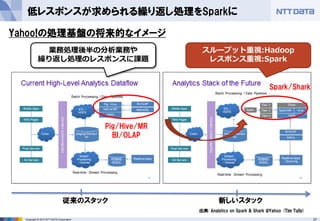
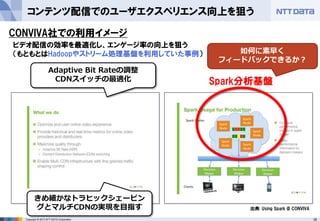
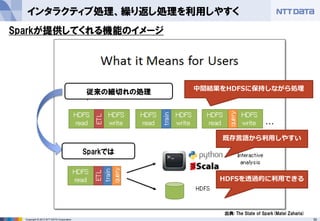
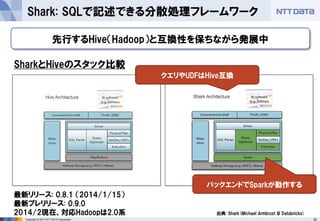
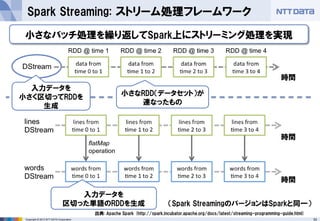
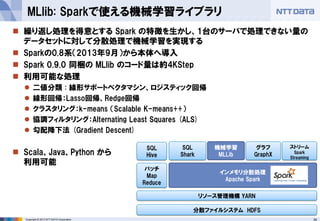
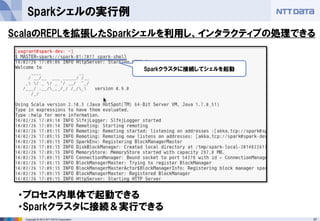
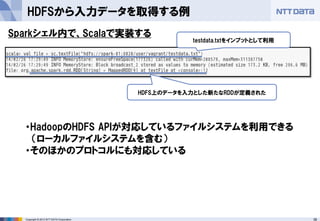
第16回 Hadoopソースコードリーディング(2014/05/29) 発表資料 『Apache Sparkのご紹介』(前半:Sparkのキホン) NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス 土橋 昌 (Masaru Dobashi) http://oss.nttdata.co.jp/ 後半はこちら → http://www.slideshare.net/hadoopxnttdata/apache-spark




























































![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)
































