Downloaded 555 times














![Driver Class
package ambuj.com.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCountDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "WordCount");
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new WordCountDriver(), args);
}
}](https://image.slidesharecdn.com/basicsofbigdataanalyticshadoop-140823074204-phpapp01/85/Basics-of-big-data-analytics-hadoop-30-320.jpg)
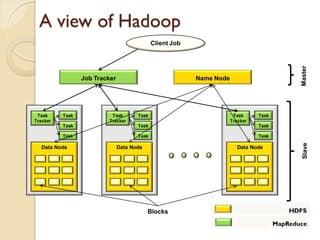





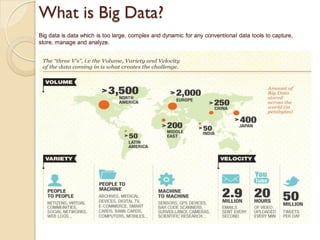
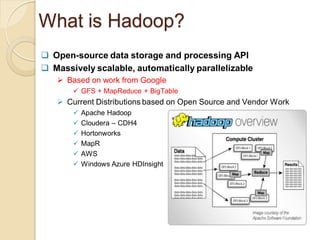
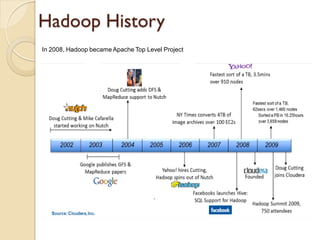
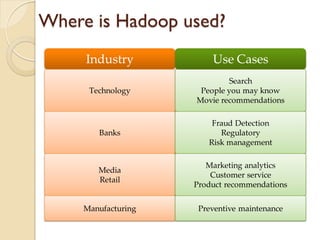
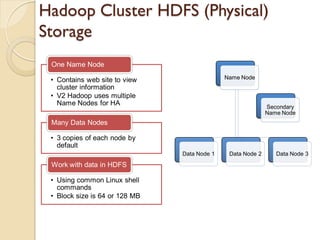
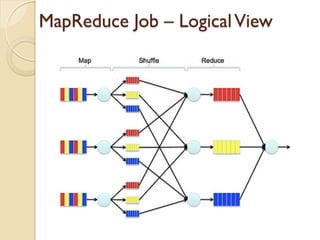
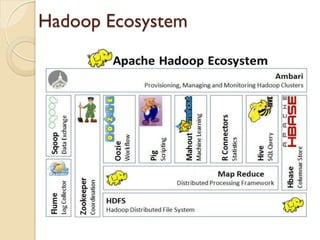
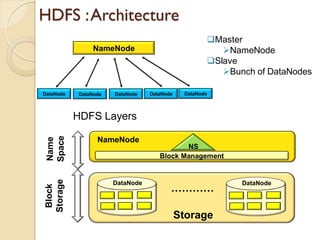
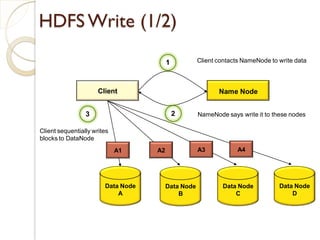
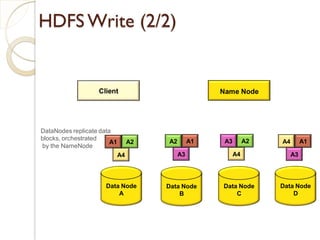
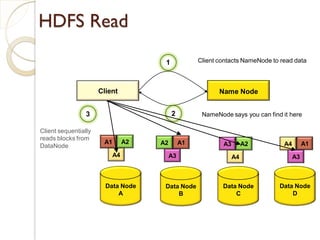
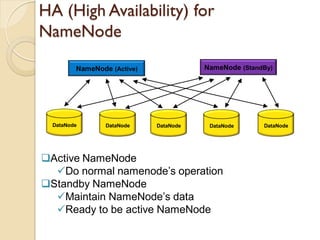
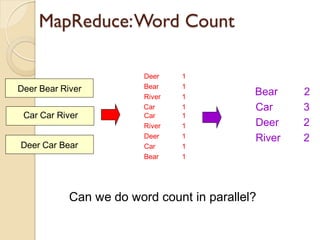
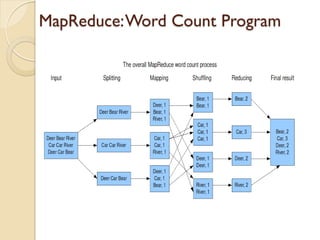
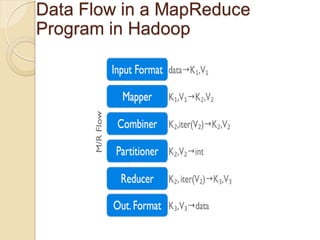
The document provides an overview of big data, analytics, Hadoop, and related concepts. It discusses what big data is and the challenges it poses. It then describes Hadoop as an open-source platform for distributed storage and processing of large datasets across clusters of commodity hardware. Key components of Hadoop introduced include HDFS for storage, MapReduce for parallel processing, and various other tools. A word count example demonstrates how MapReduce works. Common use cases and companies using Hadoop are also listed.















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







