Download as PDF, PPTX



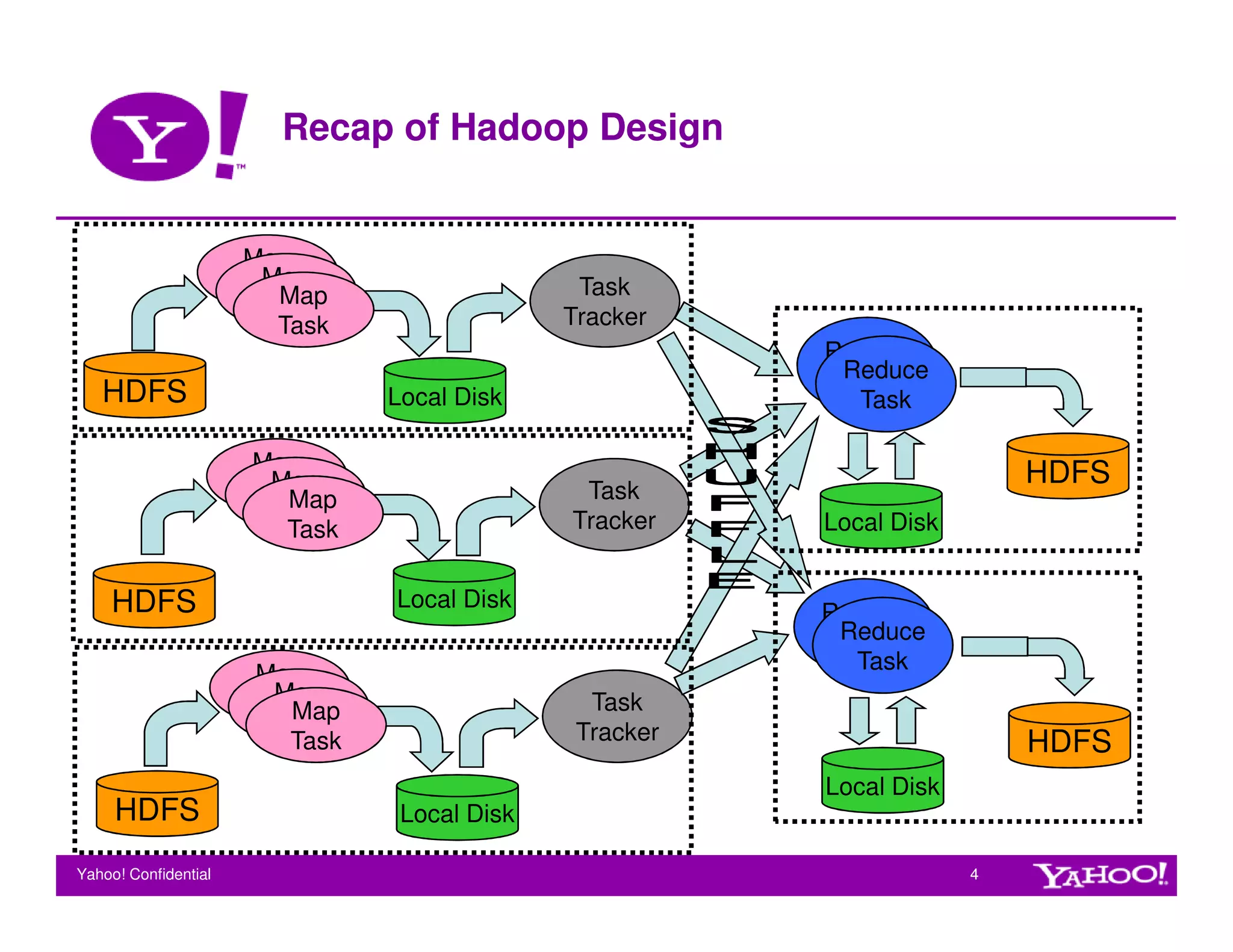

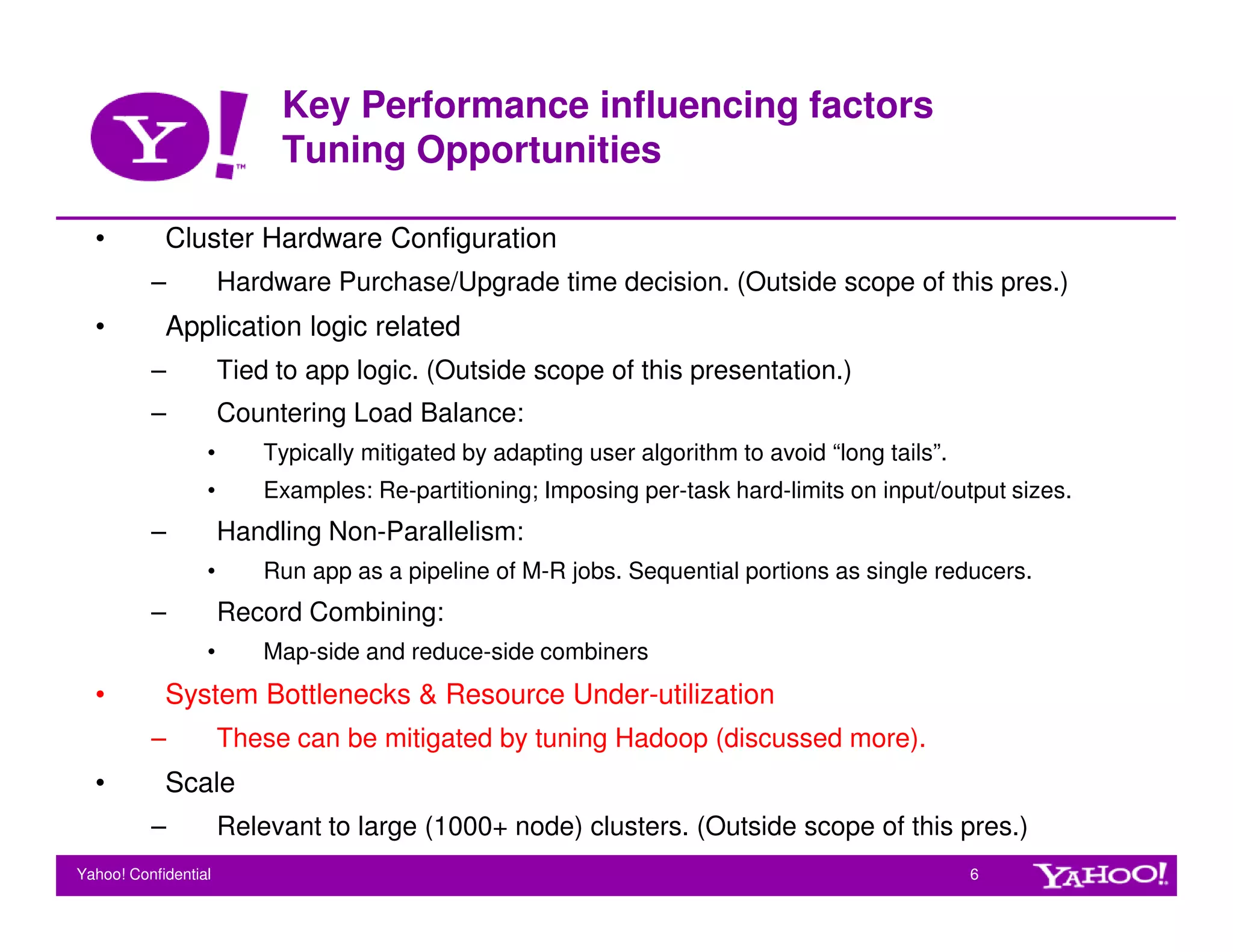
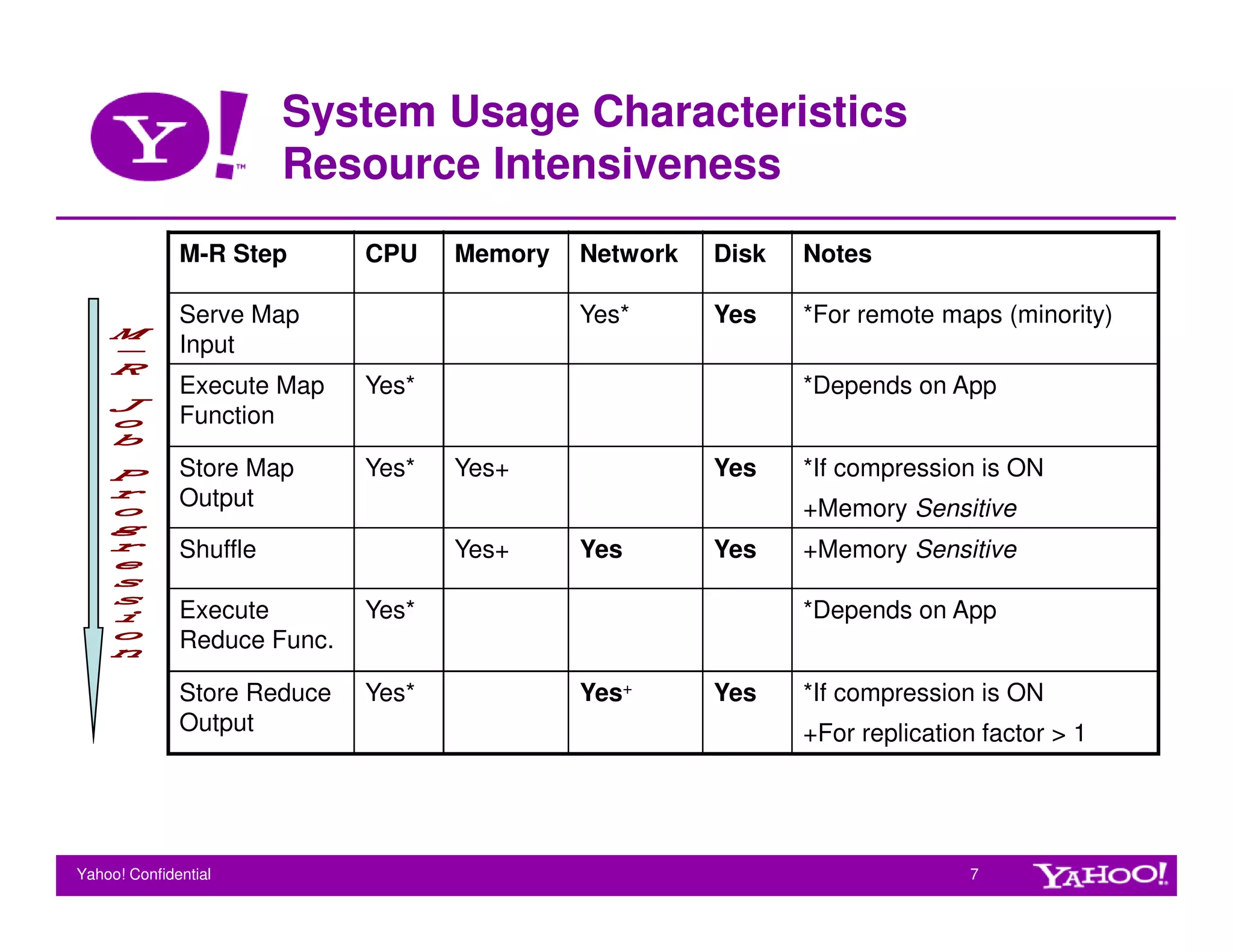






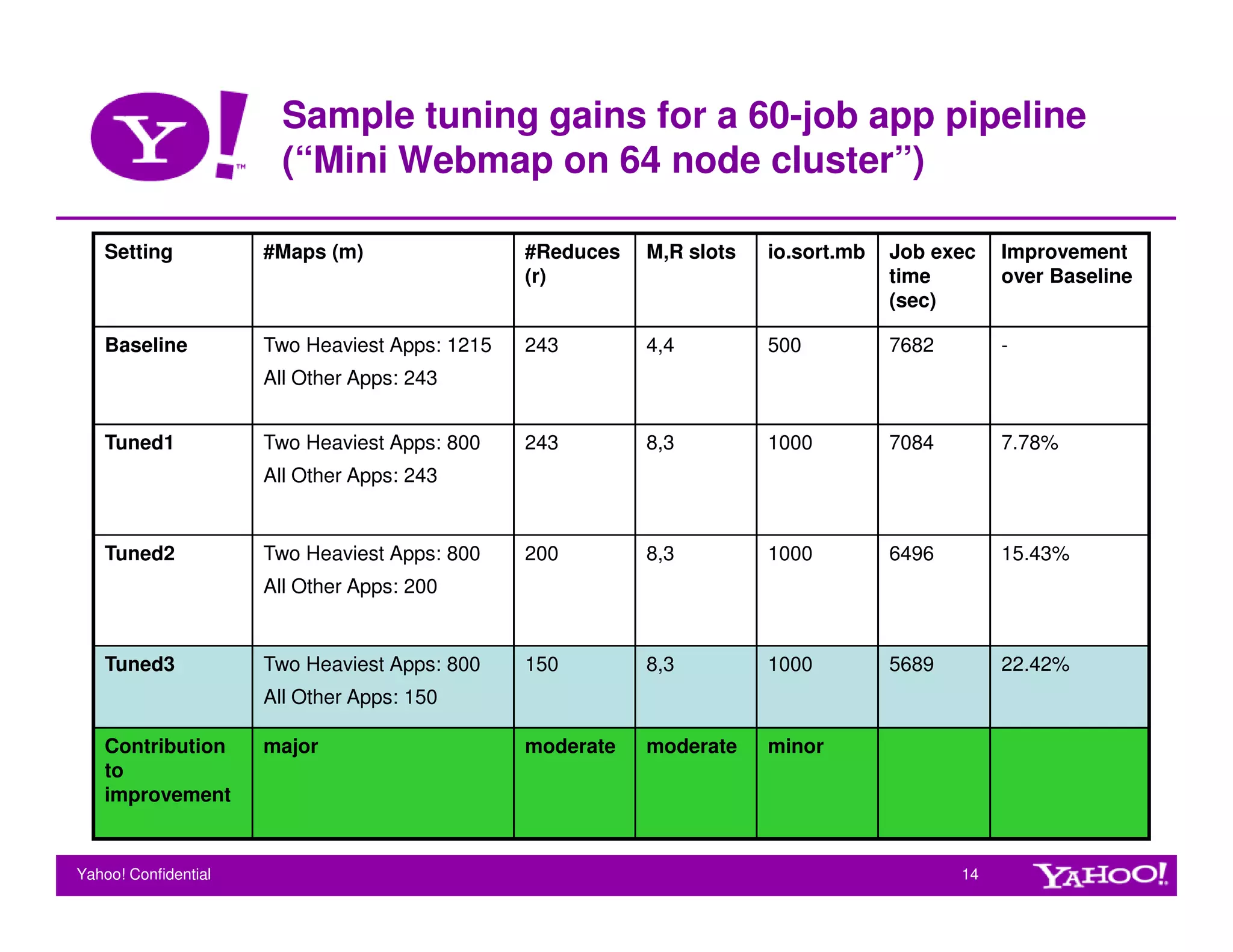


This document provides guidelines for tuning Hadoop for performance. It discusses key factors that influence Hadoop performance like hardware configuration, application logic, and system bottlenecks. It also outlines various configuration parameters that can be tuned at the cluster and job level to optimize CPU, memory, disk throughput, and task granularity. Sample tuning gains are shown for a webmap application where tuning multiple parameters improved job execution time by up to 22%.






































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















