Downloaded 1,472 times





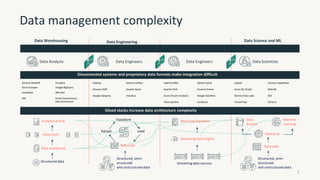

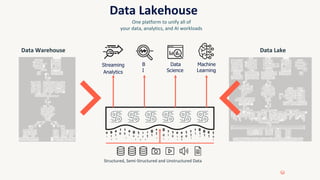
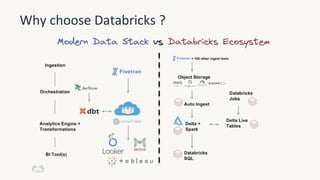




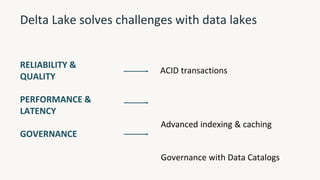
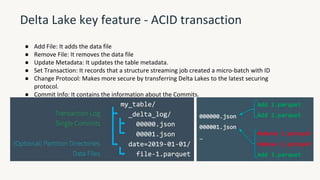
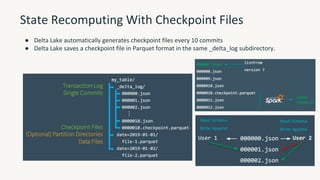
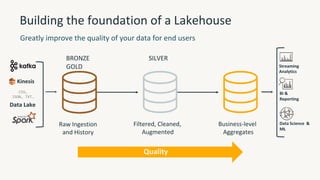

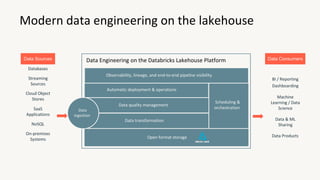

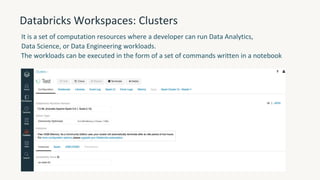



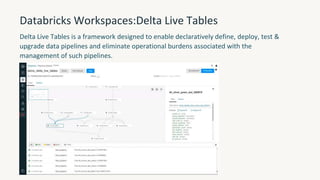



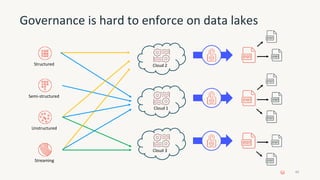


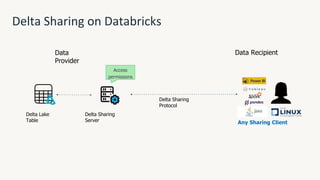

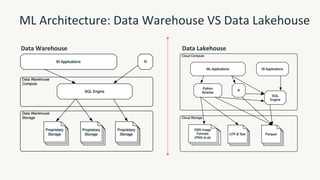
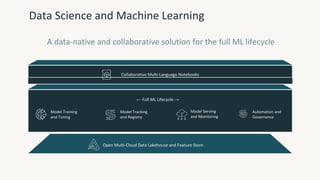

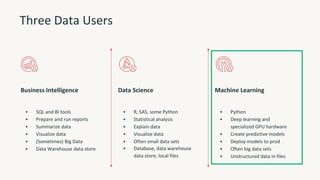


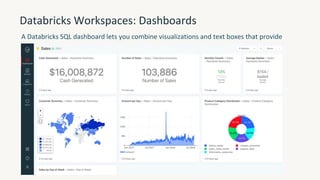




The document provides an overview of the Databricks platform, which offers a unified environment for data engineering, analytics, and AI. It describes how Databricks addresses the complexity of managing data across siloed systems by providing a single "data lakehouse" platform where all data and analytics workloads can be run. Key features highlighted include Delta Lake for ACID transactions on data lakes, auto loader for streaming data ingestion, notebooks for interactive coding, and governance tools to securely share and catalog data and models.
























































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)










