Download as PDF, PPTX






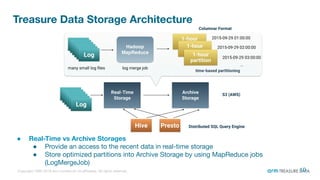
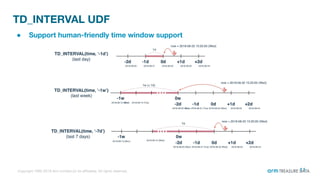


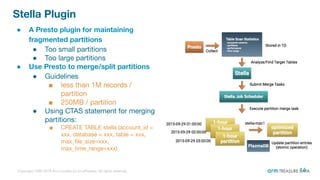

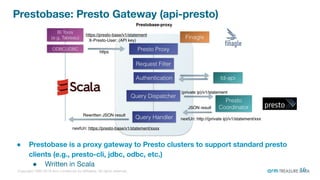
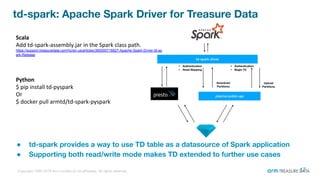

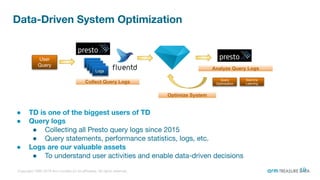
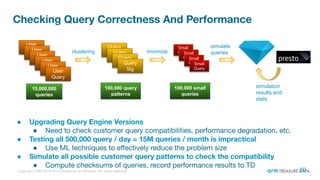
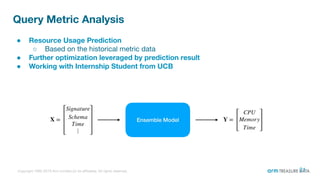
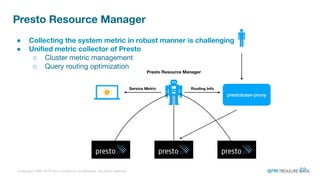

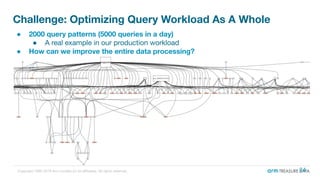
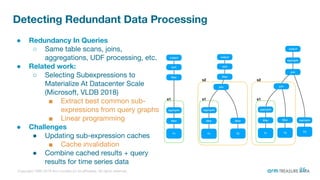
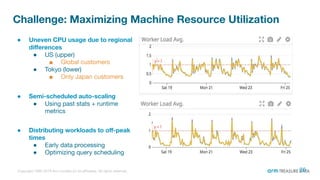

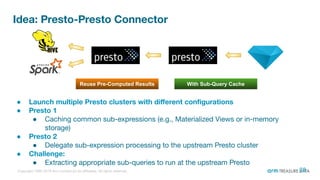
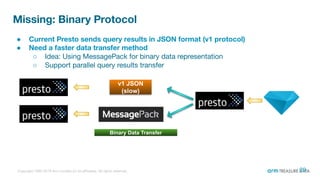



The document is a presentation from the Presto Conference Tokyo 2019 by Kai Sasaki and Taro L. Saito from Arm Treasure Data, highlighting the advancements and architecture of their unified data platform, Treasure Data. It discusses the use of Presto for data processing, the integration of various storage architectures, and techniques for optimizing queries and resource management. Additionally, it covers the development of plugins, extensions, and challenges faced in data optimization and processing at scale.















![Introducing TiDB [Delivered: 09/27/18 at NYC SQL Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/nycmysqlintroducingtidb-180928024621-thumbnail.jpg?width=640&height=640&fit=bounds)



































































