






![Resources Tracked with Capacity Scheduler
11
Memory CPU Servers
Scheduler today considers both
Memory and CPU as a resource
Dominant Resource First Calculator
(used Dominant Resource Fairness) for
resource allocation
Utilization can suffer if not careful
Specifying resources for containers is
framework-specific
mapreduce.[map|reduce].cpu.vcores
mapreduce.[map|reduce].memory.mb
MAX(Physical_Memory_Bytes) memory.mb
MAX(CPU_time_spent / task_time)
cpu.vcores
vCores is tricky, but also more forgiving
default as 1.5/2 G and 10 vCores
Resource Allocation Container Resources in MapReduce](https://image.slidesharecdn.com/june91205pmyahoosinghrobertsv2-150616214901-lva1-app6892/85/Towards-SLA-based-Scheduling-on-YARN-Clusters-11-320.jpg)






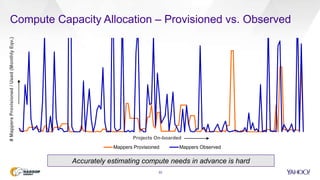
![Notes on Compute Capacity Estimation
23
Step 1: Sample Run (with a tenth of data on a sandbox cluster)
Stages # Map Map Size Map Time # Reduce Reduce Size Reduce Time Shuffle Time
Stage 1 100 1.5 GB 15 Min 50 2 GB 10 Min 3 Min
Stage 2 - L 150 1.5 GB 10 Min 50 2 GB 10 Min 4 Min
Stage 2 - R 100 1.5 GB 5 Min 25 2 GB 5 Min 1 Min
Stage 3 200 1.5 GB 10 Min 75 2 GB 5 Min 2 Min
Notes:
SLOT_MILLIS_MAPS and SLOT_MILLIS_REDUCES gives the time spent
TOTAL_LAUNCHED_MAPS and TOTAL_LAUNCHED_REDUCES gives # Map and # Reduce
Shuffle Time is Data per Reducer / est. 4 MB/s (bandwidth for data transfer from Map to Reduce)
Reduce time includes the Sort time , Add 10% for speculative execution (failed/killed task attempts)
Step 2: Mappers and Reducers
Number of mappers 278 [ (Max of Stage 1,2 & 3) x 10 ] / (SLA of 6 Hrs. / 35)
Number of reducers 84 [ (Max of Stage 1,2 & 3) x 10 ] / (SLA of 6 Hrs. / 25)
Memory required for mappers and reducers 278 x 1.5 + 84 x 2 = 585 GB
Number of servers 585/ 44 = 14 servers](https://image.slidesharecdn.com/june91205pmyahoosinghrobertsv2-150616214901-lva1-app6892/85/Towards-SLA-based-Scheduling-on-YARN-Clusters-23-320.jpg)
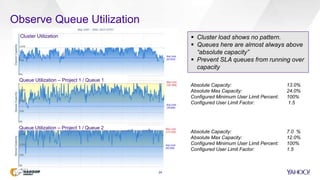

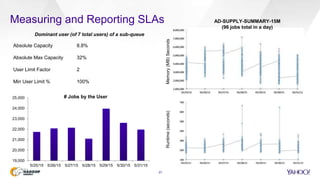





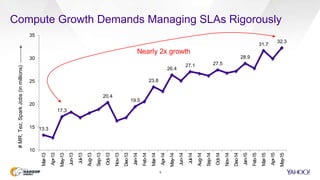
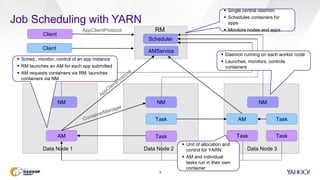
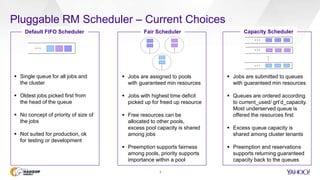
This document discusses Yahoo's use of the Capacity Scheduler in Hadoop YARN to manage job scheduling and service level agreements (SLAs). It provides an overview of how Capacity Scheduler works, including how it tracks resources, configures queues with guaranteed minimum capacities, and uses parameters like minimum user limits, capacity, and maximum capacity to allocate resources fairly while meeting SLAs. The document is presented by Sumeet Singh and Nathan Roberts of Yahoo to provide insight into how Capacity Scheduler is used at Yahoo to manage their large Hadoop clusters processing over a million jobs per day.







































































































