Download as PDF, PPTX




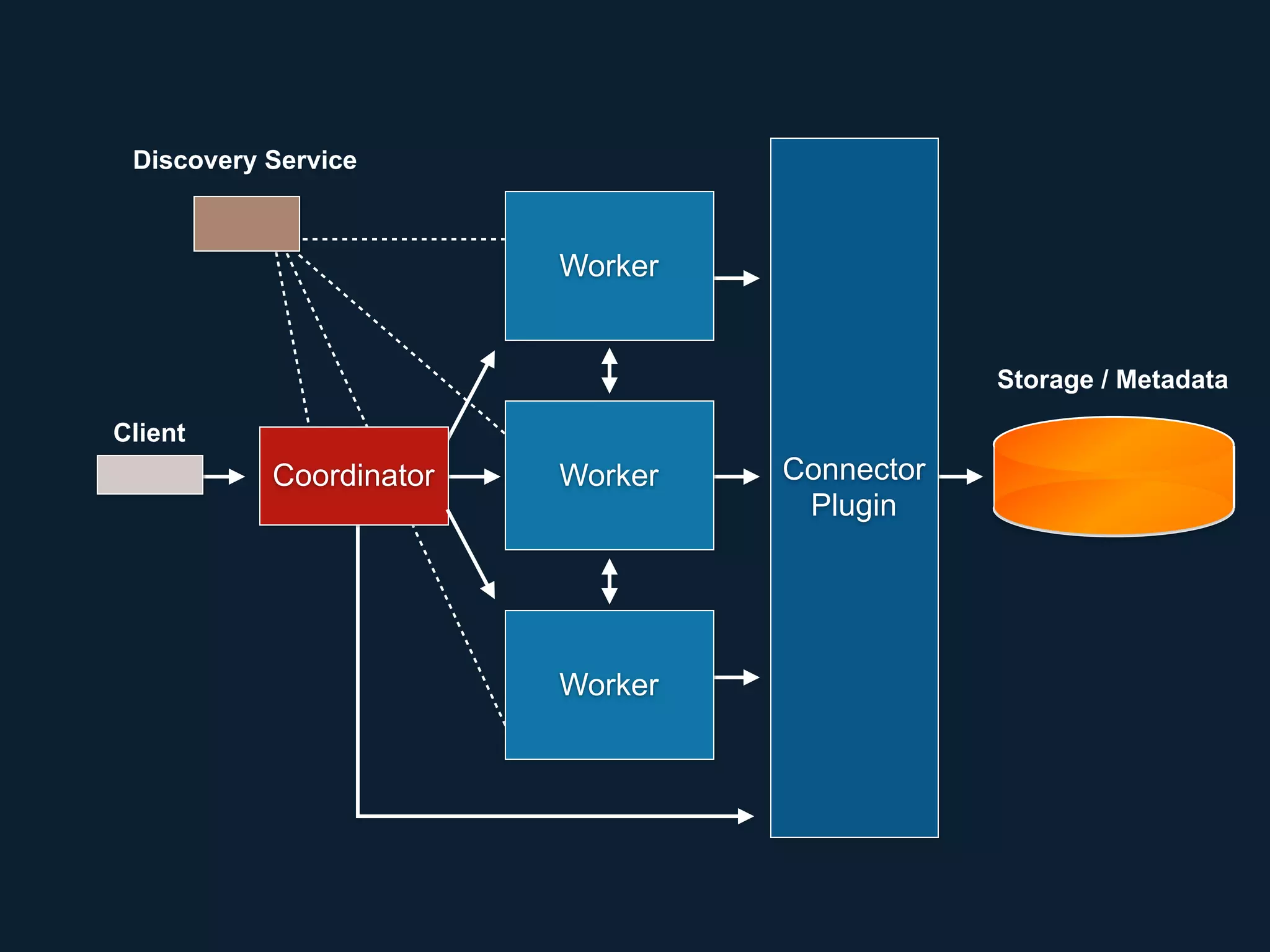

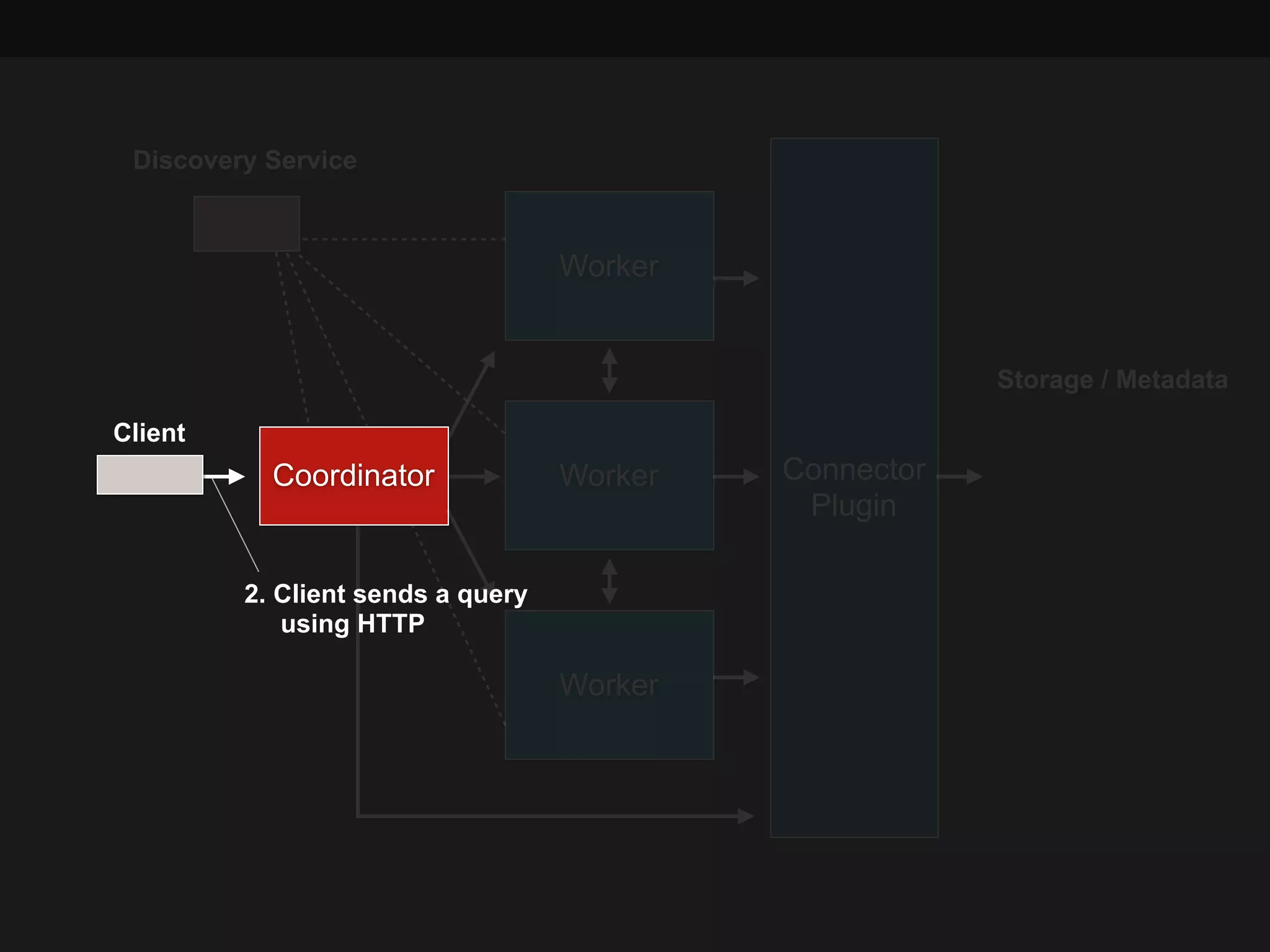
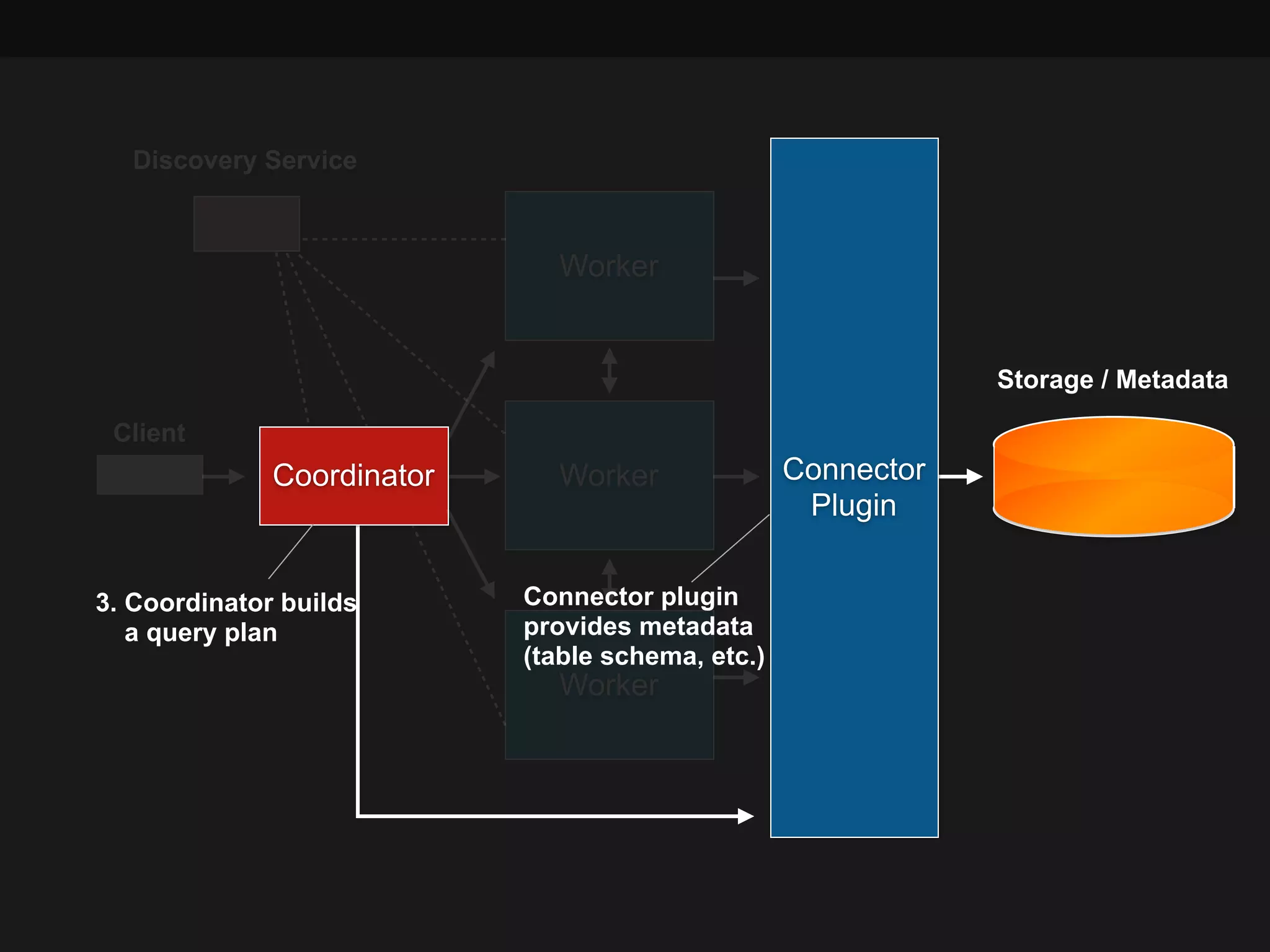
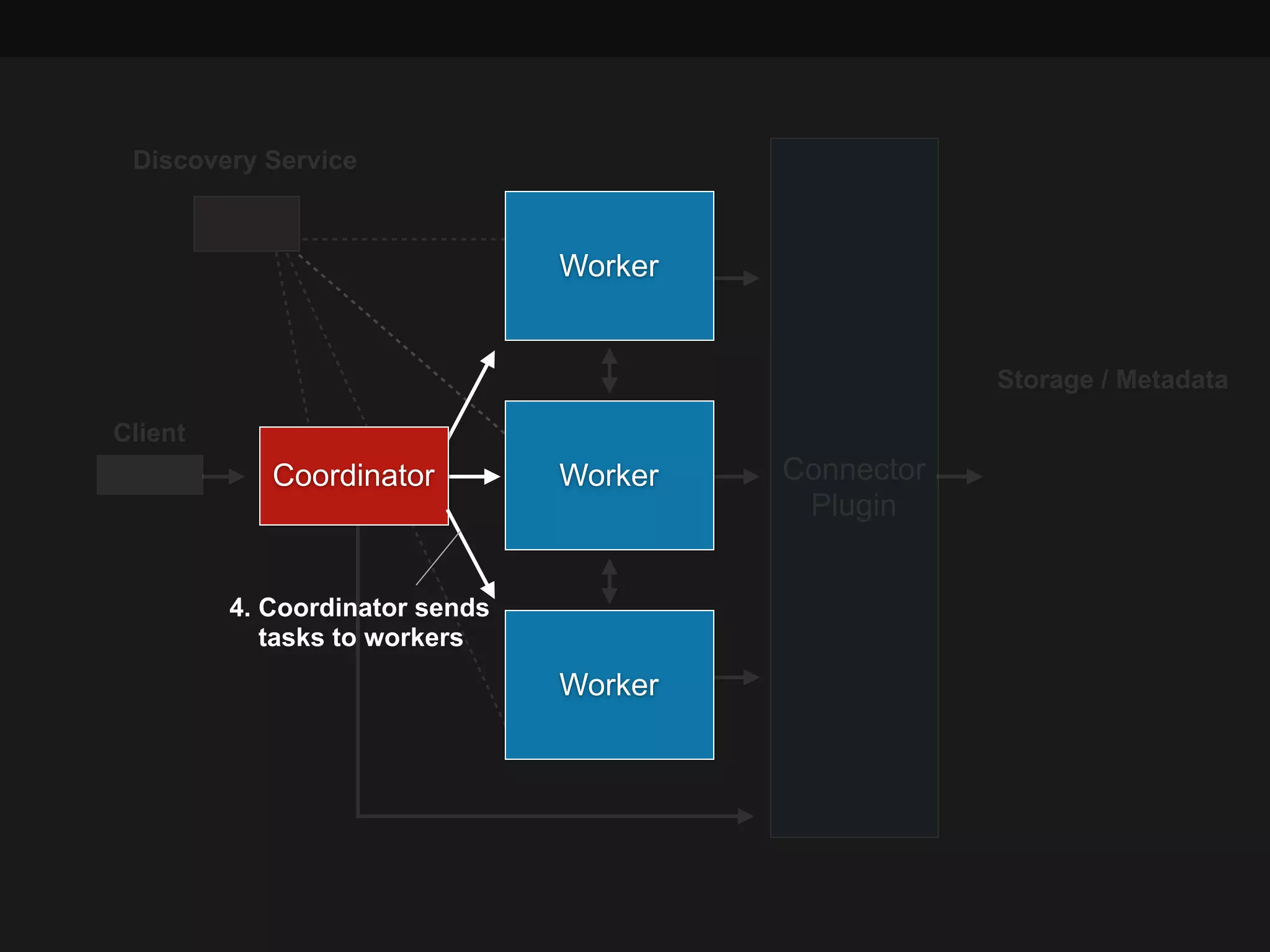
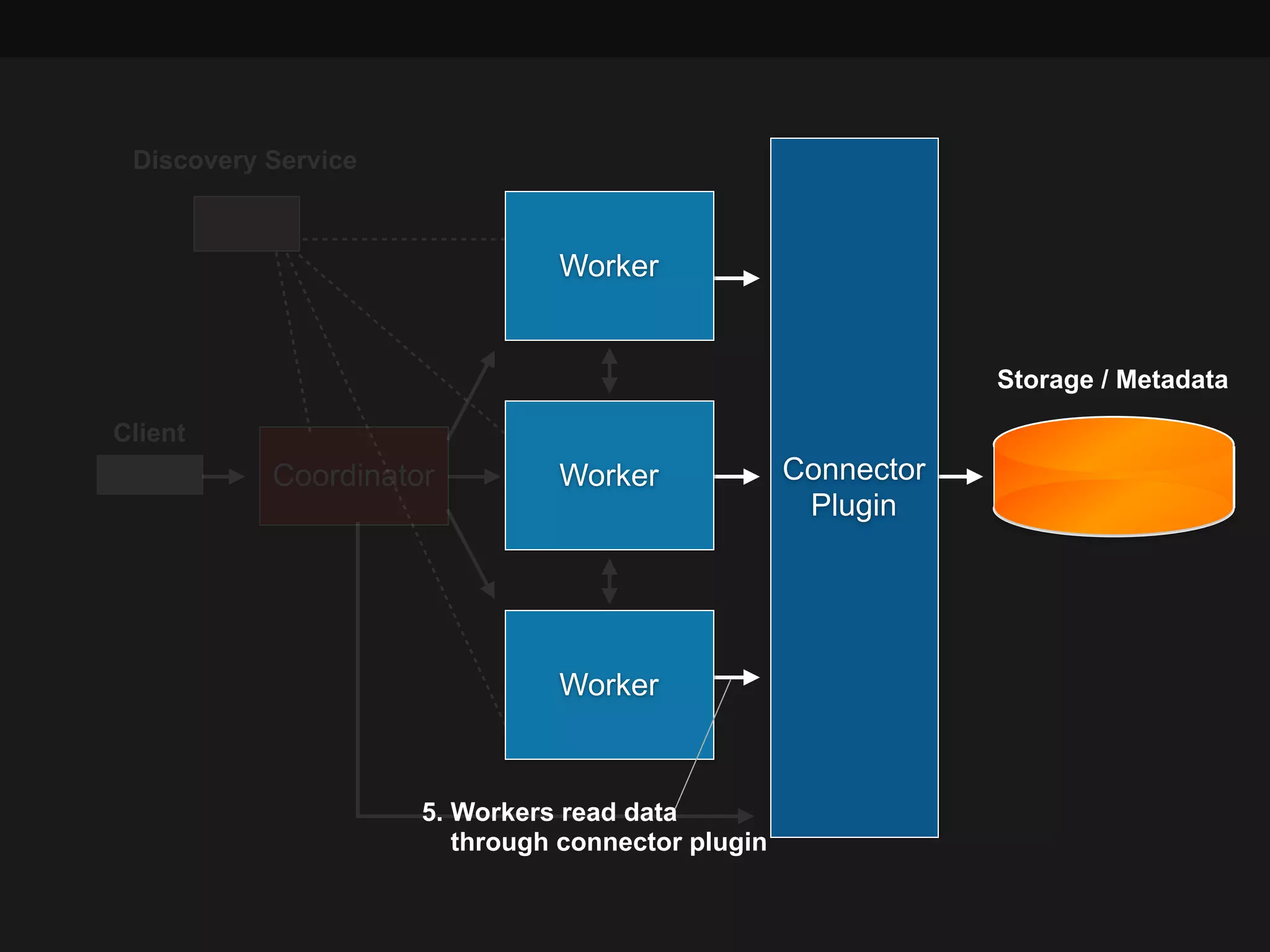
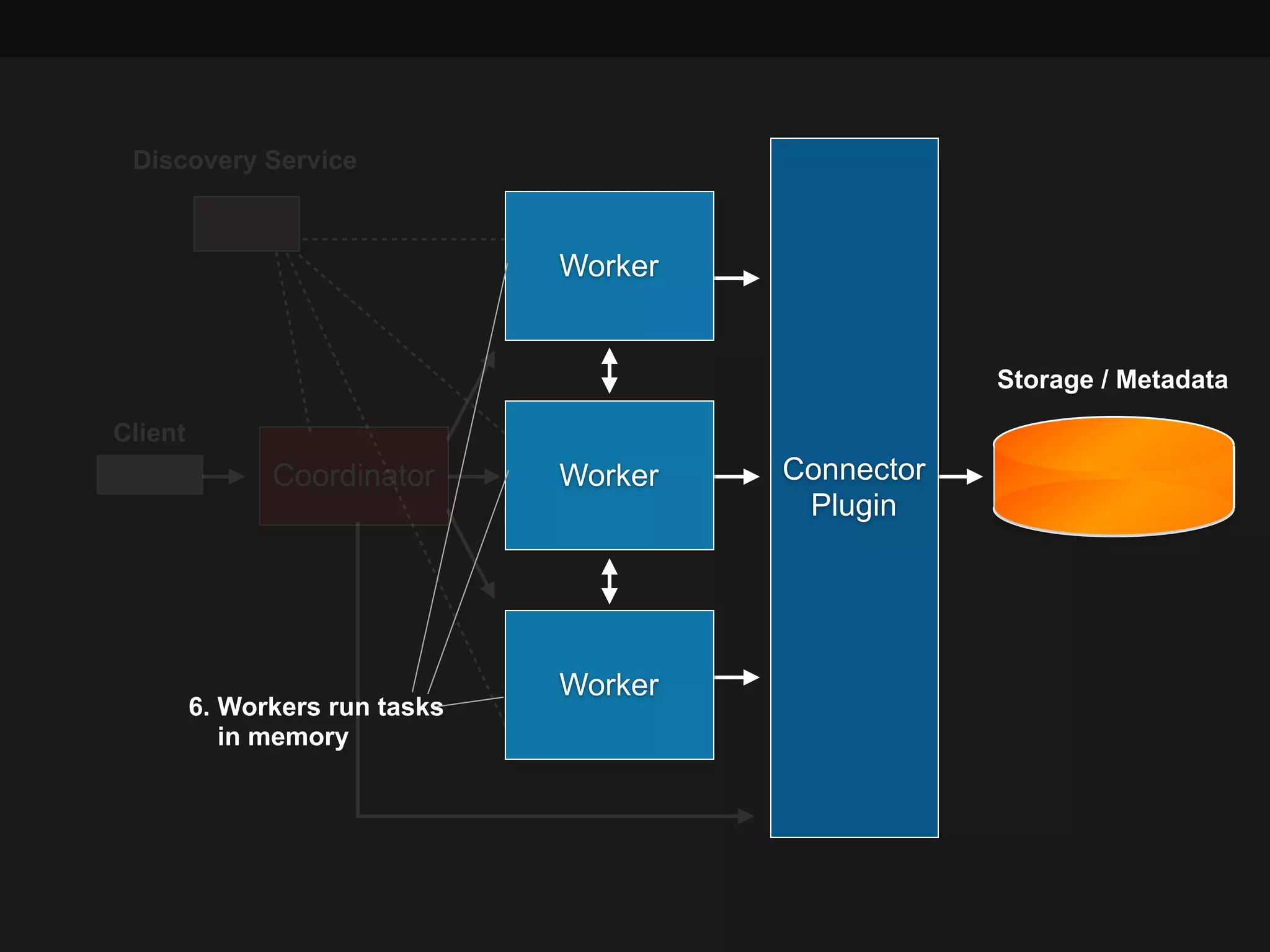
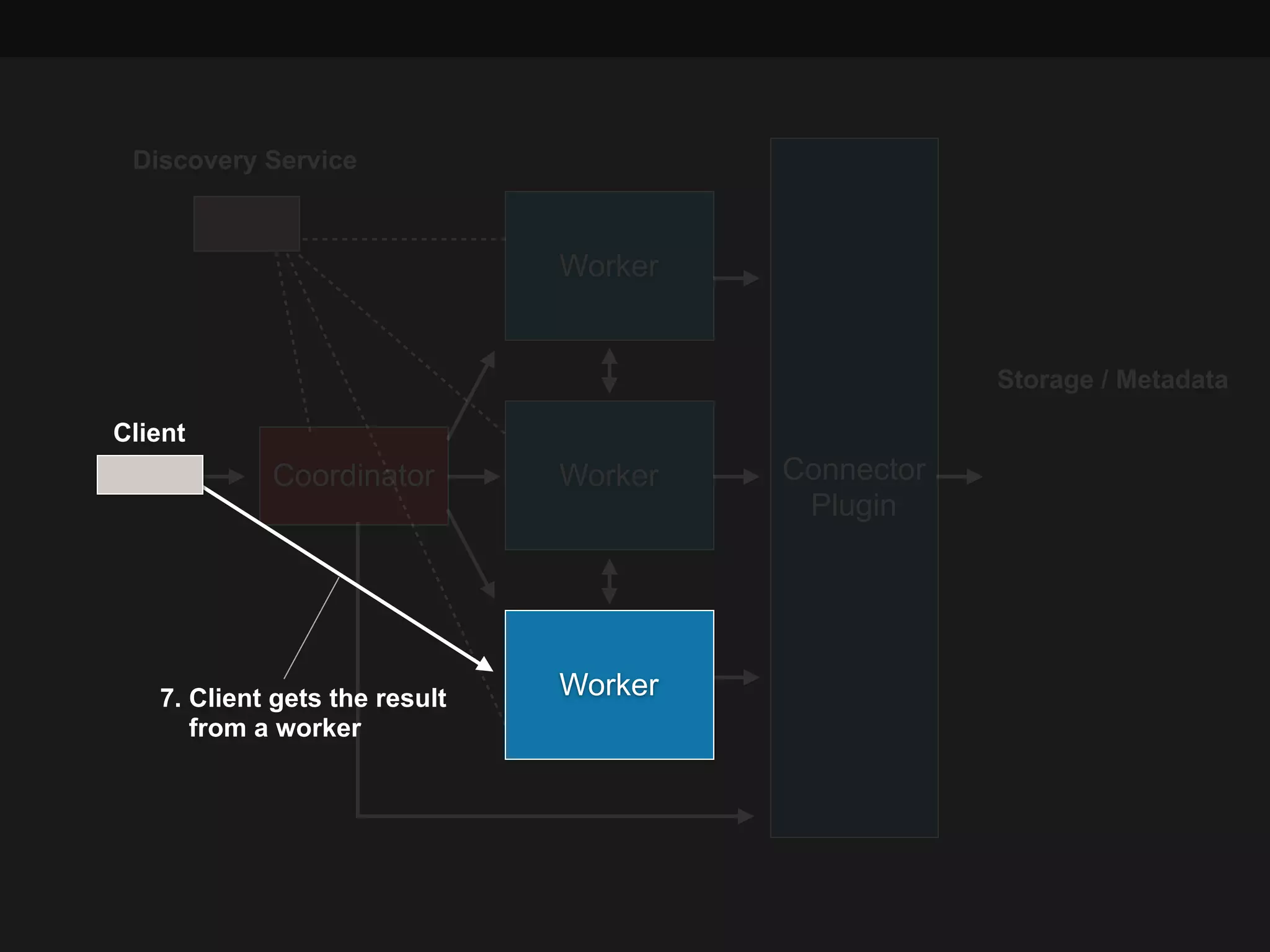
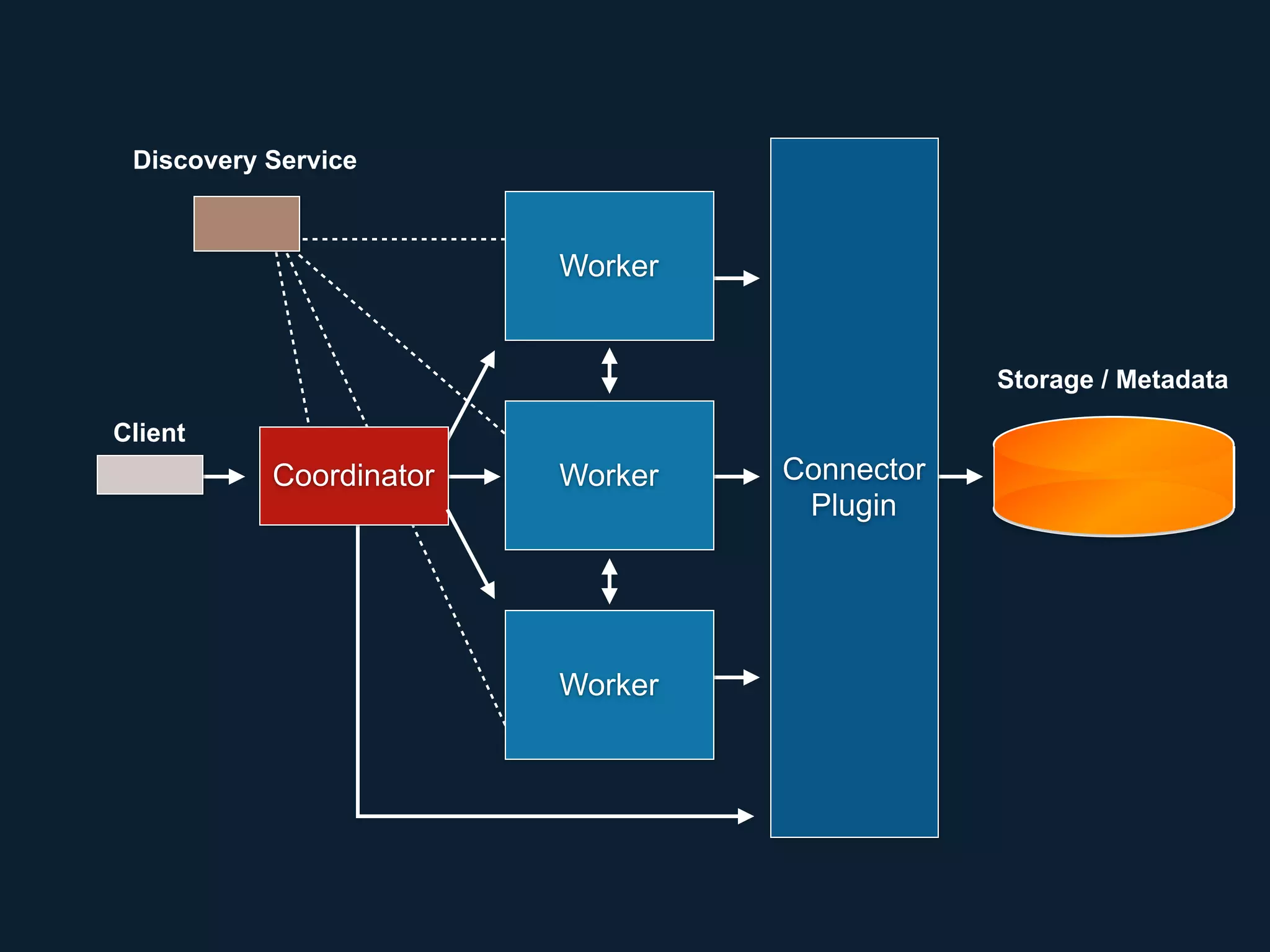
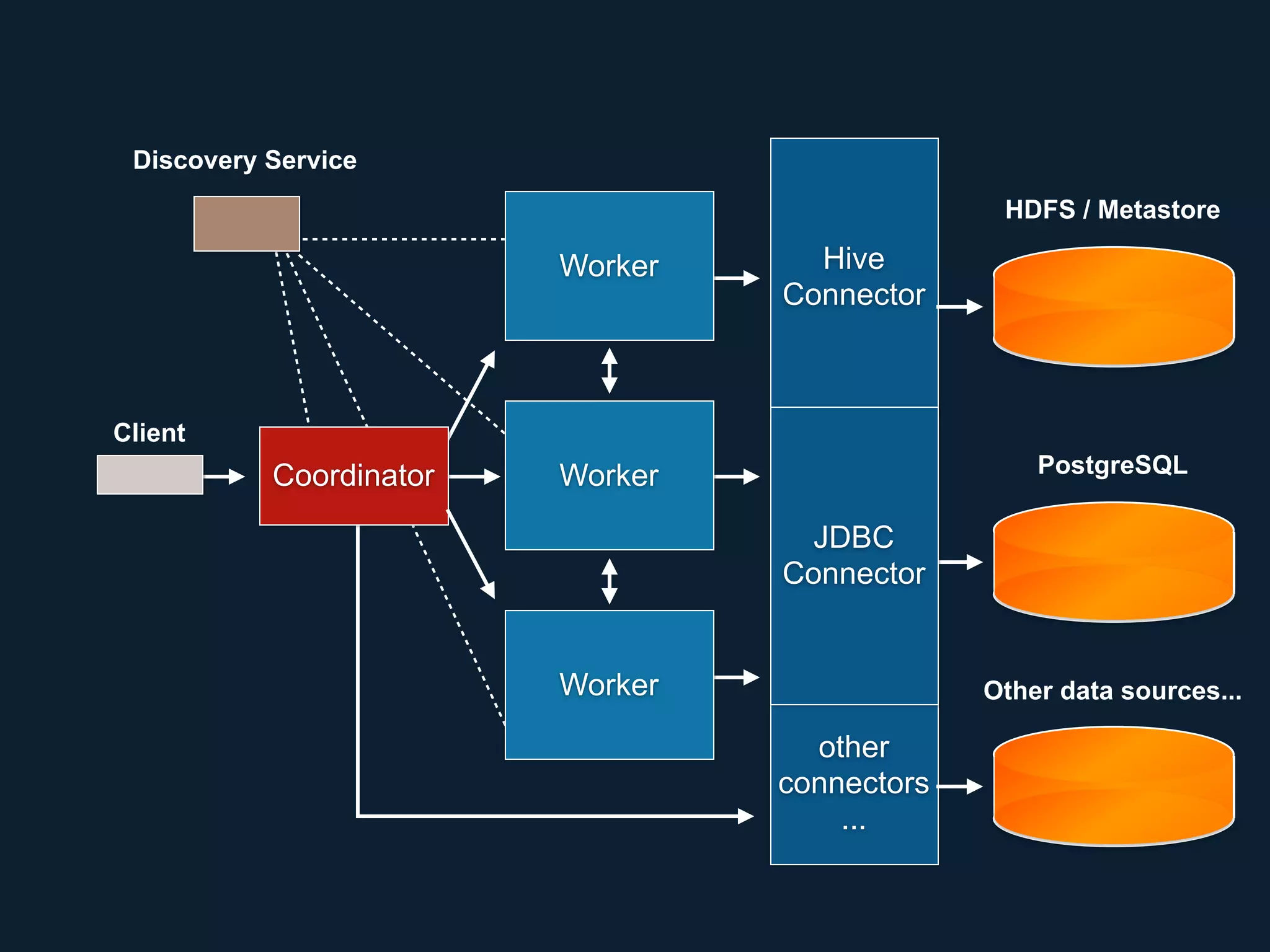
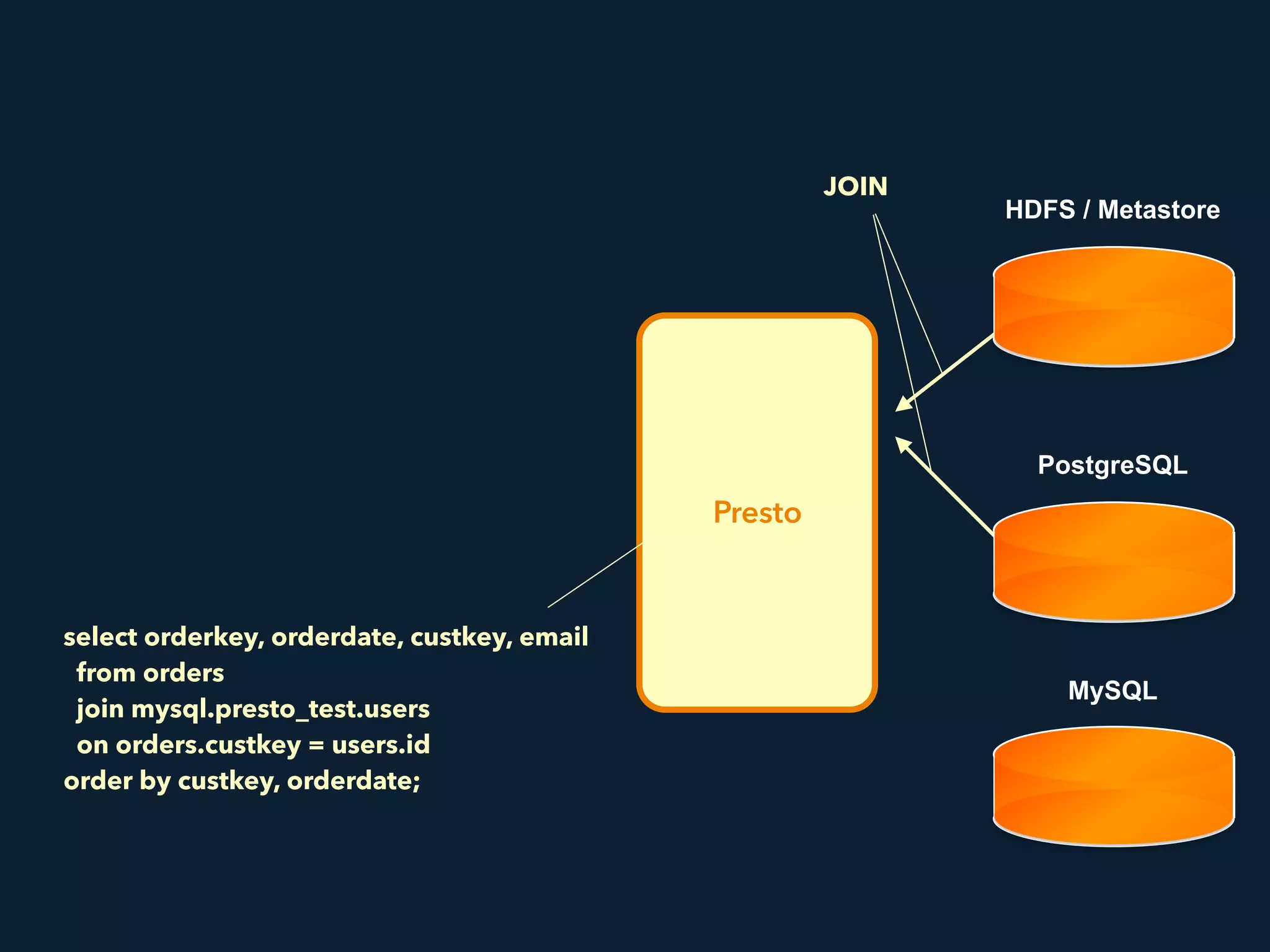
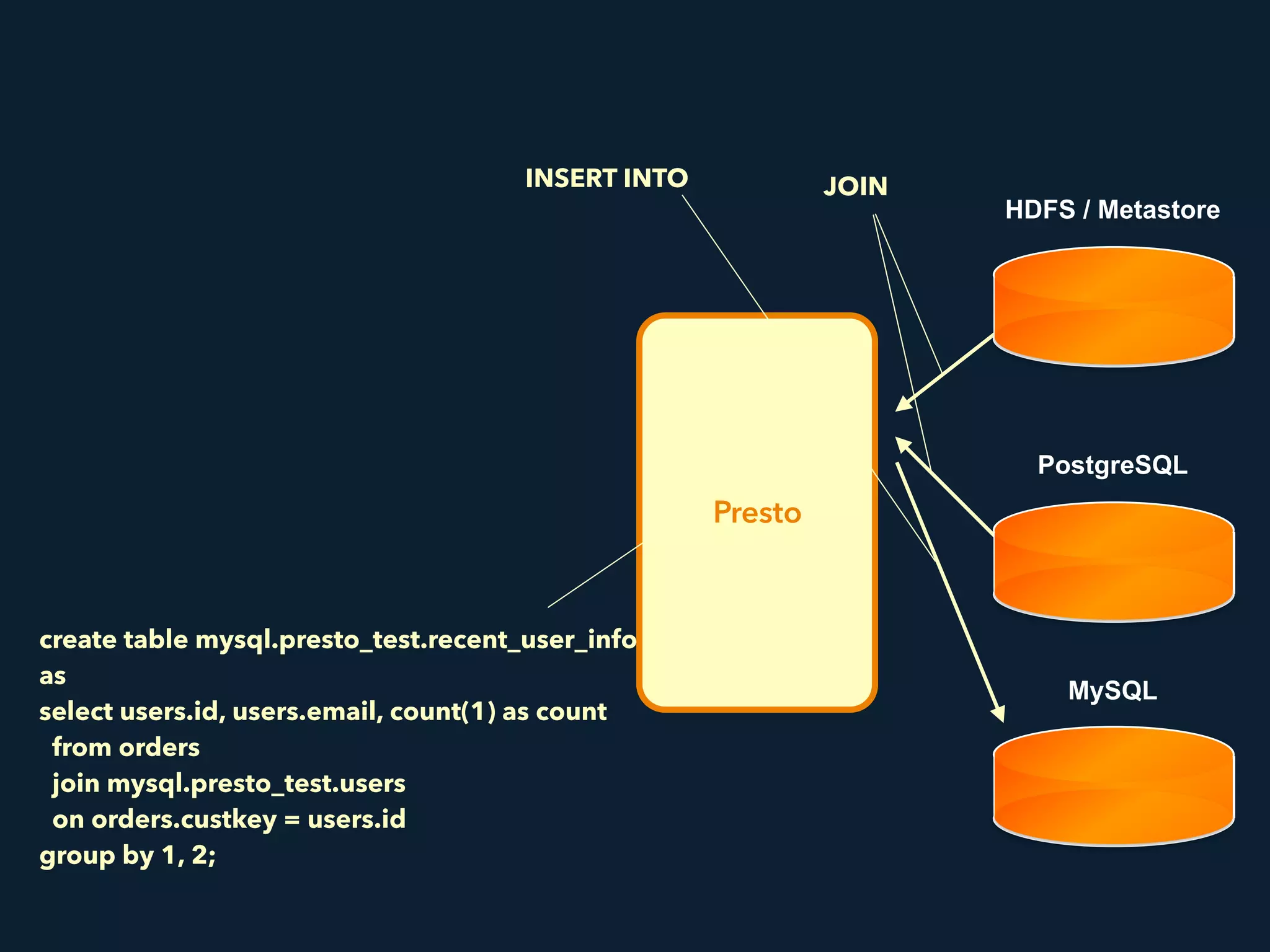




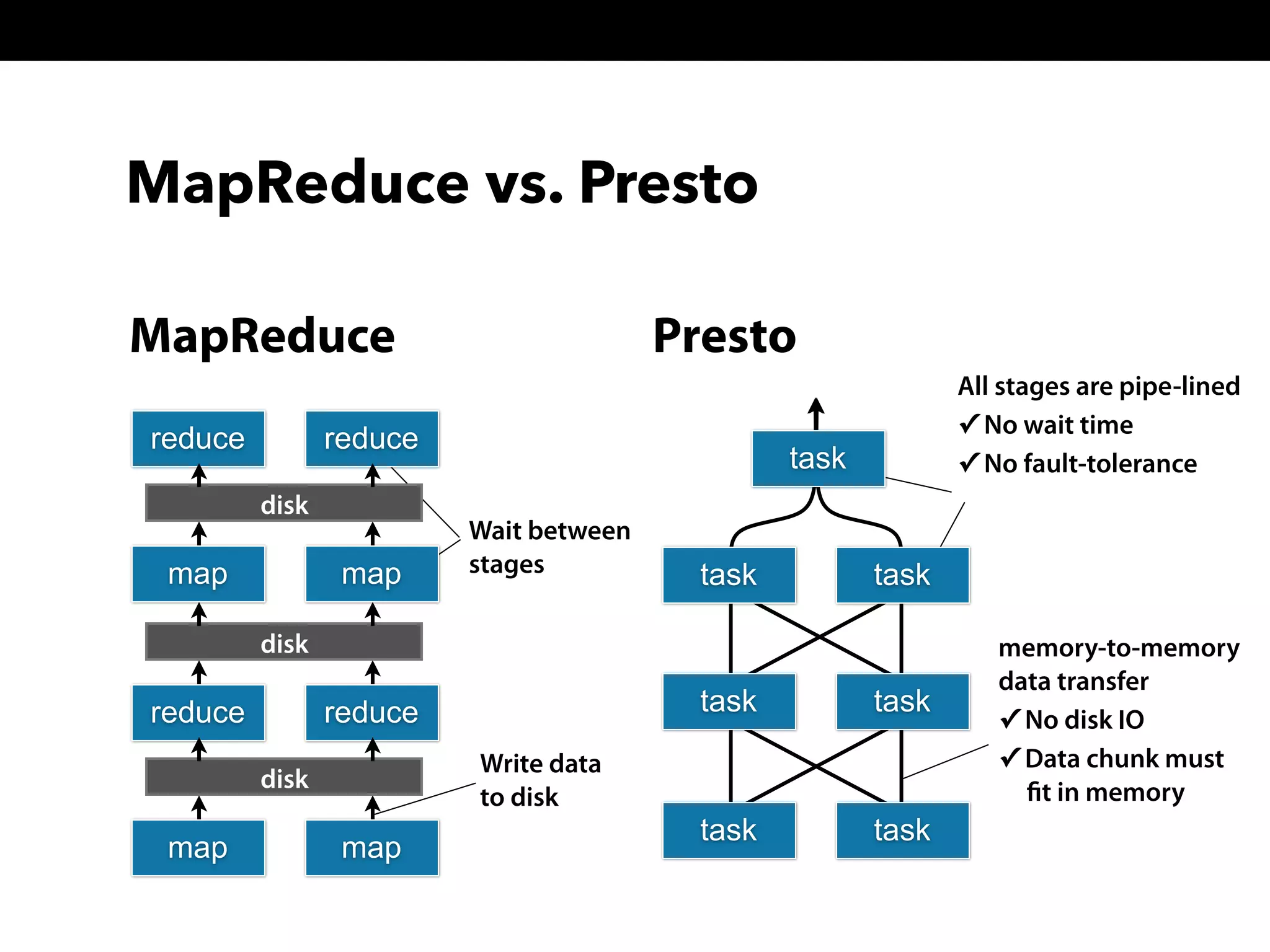
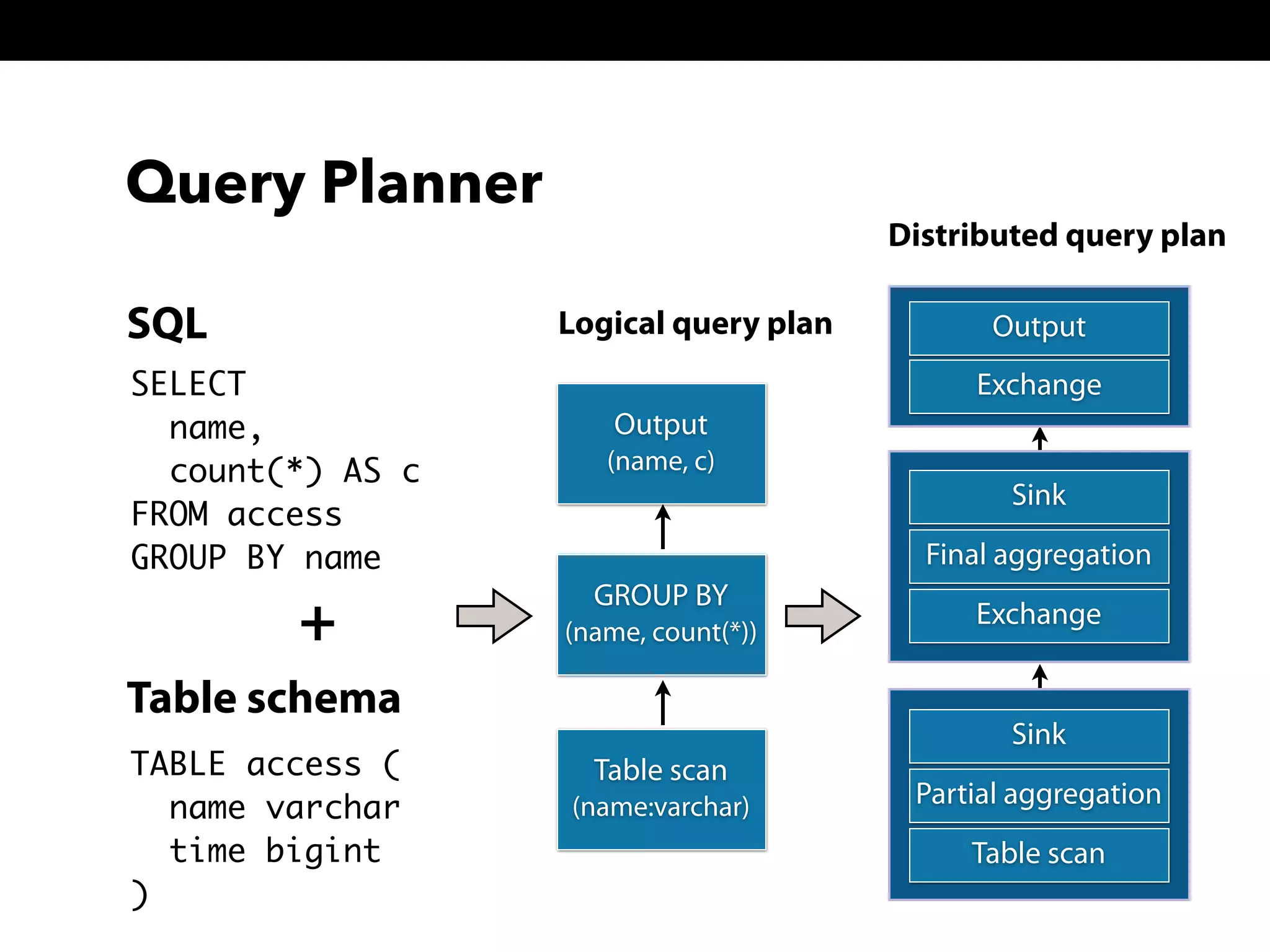
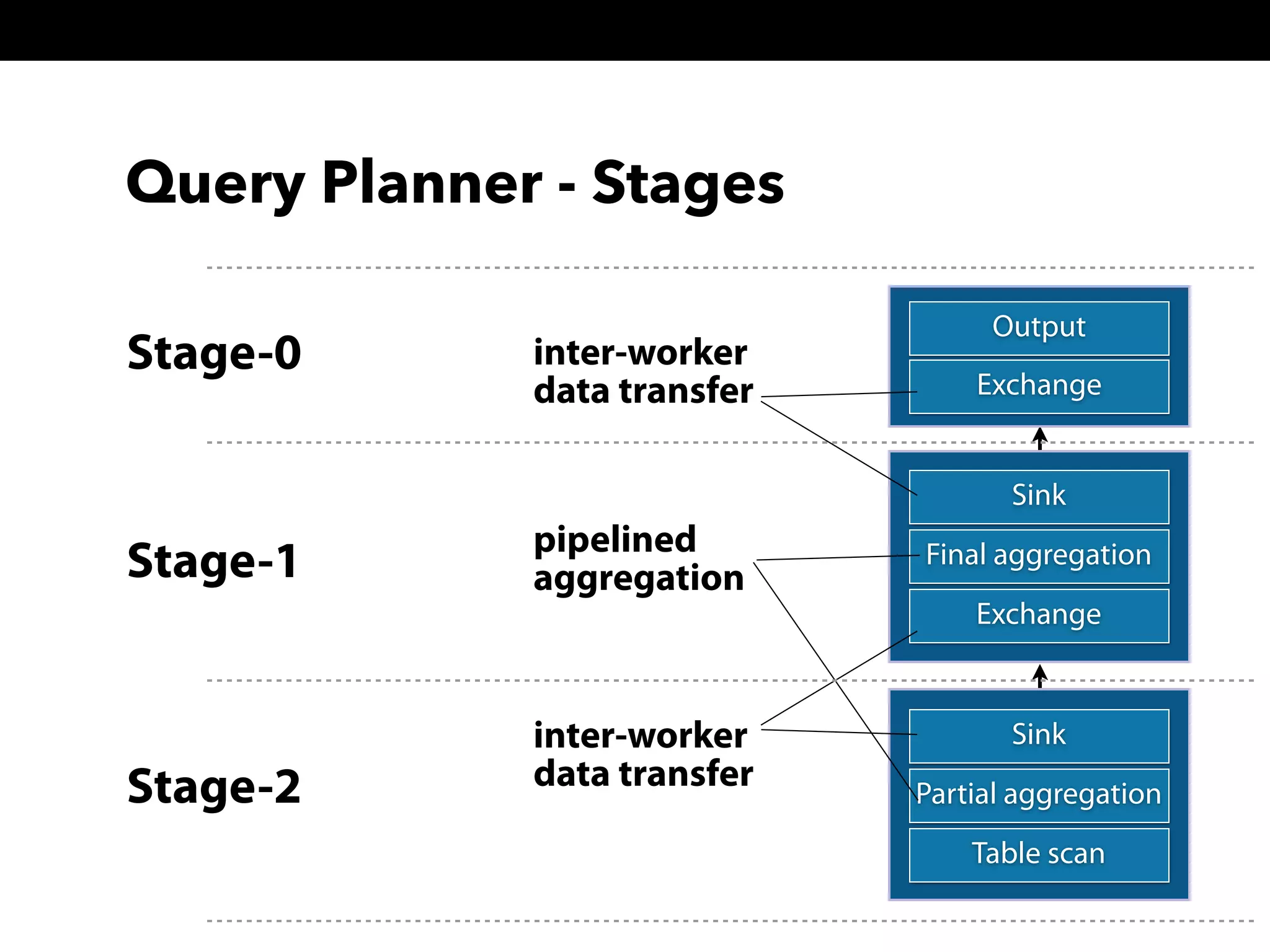
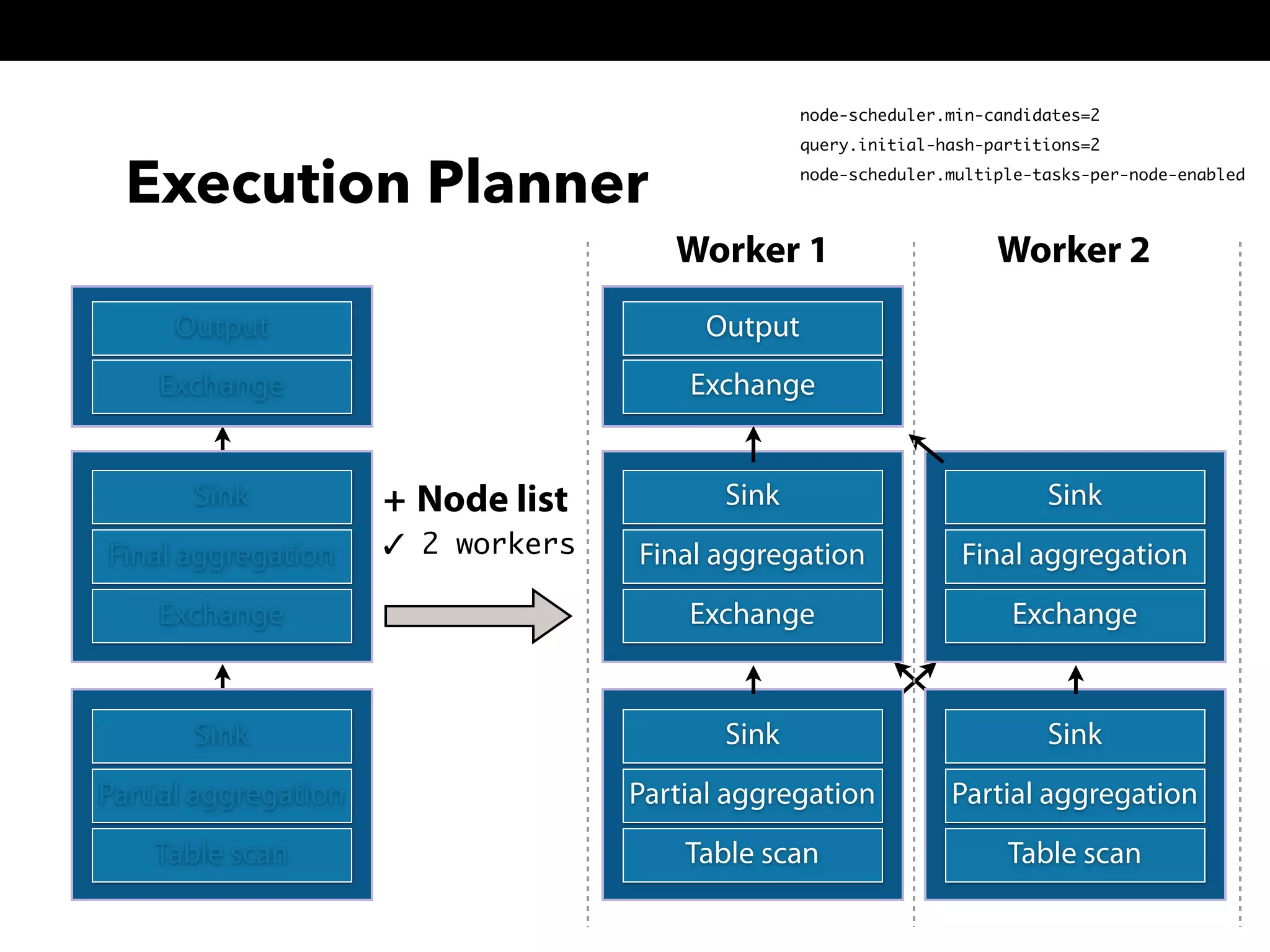
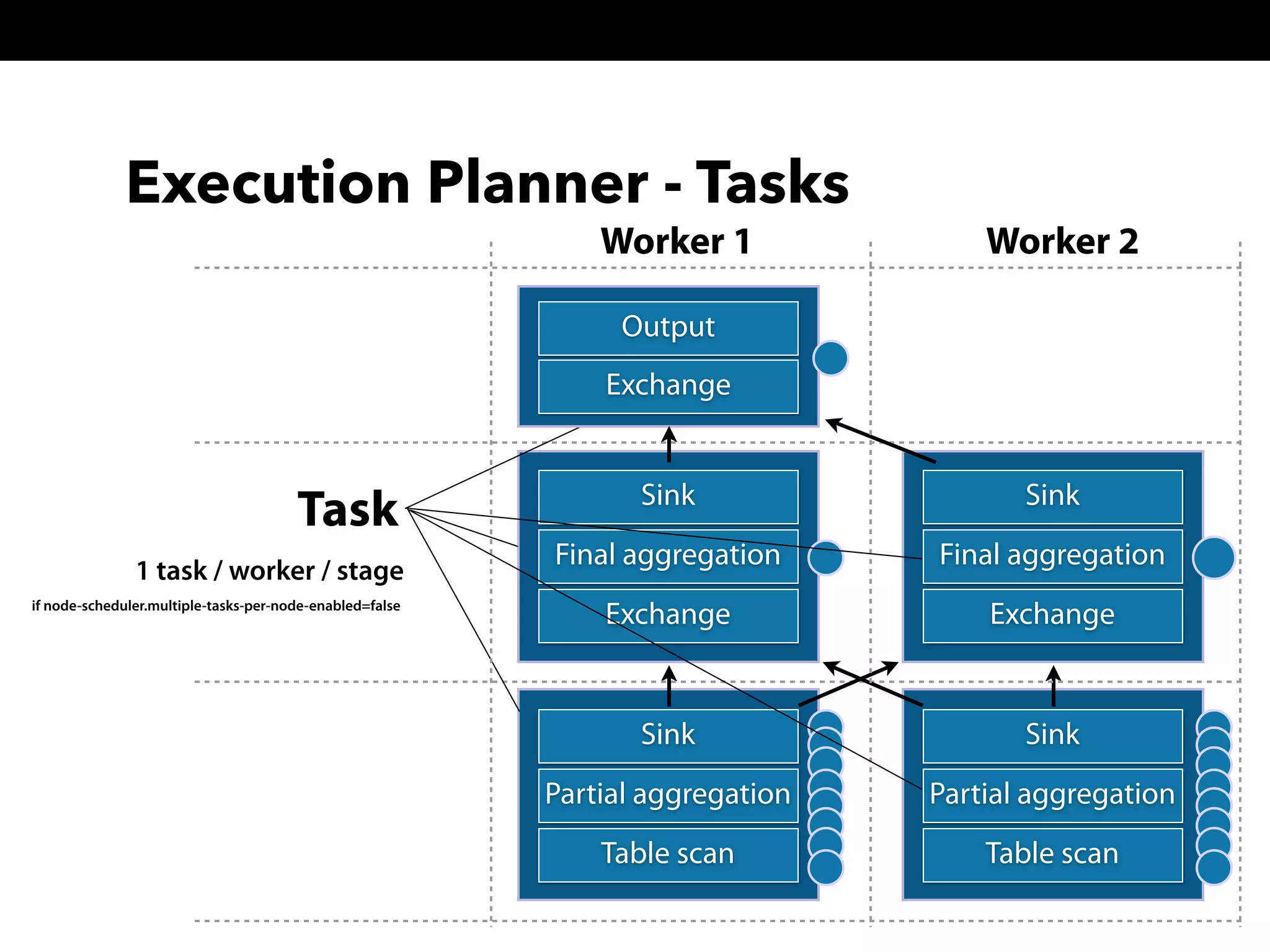
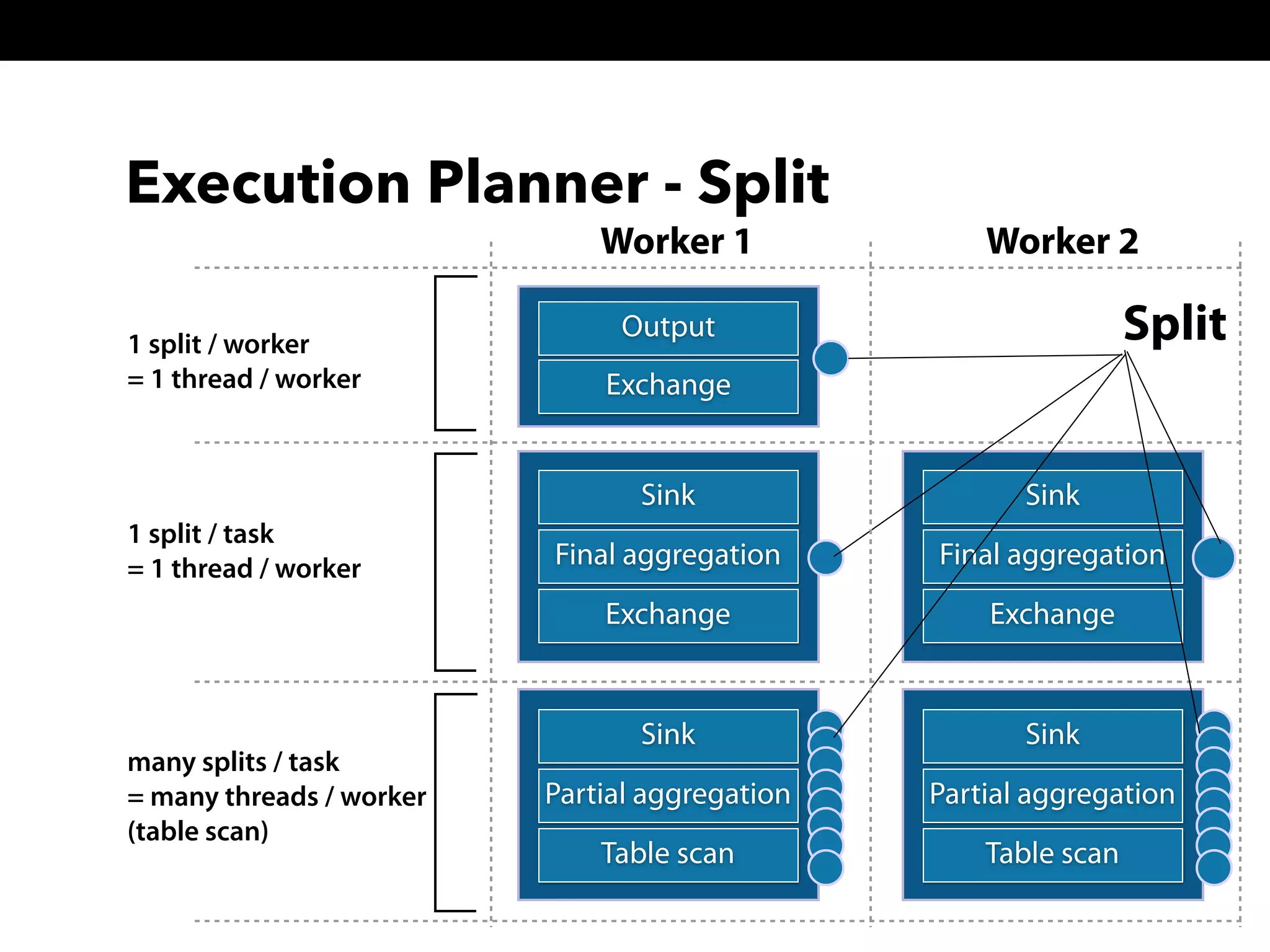


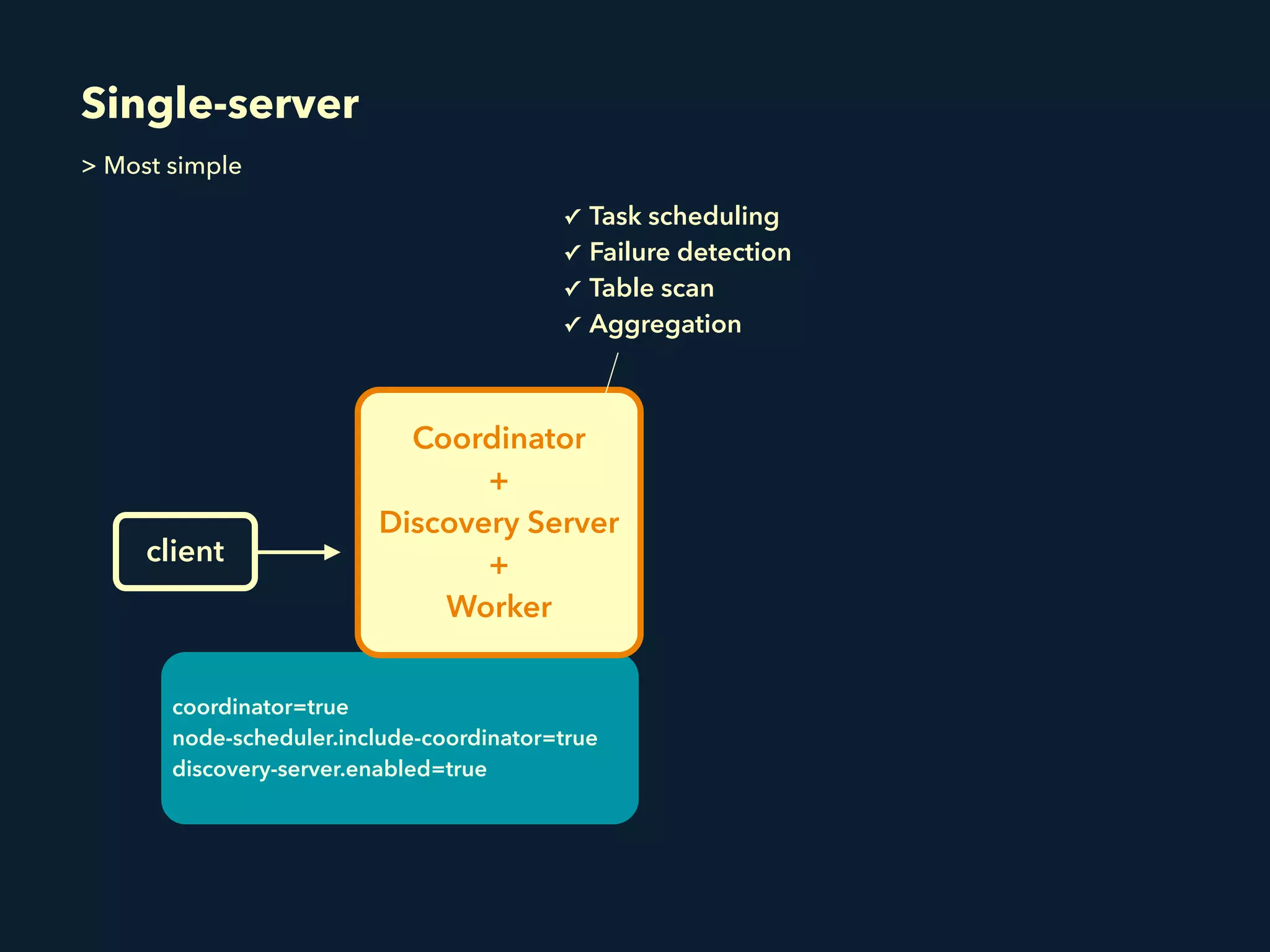
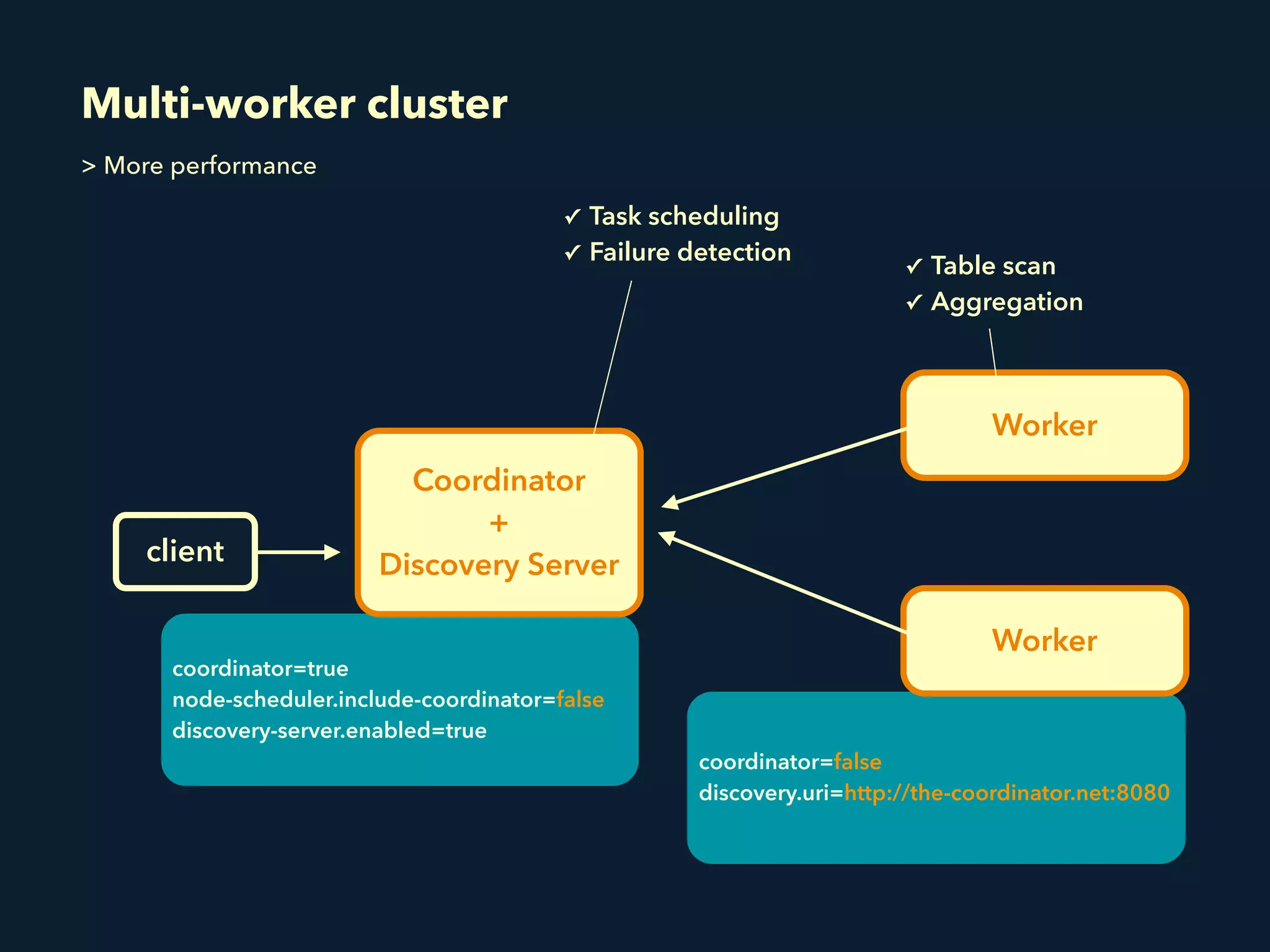
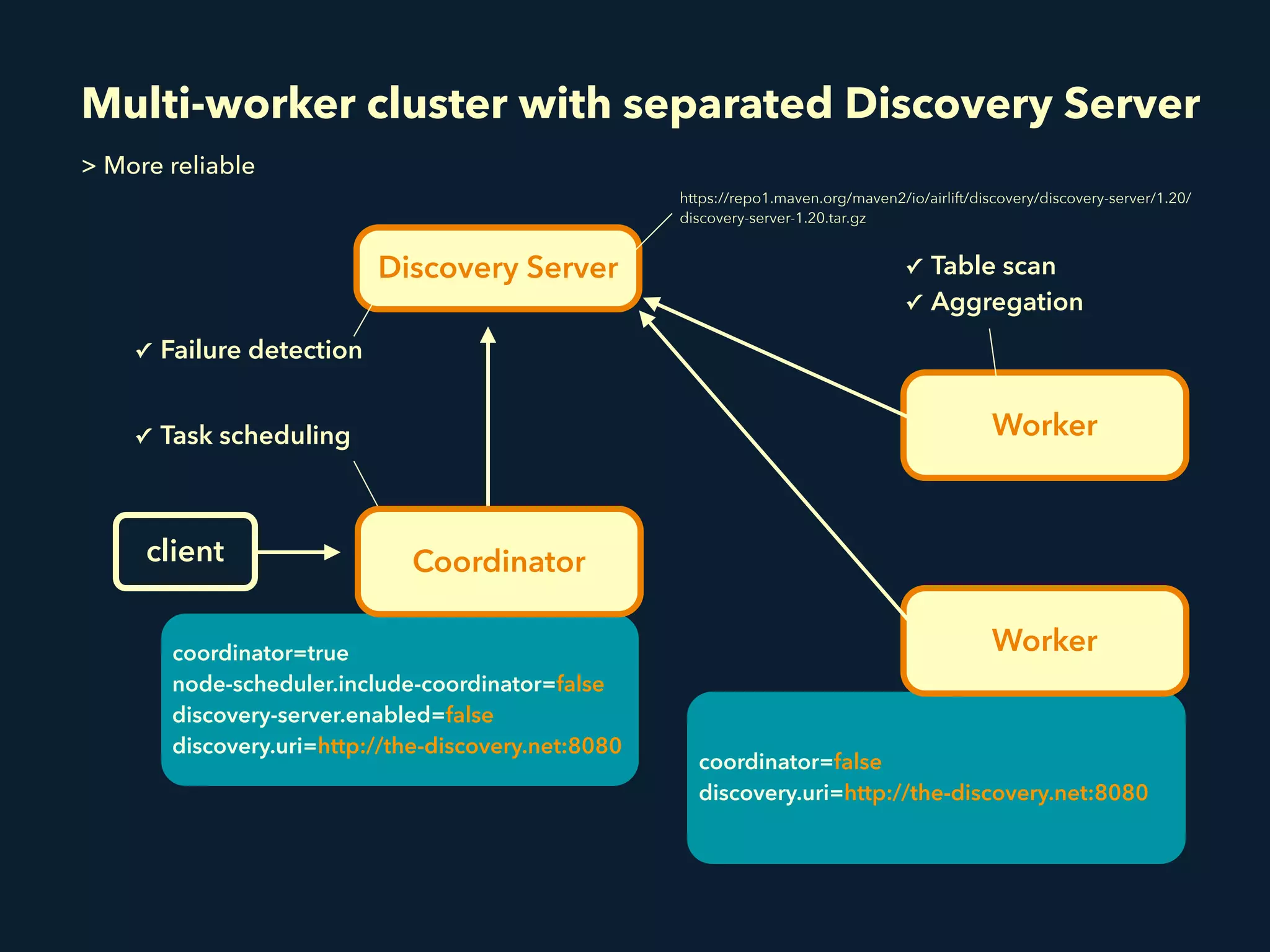
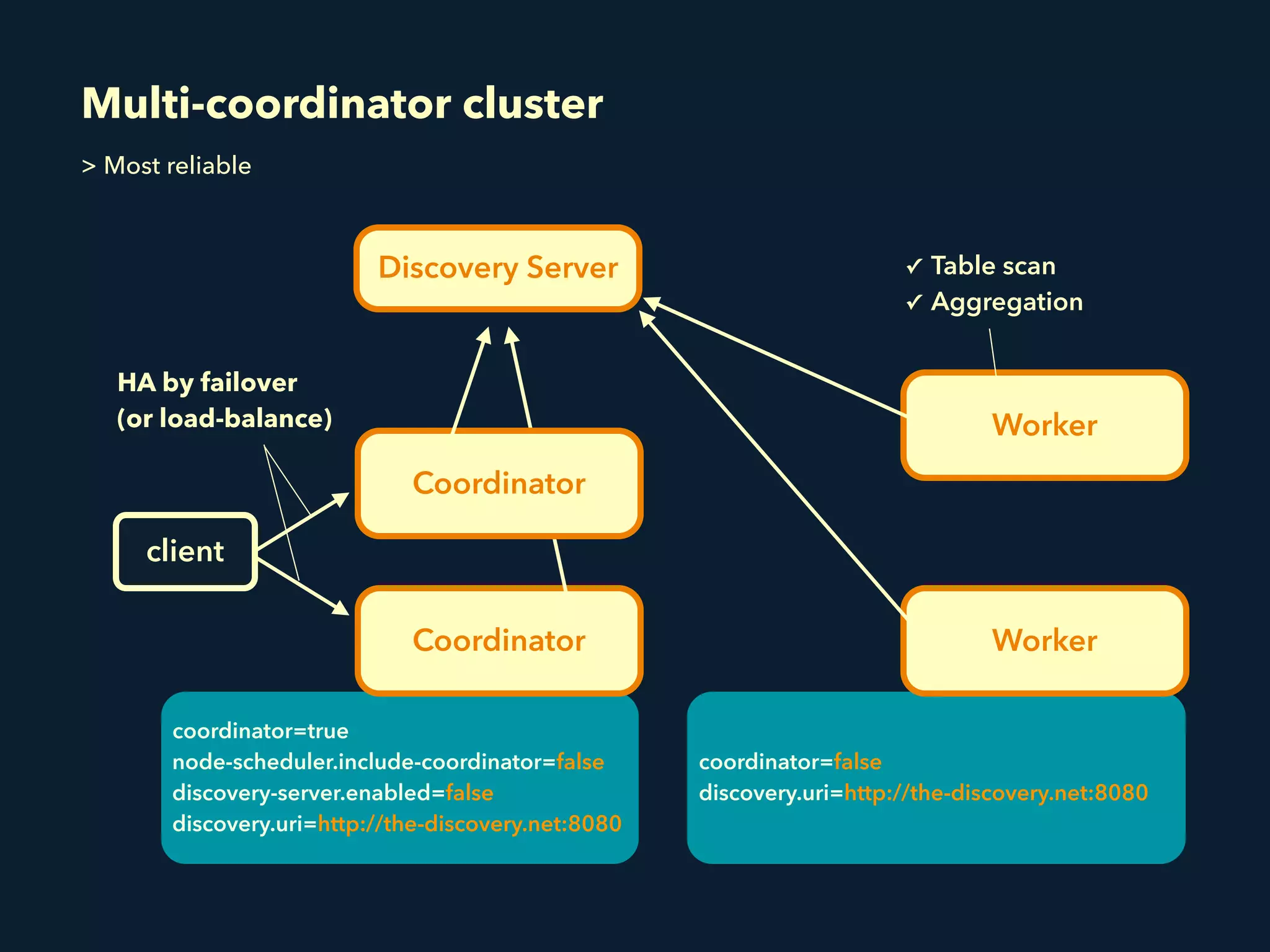



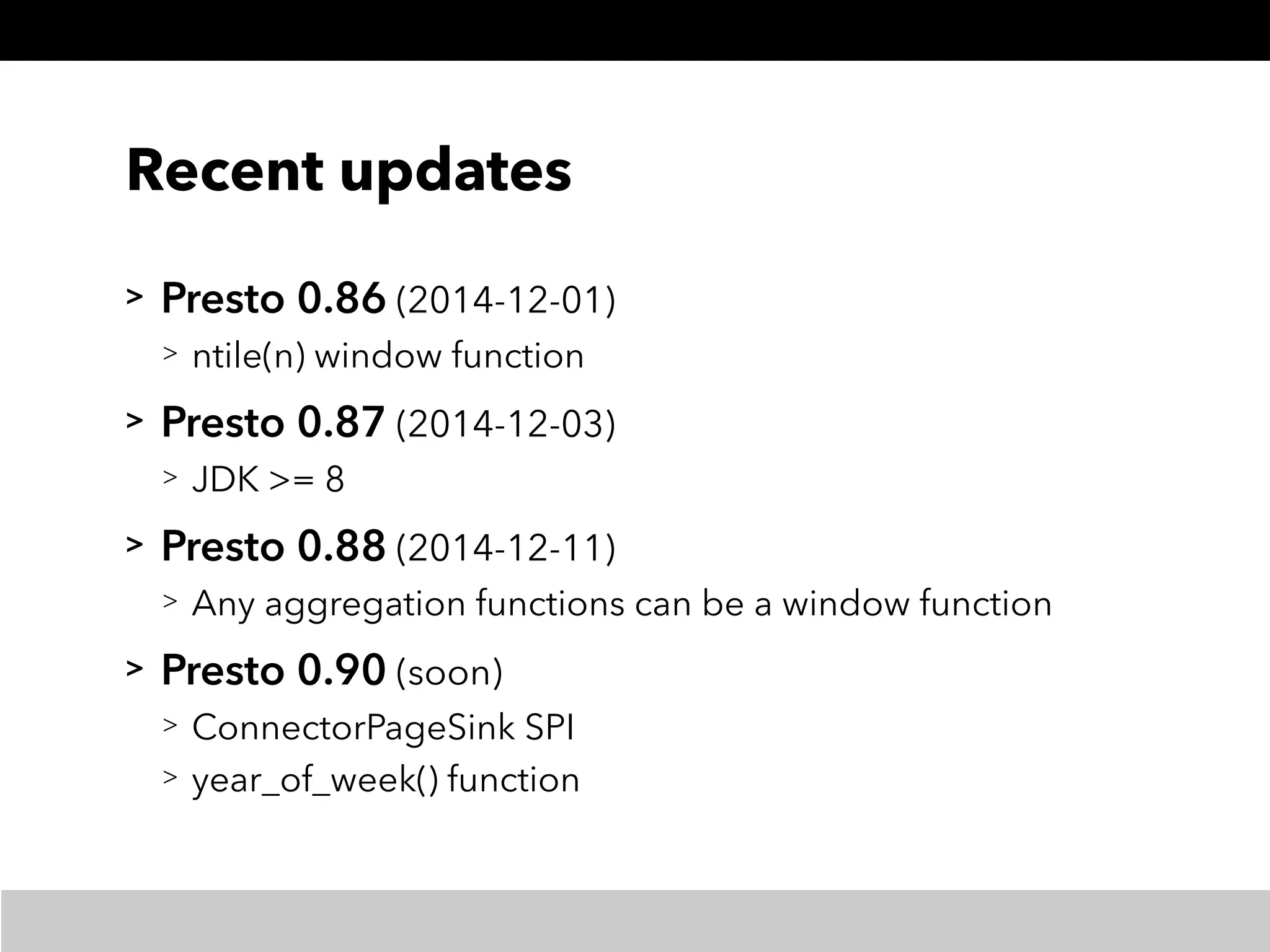




This document summarizes a presentation about Presto, an open source distributed SQL query engine. It discusses Presto's distributed and plug-in architecture, query planning process, and cluster configuration options. For architecture, it explains that Presto uses coordinators, workers, and connectors to distribute queries across data sources. For query planning, it shows how SQL queries are converted into logical and physical query plans with stages, tasks, and splits. For configuration, it reviews single-server, multi-worker, and multi-coordinator cluster topologies. It also provides an overview of Presto's recent updates.










































































































![bussiness communication[1].pptx work and stress](https://cdn.slidesharecdn.com/ss_thumbnails/bussinesscommunication1-251123030028-578a5e39-thumbnail.jpg?width=640&height=640&fit=bounds)
