


![Big Data
Think at Scale
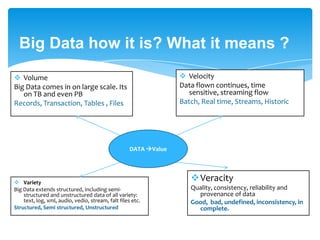
Data is in TB even in PB
• Facebook has 400 terabytes of stored data and ingest 20 terabytes of
new data per day. Hosts approx. 10 billion photos, 5PB(2011) and is
growing 4TB per day
• NYSE generates 1TB data/day
• The Internet Archive stores around 2PB of data and is growing at a rate
of 20PB per month
Flood of data is coming from many resources
Social network profile, activity , logging and tracking
Public web information
Data ware house appliances
Internet Archive store etc.. [Q: How much big ? ]](https://image.slidesharecdn.com/hadoopintruduction-1-130725044911-phpapp02/85/Hadoop-introduction-Why-and-What-is-Hadoop-3-320.jpg)
























The document provides an introduction to Hadoop, highlighting its significance in processing and storing big data, which presents unique challenges such as volume, velocity, variety, and veracity. It discusses Hadoop's architecture, including HDFS for storage and MapReduce for data processing, emphasizing its ability to scale on commodity hardware while handling failures effectively. Additionally, the document outlines the evolution of Hadoop, its ecosystem, and use cases across various industries, underlining its role as a complement rather than a replacement for traditional relational database management systems.




































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















