Download as ODP, PPTX









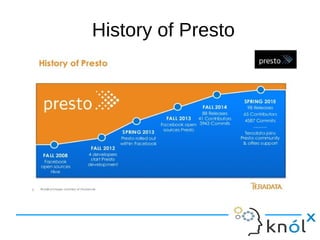
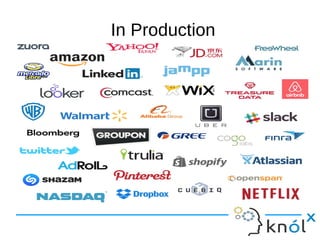
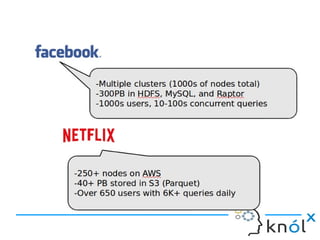
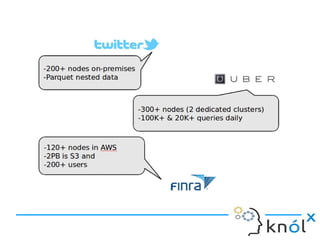
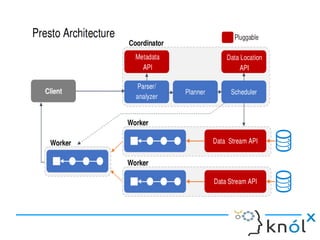
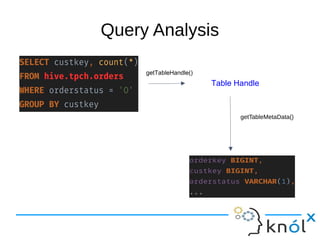
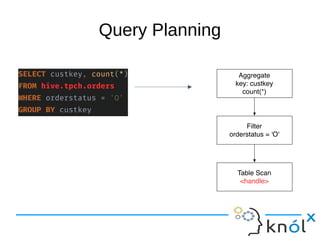
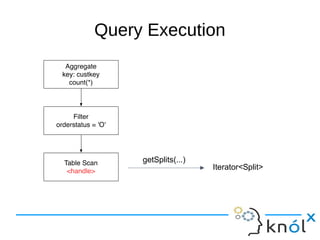
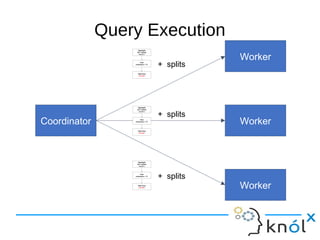
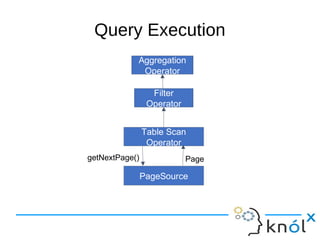

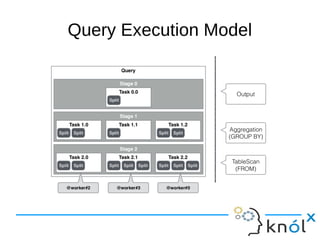

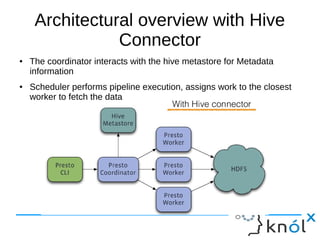
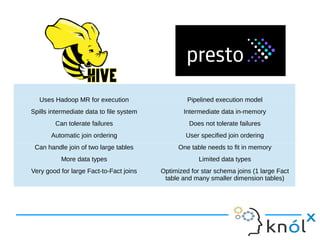
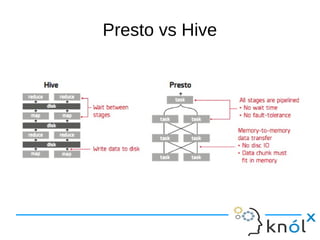
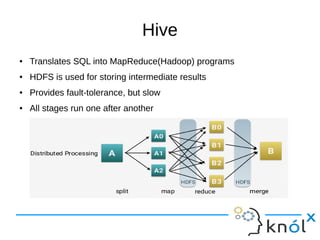
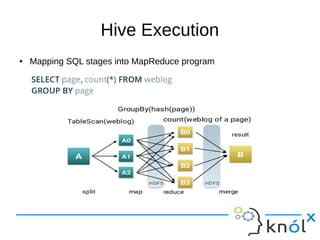
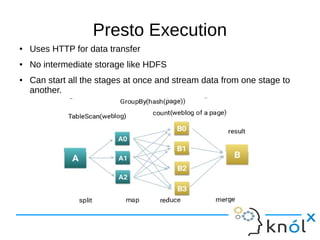
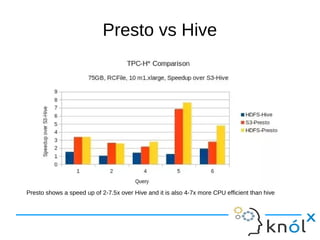









This document presents an overview of Presto, an open-source distributed SQL query engine designed for interactive analytics on large data sets. It contrasts Presto with traditional databases and other query engines, emphasizing its performance, scalability, and flexibility, as well as detailing its architecture, setup, and connectors. Additionally, it discusses the historical context of Presto's development and its use in production environments by notable companies.





































































































