The document discusses various 2-D orthogonal and unitary transforms that can be used to represent digital images, including:
1. The discrete Fourier transform (DFT) which transforms an image into the frequency domain and has properties like energy conservation and fast computation via FFT.
2. The discrete cosine transform (DCT) which has good energy compaction properties and is close to the optimal Karhunen-Loeve transform.
3. The discrete sine transform (DST) which is real, symmetric, and orthogonal like the DCT.
4. The Hadamard transform which uses only ±1 values and has a fast computation, and the Haar transform which is a simpler wavelet transform





![Separable Unitary Transforms
• For an M×N rectangular image, the transform pair is:
V = AMUAN and U = A*M V A*TN
• For separable unitary matrix, image transforms can be written as:
VT = AUAT = A [AU]T
Which means transformation process can be performed by first
transforming each column of U and then transforming each row of
the result to obtain the rows of V.](https://image.slidesharecdn.com/03imagetransform-120321102432-phpapp01/85/03-image-transform-5-320.jpg)




![Properties of Unitary Transforms
1. Energy conservation and rotation
In a unitary transform:
v = Au ||v||2 = ||u||2
Thus a unitary transformation preserves the signal energy or the
length of the vector u in the N-dimensional vector space.
This means every unitary transformation is simply a rotation of the
vector u in the N-dimensional vector space. [Parseval Theorem!]
For 2-D unitary transformations, it can be proven that
N −1 N −1 N −1 N −1
∑∑ u ( m, n ) = ∑∑ v ( k , l )
2 2
m =0 n =0 k =0 l =0](https://image.slidesharecdn.com/03imagetransform-120321102432-phpapp01/85/03-image-transform-10-320.jpg)


![Properties of 2-D DFT
[The N2×N2 matrix F represents the N×N 2-D unitary DFT]
• Symmetric and unitary
F T = F and F –1 = F *
• Periodic extensions
v(k + N, l + N) = v(k, l) ∀k, l
u(m + N, n+N) = u(m, n) ∀m, n
• Sampled Fourier spectrum
If u ( m, n ) = u ( m, n ) , 0 ≤ m, n ≤ N − 1 ,and u ( m, n ) = 0 otherwise,
then:
% 2π k , 2π l = DFT {u ( m, n )} = v ( k , lx )
U
N N
where %
U (ω1 ,ω 2 ) is the Fourier transform of u ( m, n )
• Fast transform
Since 2-D DFT is separable, it is equivalent to 2N 1-D unitary DFTs, each of
which can be performed in O(N log2N) via the FFT. Hence the total number of
operations is O(N2 log2N).](https://image.slidesharecdn.com/03imagetransform-120321102432-phpapp01/85/03-image-transform-13-320.jpg)








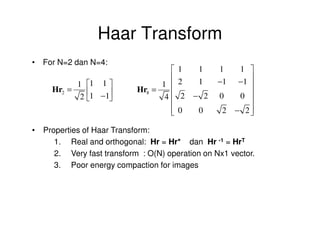
![Haar Transform
• The Haar functions hk(x) are defined on a continuous interval,
x ∈[-1,1] and for k = 0, 1, …, N-1 where N=2n.
• The integer k can be uniquely decomposed as: k = 2p + q -1, where
0≤ p ≤n-1; q=0,1 for p=0 and 1≤ q ≤2p for p≠0.
• For Example, when N = 4 (or n=2) we have
k 0 1 2 3
p 0 0 1 1
q 0 1 1 2
Representing k by (p,q), the Haar functions are defined as:
1
h0 ( x ) ≡ h0,0 ( x ) = , x ∈ [ 0,1]
N
p2 q −1 q −1 2
2 , ≤x<
2p 2p
1 p 2 q −1 2 q
hk ( x ) ≡ hp ,q ( x ) = −2 , ≤x< p
N 2p 2
0 , daerah lain untuk x ∈ [ 0,1]
](https://image.slidesharecdn.com/03imagetransform-120321102432-phpapp01/85/03-image-transform-22-320.jpg)