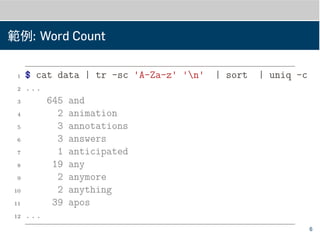
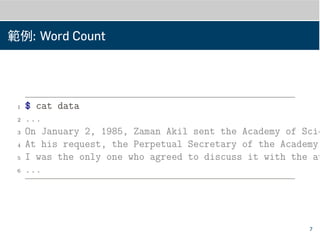
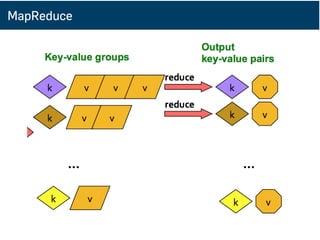
範例: Word Count
1$ cat data
2 ...
3 On January 2, 1985, Zaman Akil sent the Academy of Scie
4 At his request, the Perpetual Secretary of the Academy,
5 I was the only one who agreed to discuss it with the au
6 ...
7
範例: Word Count
1$ cat data | tr -sc 'A-Za-z' 'n' | sort
2 ...
3 Also
4 Also
5 Also
6 Although
7 Although
8 America
9 American
10 American
11 Among
12 An
13 An 11
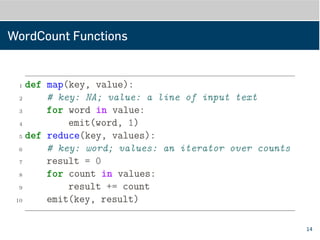
WordCount Functions
1 defmap(key, value):
2 # key: NA; value: a line of input text
3 for word in value:
4 emit(word, 1)
5 def reduce(key, values):
6 # key: word; values: an iterator over counts
7 result = 0
8 for count in values:
9 result += count
10 emit(key, result)
14
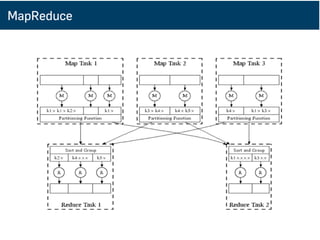
MapReduce Implementations
■ Spark
■Designed for performance
■ APIs for Scala, Java, and Python
■ Disco: MapReduce framework for Python
■ MapReduce-MPI: for distributed-memory parallel
machines on top of standard MPI message passing
■ Meguro: a simple Javascript Map/Reduce framework
■ bashreduce : mapreduce in a bash script
■ localmapreduce
實際手動跑 (lmr)
■ 使用pipe 測試 ngramcount.py
1 $ head -100 citeseerx.40000 | ./ngramcount.py -m |
2 > sort -k1,1 -t$'t' | ./ngramcount.py -r | less
■ 使用 lmr(localmapreduce) 分散執行
1 $ pv citeseerx.40000 |
2 > lmr 300k 20 './ngramcount.py -m' './ngramcount.py -r' out
3 $ ls out
4 reducer-00 reducer-02 reducer-04 reducer-06 reducer-08 reducer-10 re
5 reducer-01 reducer-03 reducer-05 reducer-07 reducer-09 reducer-11 re
6 $ less out/*
21
22.
Ngram Count I
1#!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from __future__ import unicode_literals, print_function
4
5
6 def ngrams(words):
7 for length in range(1, 5 + 1):
8 for ngram in zip(*(words[i:] for i in range(length))):
9 yield ngram
10
11
12 def mapper(line):
13 # from nltk.tokenize import word_tokenize
14 # words = word_tokenize(line.lower())
15 import re
16 words = re.findall(r'[a-z]+', line.lower())
17 for ngram in ngrams(words):
22
23.
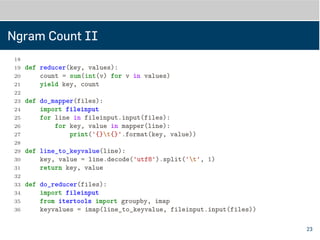
Ngram Count II
18yield ' '.join(ngram), 1
19
20
21 def reducer(key, values):
22 count = sum(int(v) for v in values)
23 yield key, count
24
25
26 def do_mapper(files):
27 import fileinput
28 for line in fileinput.input(files):
29 for key, value in mapper(line):
30 print('{}t{}'.format(key, value))
31
32
33 def line_to_keyvalue(line):
34 key, value = line.decode('utf8').split('t', 1)
35 return key, value
36
23
24.
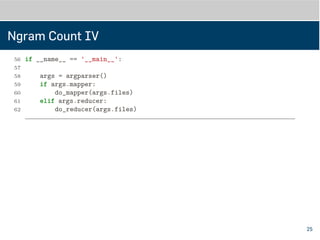
Ngram Count III
37
38def do_reducer(files):
39 import fileinput
40 from itertools import groupby, imap
41 keyvalues = imap(line_to_keyvalue, fileinput.input(files))
42 for key, grouped_keyvalues in groupby(keyvalues,
43 key=lambda x: x[0]):
44 values = (v for k, v in grouped_keyvalues)
45 for key, value in reducer(key, values):
46 print('{}t{}'.format(key, value))
47
48
49 def argparser():
50 import argparse
51 parser = argparse.ArgumentParser(description='N-gram counter')
52 mode_group = parser.add_mutually_exclusive_group(required=True)
53 mode_group.add_argument(
54 '-r', '--reducer', action='store_true', help='reducer mode')
55 mode_group.add_argument(
24
練習:語言搜尋引擎
■ 建立一搜尋引擎用於搜尋英文詞語用法。
■ 可輔助英語學習與文章寫作。
搜尋例子
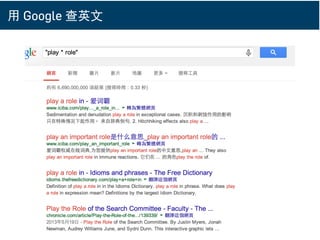
■adj. beach: 即代表搜尋 beach 前面出現過的形容詞。
■ play * role: 搜尋 play 與 role 中間最常出現的字詞
組合。
■ go ?to home: go 與 home 之間是否要放 to。
■ go * movie: go 與 role 中間最常出現的字詞組合。
■ kill the _: 最常被 kill 的東西是。
語法設計
語法 說明
_ 單一任意字詞
*零到多個任意字詞
?term term 可有可無
term1 | term2 term1 或 term2
adj. det. n. v. prep.形容詞、冠詞、名詞、動詞、介繫詞
搜尋例子
■ adj. beach: 即代表搜尋 beach 前面出現過的形容詞。
■ play * role: 搜尋 play 與 role 中間最常出現的字詞組
合。
■ go ?to home: go 與 home 之間是否要放 to。
■ go * movie: go 與 role 中間最常出現的字詞組合。
■ kill the _: 最常被 kill 的東西是。
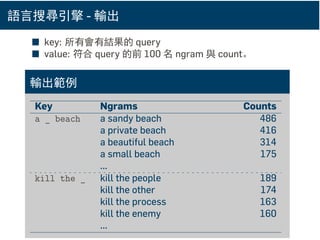
語言搜尋引擎 - 輸出
■key: 所有會有結果的 query
■ value: 符合 query 的前 100 名 ngram 與 count。
輸出範例
Key Ngrams Counts
a _ beach a sandy beach 486
a private beach 416
a beautiful beach 314
a small beach 175
...
kill the _ kill the people 189
kill the other 174
kill the process 163
kill the enemy 160
...
Bi-gram Count
Bi-gram CountMapper 範例
Input(value) Output(key => value)
C D C D C D => 2
D C => 1
B C D A B C => 1
C D => 1
D A => 1
C D A B C D => 1
D A => 1
A B => 1
Reducer 範例
Input(key => value) Output(key => value)
A B => 1 A B => 1
B C => 1 B C => 1
C D => 2 C D => 4
C D => 1
C D => 1
D A => 1 D A => 2
D A => 1
D C => 2 C C => 2
35.
語言搜尋引擎
Mapper 範例
Input(value) Output(key=> value)
A B C 200 A B C => A B C 200
_ B C => A B C 200
A _ C => A B C 200
A B _ => A B C 200
_ _ C => A B C 200
_ B _ => A B C 200
A _ _ => A B C 200
A D C 300 _ D C => A D C 300
A _ C => A D C 300
...
A E C 100 _ E C => A E C 100
A _ C => A E C 100
...
36.
語言搜尋引擎
Reducer 範例
Input(value) Output(key=> value)
A _ C => A B C 200 A _ C => A D C 300,
A _ C => A D C 300 A B C 200,
A _ C => A E C 100 A E C 100
A B _ => A B C 200 A B _ => A B C 200
A D _ => A D C 300 A D _ => A D C 300
A E _ => A E C 100 A E _ => A E C 100
A _ _ => A B C 200 A _ _ => A D C 300,
A _ _ => A D C 300 A B C 200,
A _ _ => A E C 100 A E C 100
_ B C => A B C 200 _ B C => A B C 200
_ D C => A D C 300 _ D C => A D C 300
_ E C => A E C 100 _ E C => A E C 100
... ...









![Ngram Count I
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from __future__ import unicode_literals, print_function
4
5
6 def ngrams(words):
7 for length in range(1, 5 + 1):
8 for ngram in zip(*(words[i:] for i in range(length))):
9 yield ngram
10
11
12 def mapper(line):
13 # from nltk.tokenize import word_tokenize
14 # words = word_tokenize(line.lower())
15 import re
16 words = re.findall(r'[a-z]+', line.lower())
17 for ngram in ngrams(words):
22](https://image.slidesharecdn.com/mapreduce-150519225511-lva1-app6892/85/MapReduce-22-320.jpg)
![Ngram Count III
37
38 def do_reducer(files):
39 import fileinput
40 from itertools import groupby, imap
41 keyvalues = imap(line_to_keyvalue, fileinput.input(files))
42 for key, grouped_keyvalues in groupby(keyvalues,
43 key=lambda x: x[0]):
44 values = (v for k, v in grouped_keyvalues)
45 for key, value in reducer(key, values):
46 print('{}t{}'.format(key, value))
47
48
49 def argparser():
50 import argparse
51 parser = argparse.ArgumentParser(description='N-gram counter')
52 mode_group = parser.add_mutually_exclusive_group(required=True)
53 mode_group.add_argument(
54 '-r', '--reducer', action='store_true', help='reducer mode')
55 mode_group.add_argument(
24](https://image.slidesharecdn.com/mapreduce-150519225511-lva1-app6892/85/MapReduce-24-320.jpg)







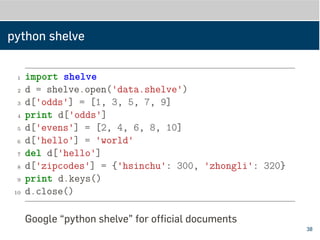

![python shelve
1 import shelve
2 d = shelve.open('data.shelve')
3 d['odds'] = [1, 3, 5, 7, 9]
4 print d['odds']
5 d['evens'] = [2, 4, 6, 8, 10]
6 d['hello'] = 'world'
7 del d['hello']
8 d['zipcodes'] = {'hsinchu': 300, 'zhongli': 320}
9 print d.keys()
10 d.close()
Google “python shelve” for official documents
38](https://image.slidesharecdn.com/mapreduce-150519225511-lva1-app6892/85/MapReduce-38-320.jpg)


































































![[系列活動] 手把手教你R語言資料分析實務](https://cdn.slidesharecdn.com/ss_thumbnails/stepbystepr20170114-170113030702-thumbnail.jpg?width=640&height=640&fit=bounds)

