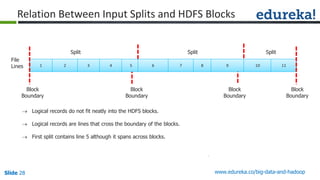
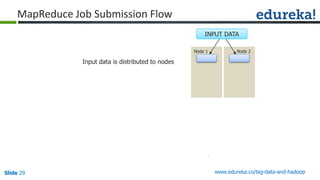
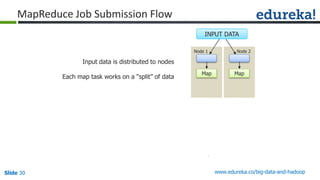
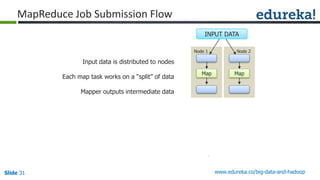
Download as PDF, PPTX




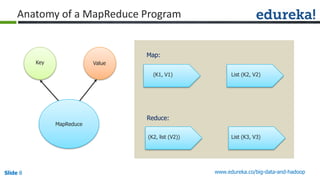




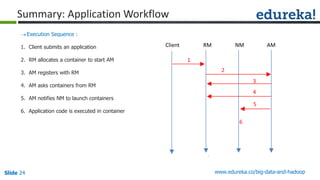
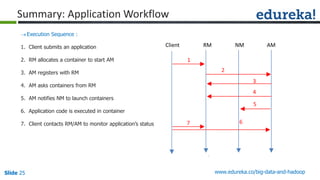
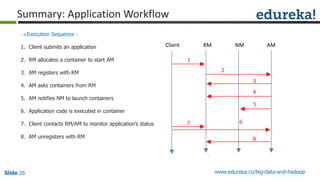
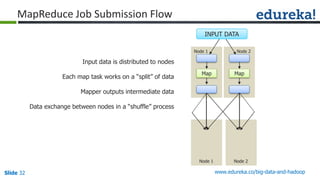
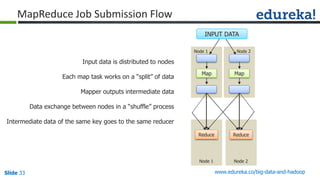
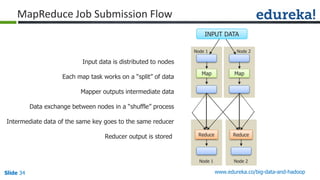
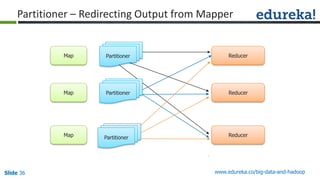
![Slide 35 www.edureka.co/big-data-and-hadoop
Combiner
Combiner
Reducer
(B,1)
(C,1)
(D,1)
(E,1)
(D,1)
(B,1)
(D,1)
(A,1)
(A,1)
(C,1)
(B,1)
(D,1)
(B,2)
(C,1)
(D,2)
(E,1)
(D,2)
(A,2)
(C,1)
(B,1)
(A, [2])
(B, [2,1])
(C, [1,1])
(D, [2,2])
(E, [1])
(A,2)
(B,3)
(C,2)
(D,4)
(E,1)
Shuffle
CombinerMapper
Mapper
B
C
D
E
D
B
D
A
A
C
B
D
Block1Block2](https://image.slidesharecdn.com/hadoopmr-150613152227-lva1-app6891/85/XML-Parsing-with-Map-Reduce-35-320.jpg)
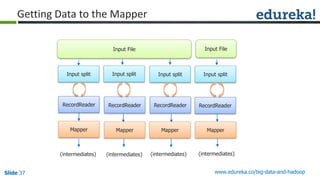
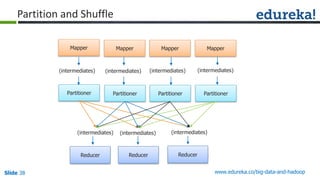

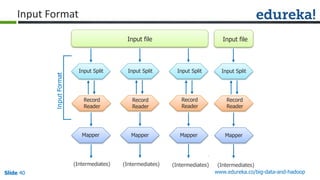
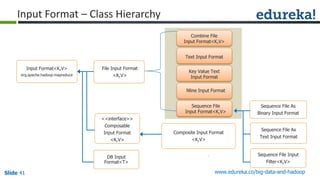



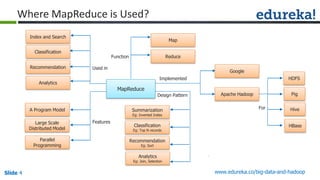
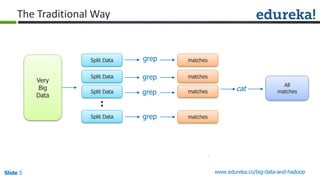
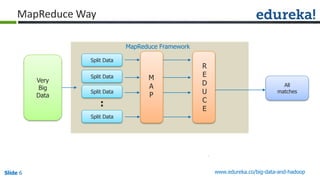
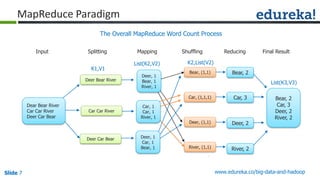
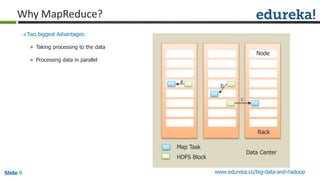
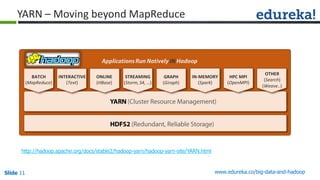
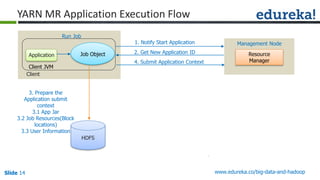
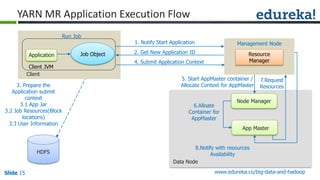
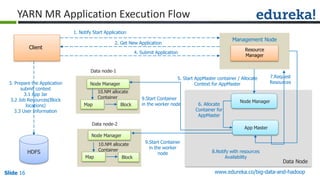
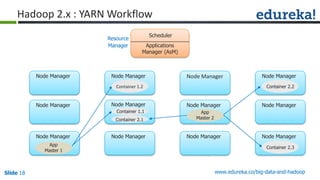
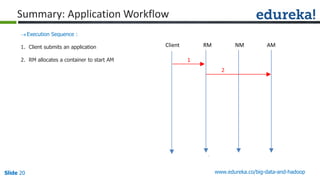
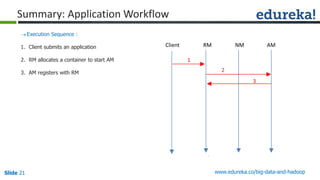
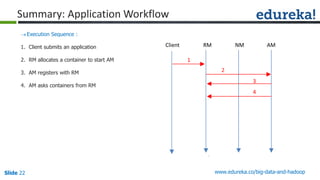
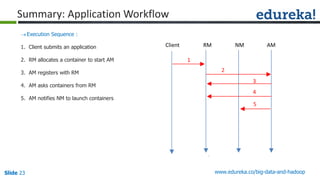
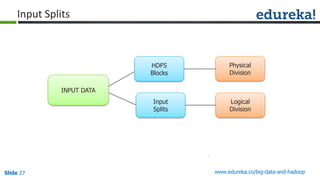
The document outlines the objectives and components of Hadoop's MapReduce framework, emphasizing its use cases, particularly in weather forecasting and healthcare. It compares traditional data processing methods with the MapReduce model, detailing the execution flow and architecture within Hadoop 2.x, including resource management through YARN. Key concepts such as input splits, the role of the application master, and the overall workflow of MapReduce job execution are also discussed.











































































































