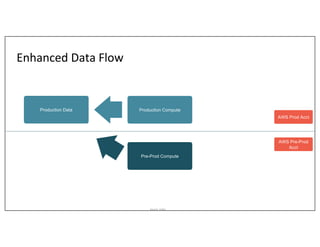
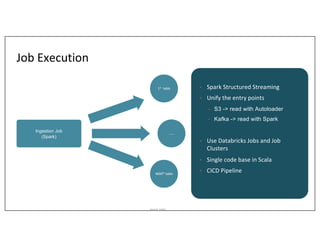

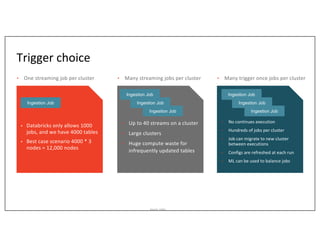

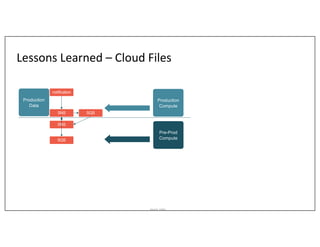
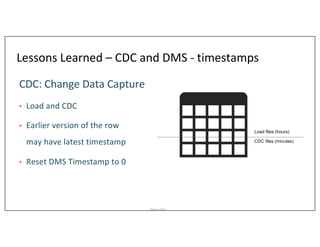












This document outlines Asurion's large-scale lakehouse implementation using structured streaming, detailing their architecture and data ingestion strategies across multiple sources. It highlights the challenges faced, lessons learned during the process, and the technology stack employed, including Apache Spark, AWS, and Delta Lake. Key points include optimizing job execution, managing cloud files, and addressing limitations with change data capture and Kafka integration.










































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)








![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)



