Downloaded 10,528 times

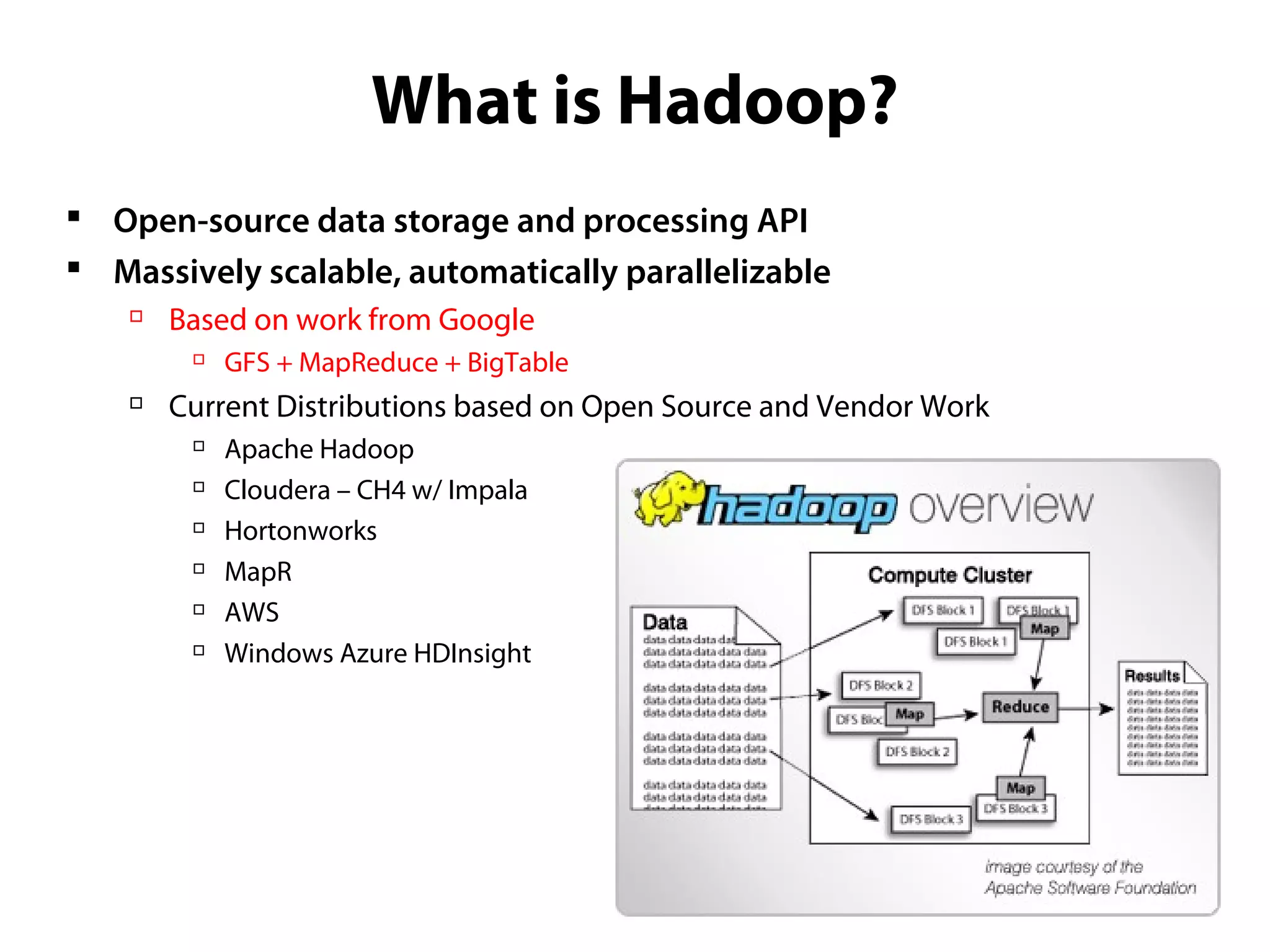



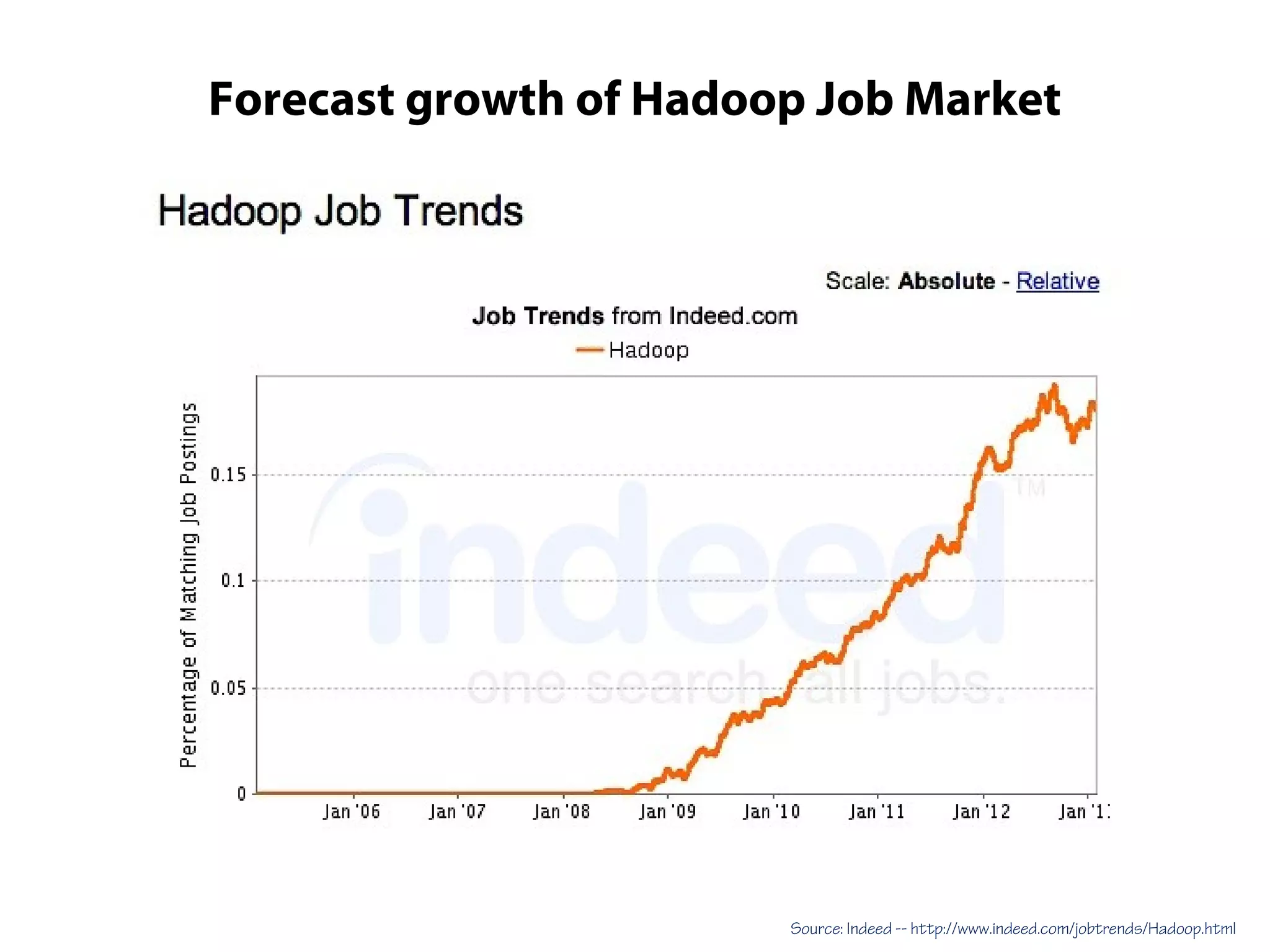

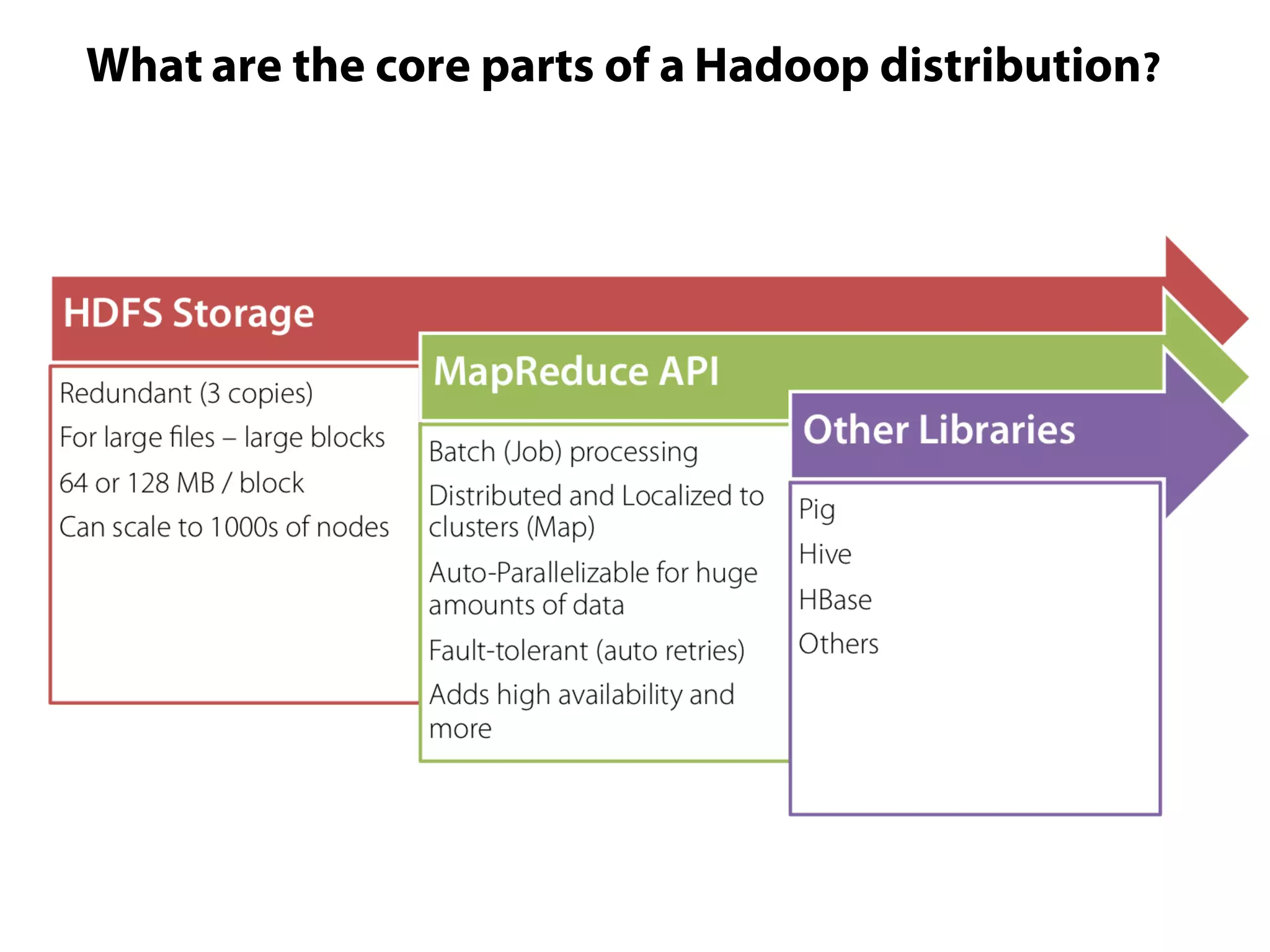
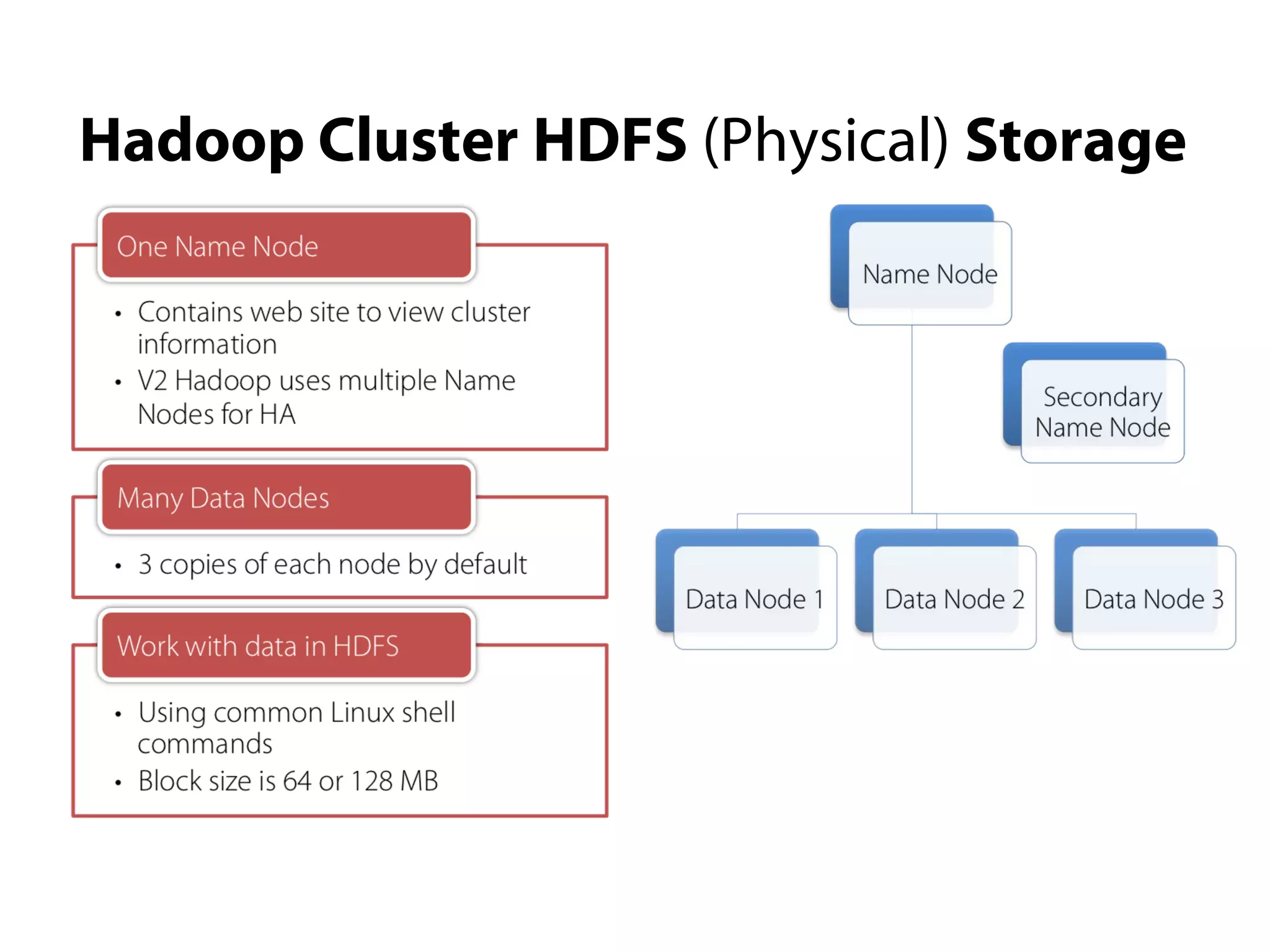
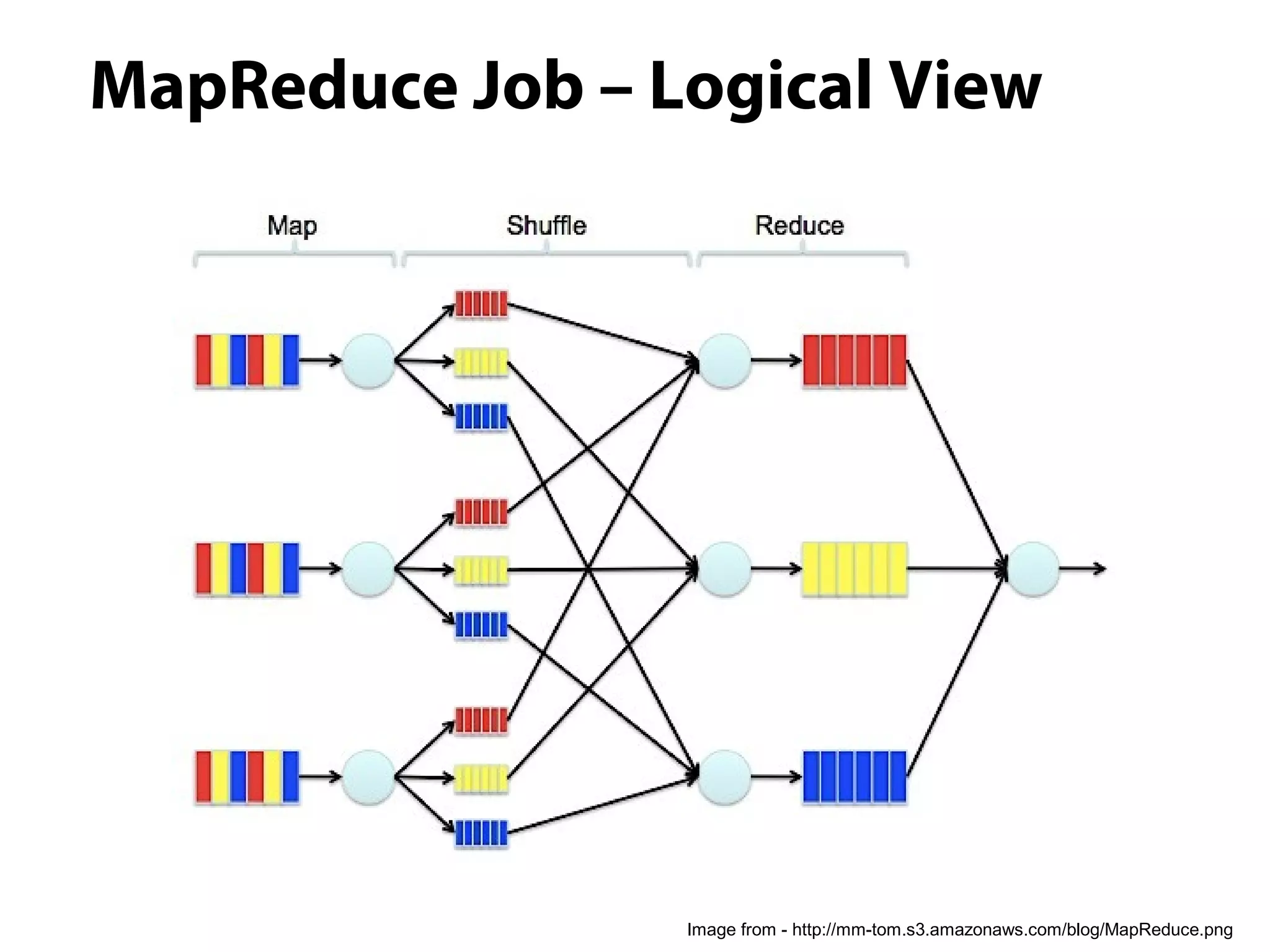
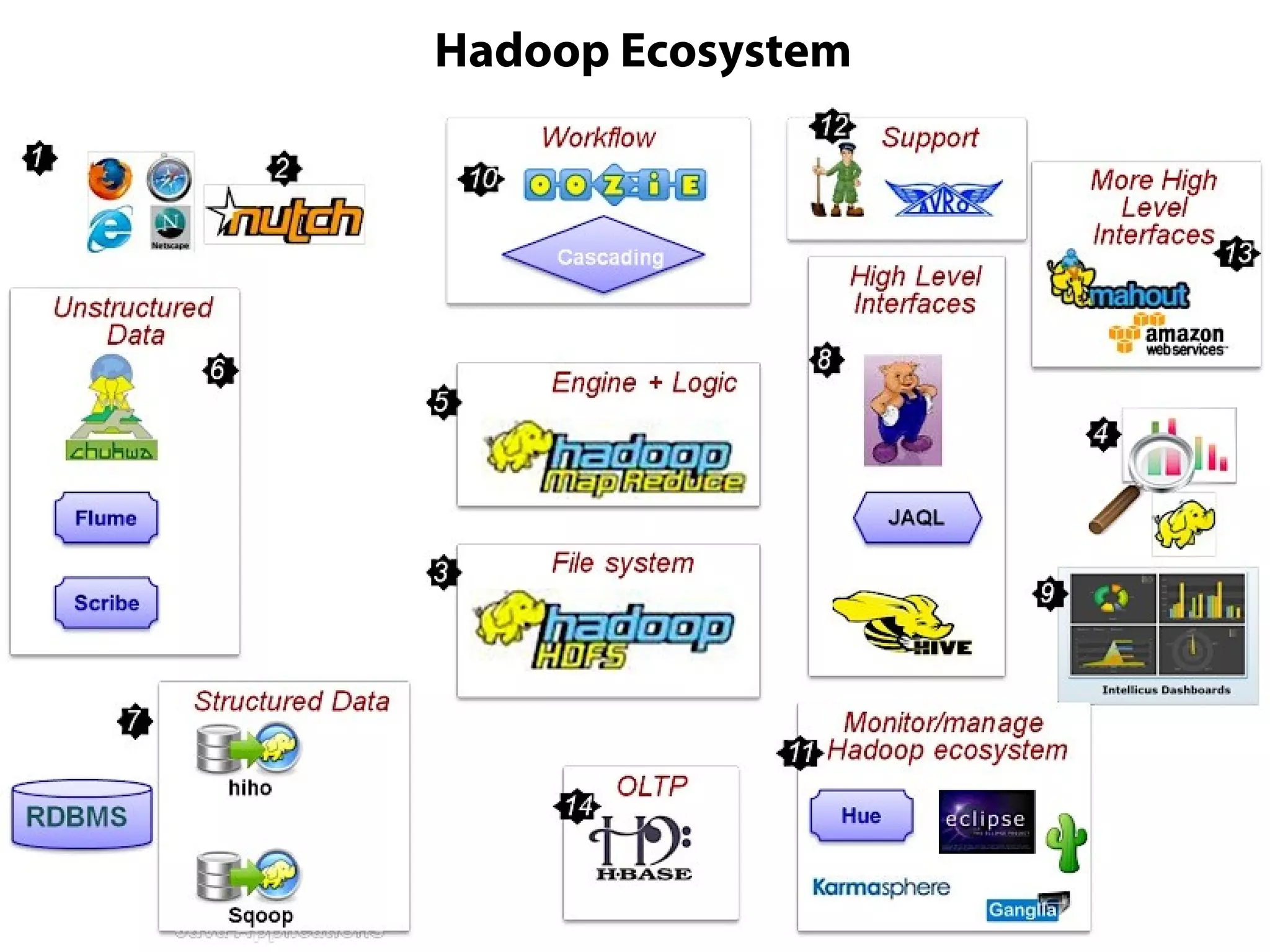

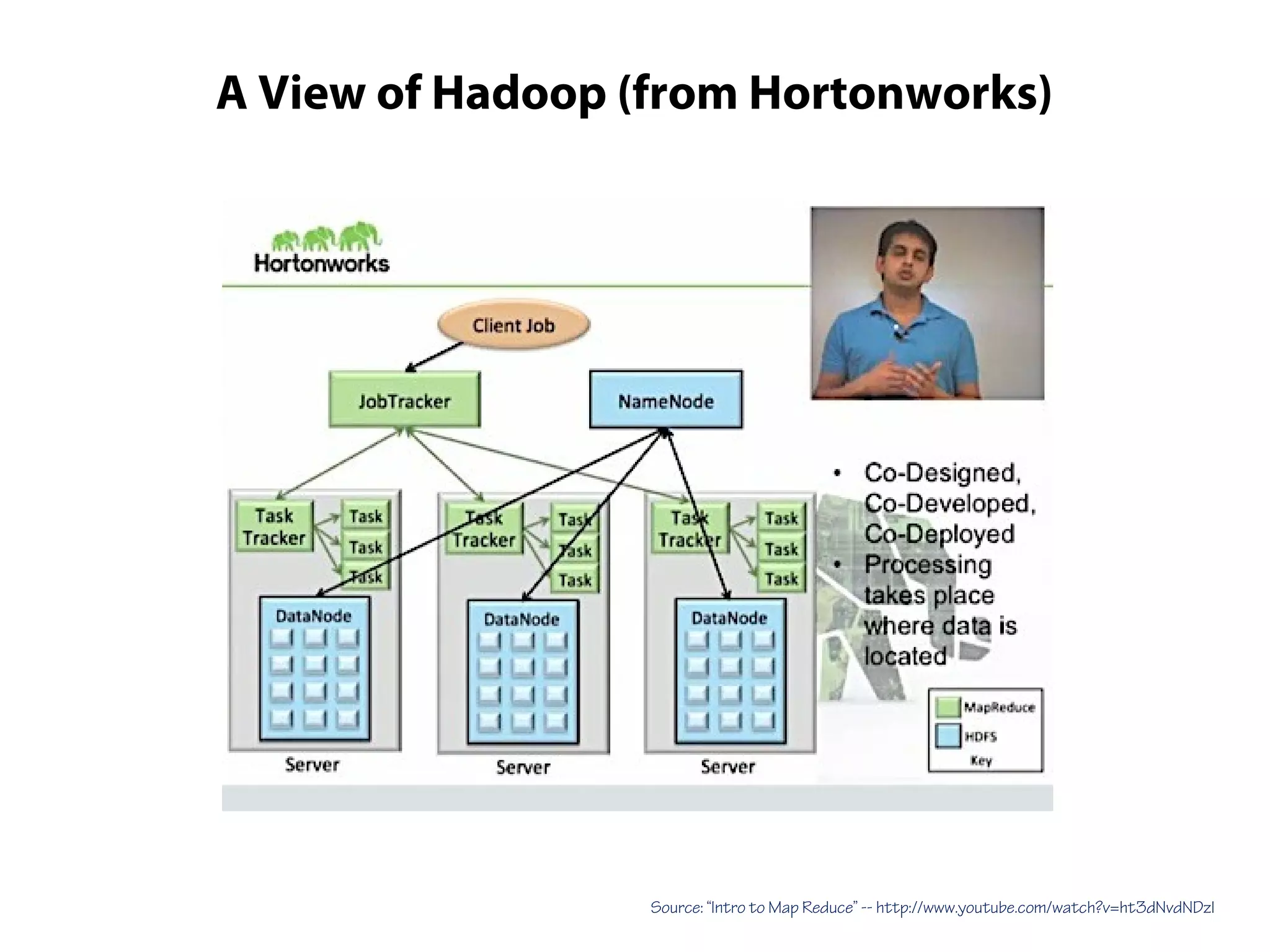
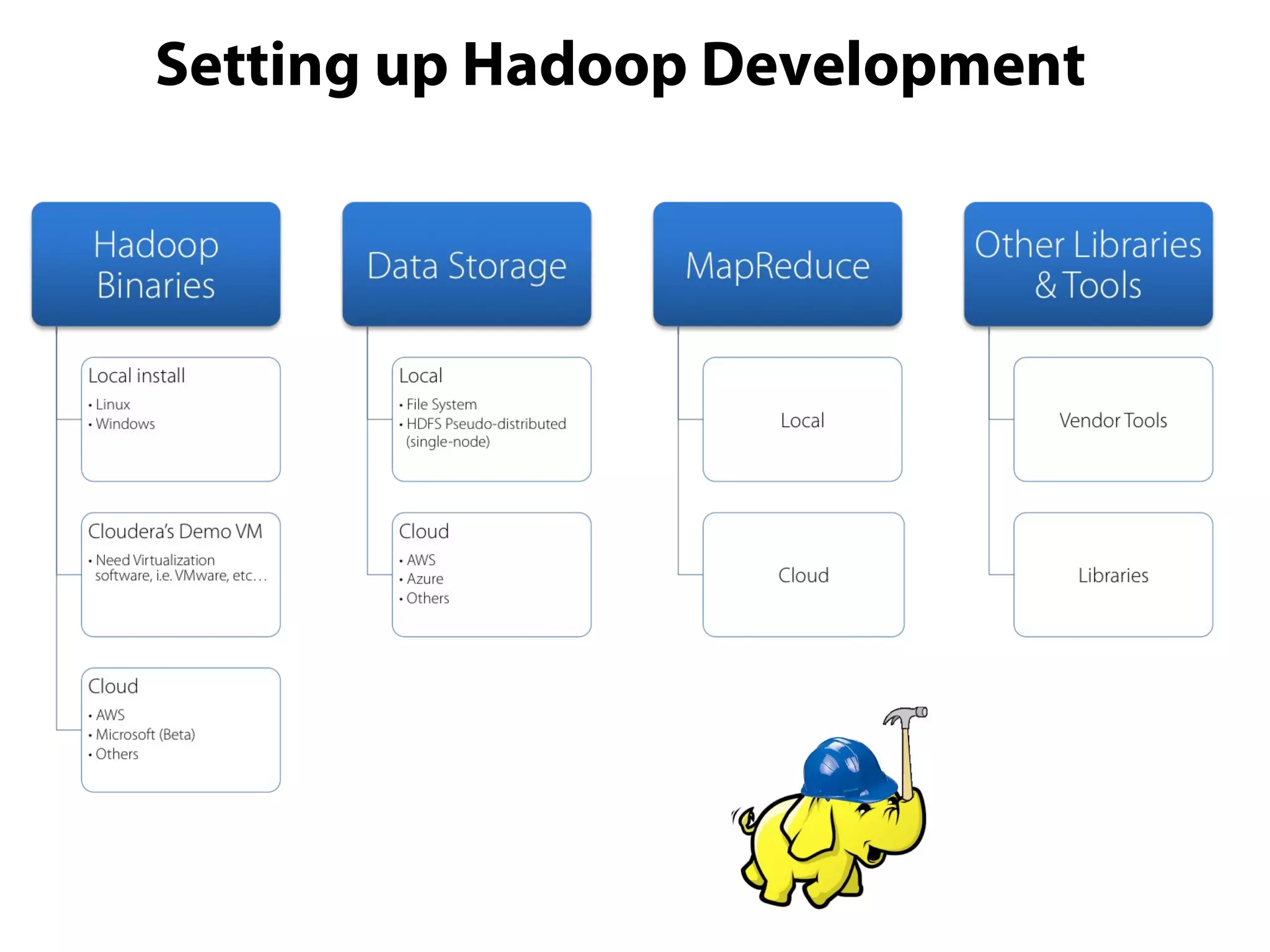
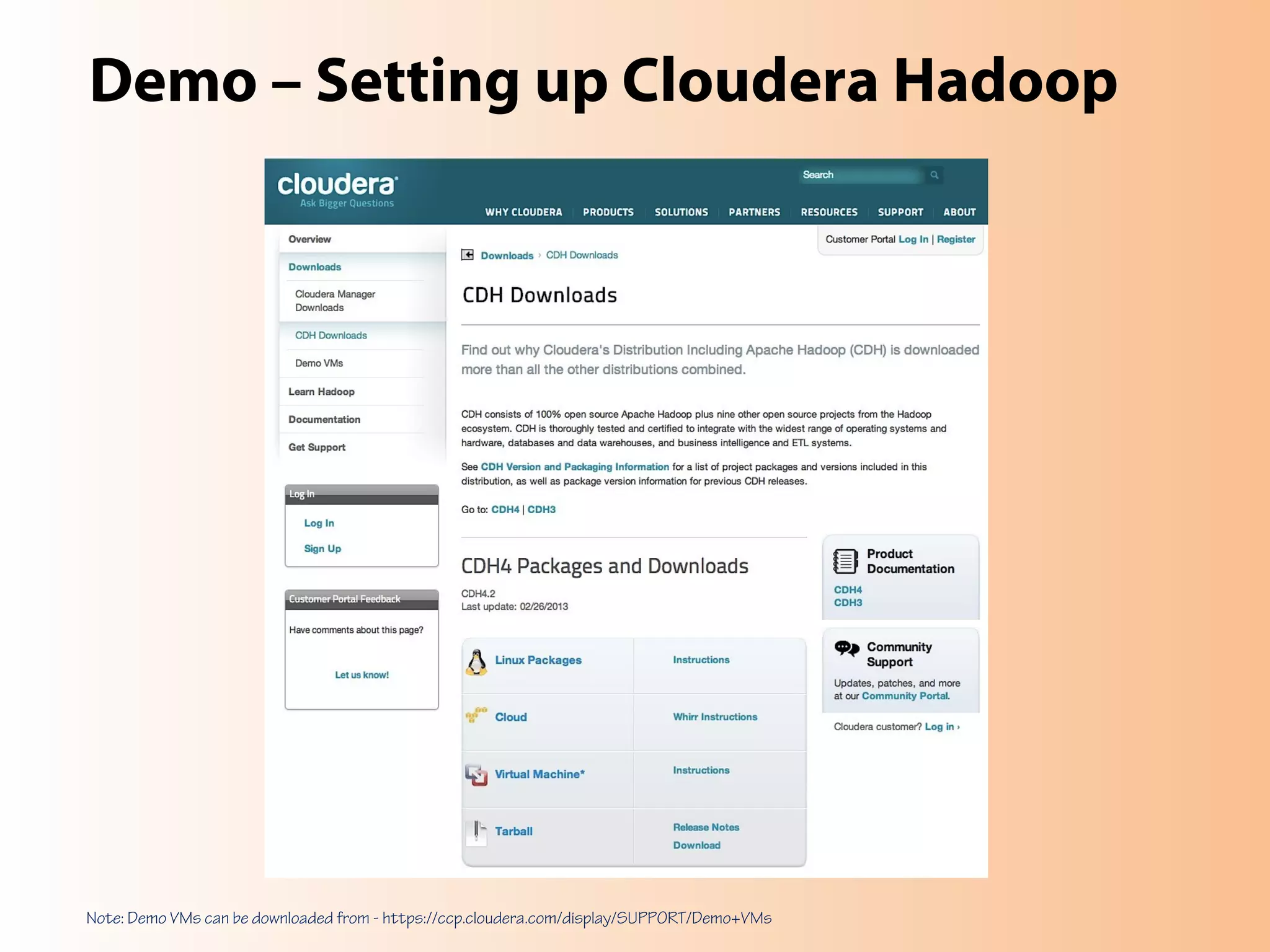

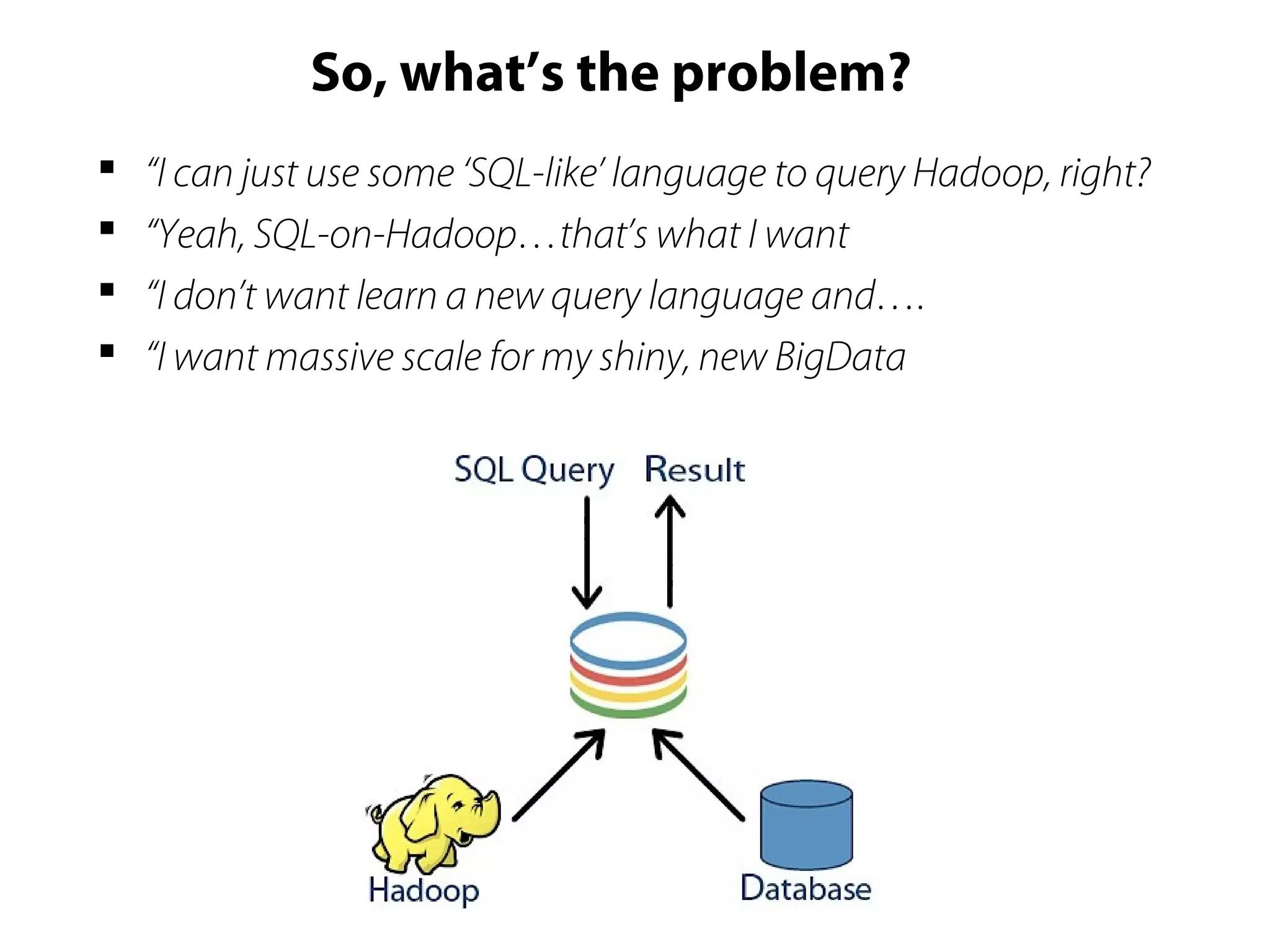

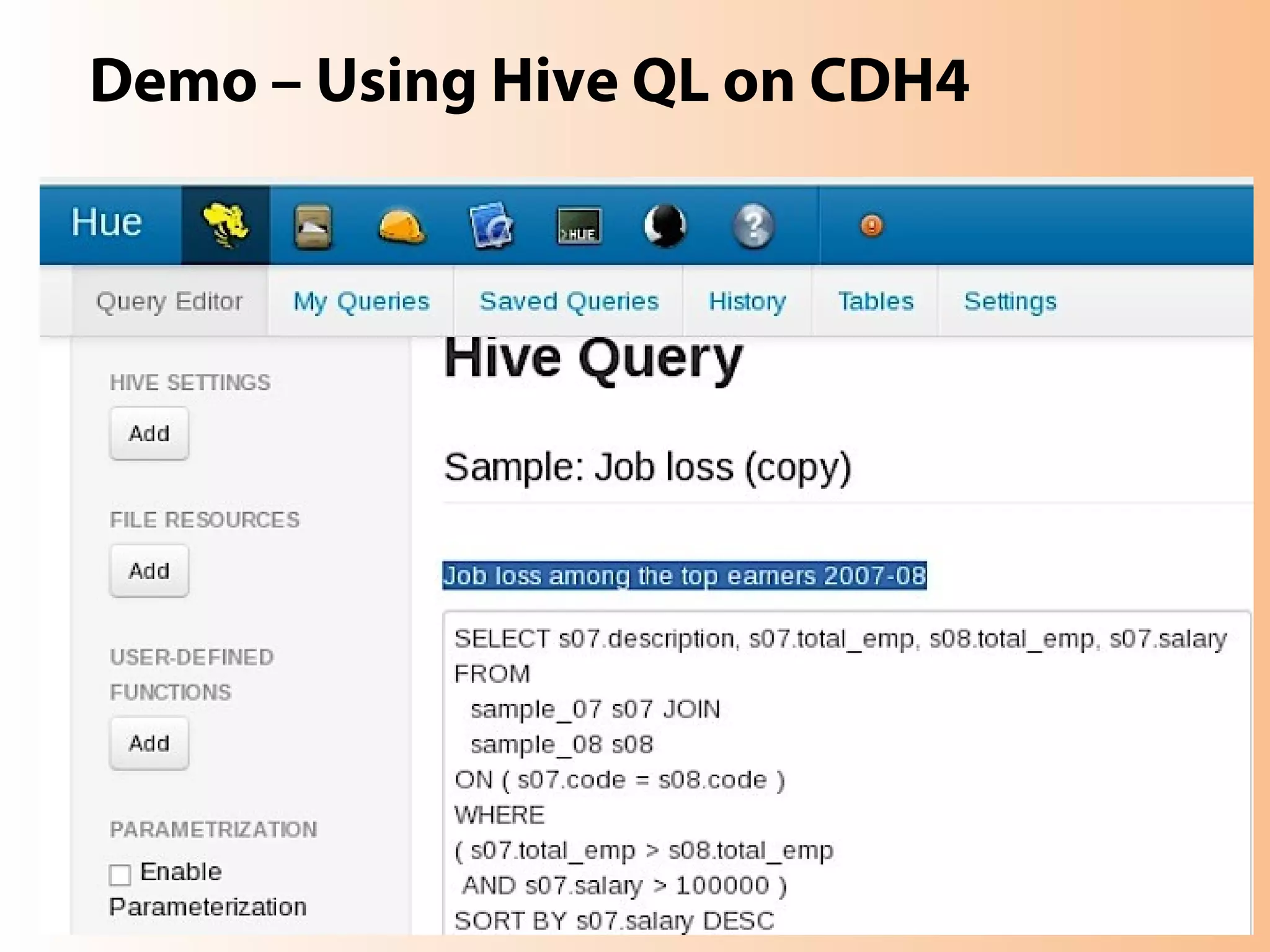


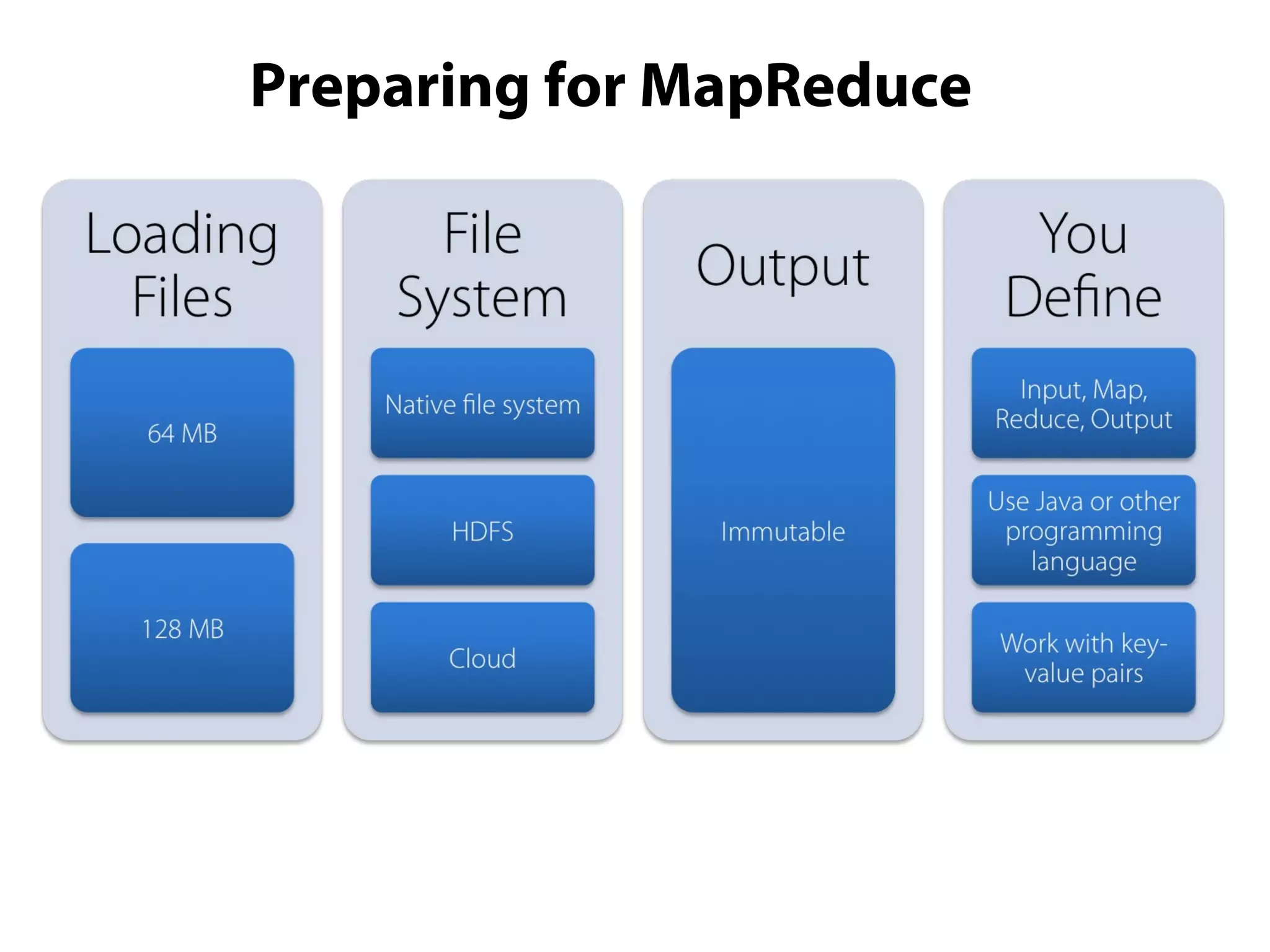

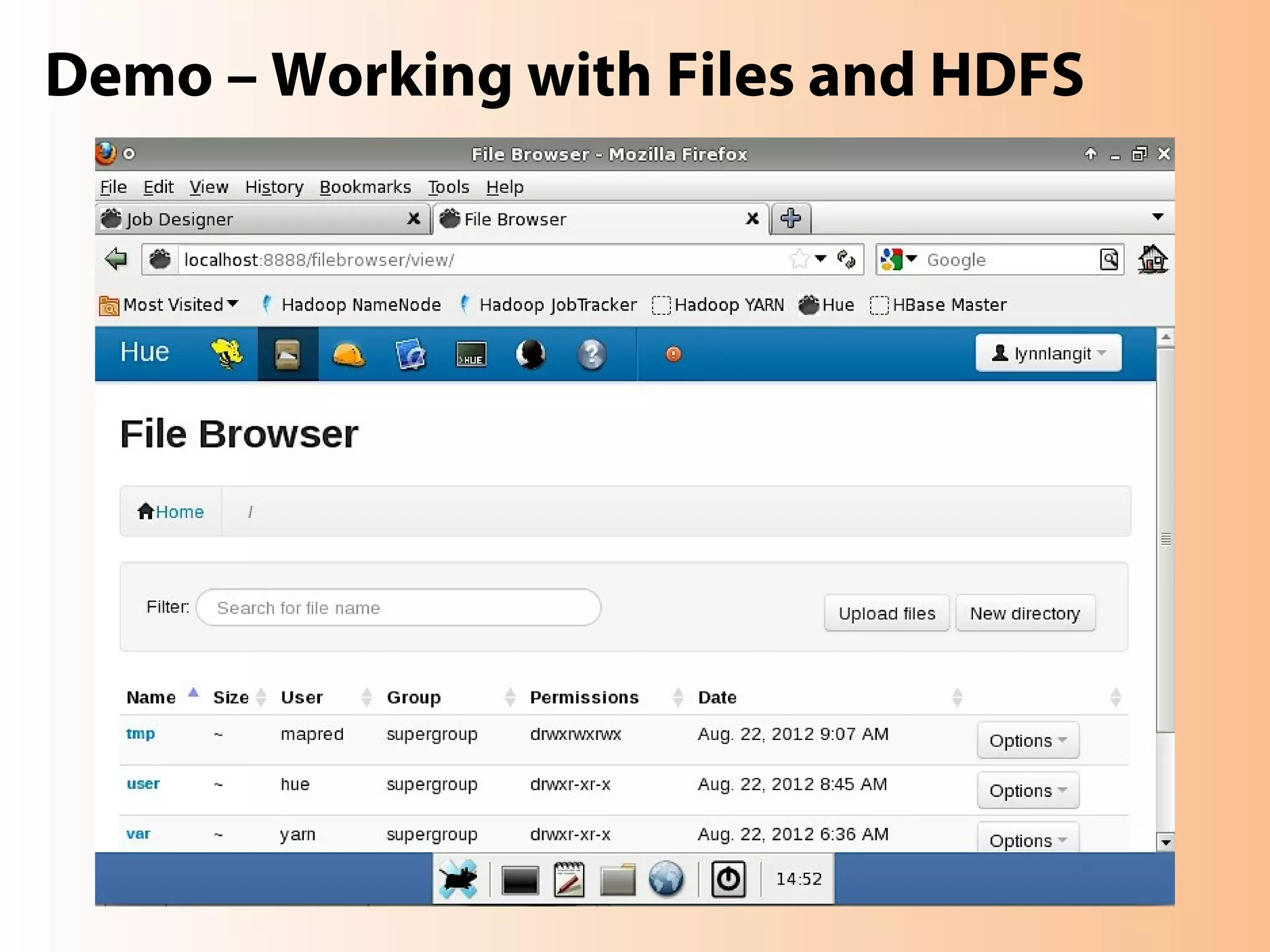

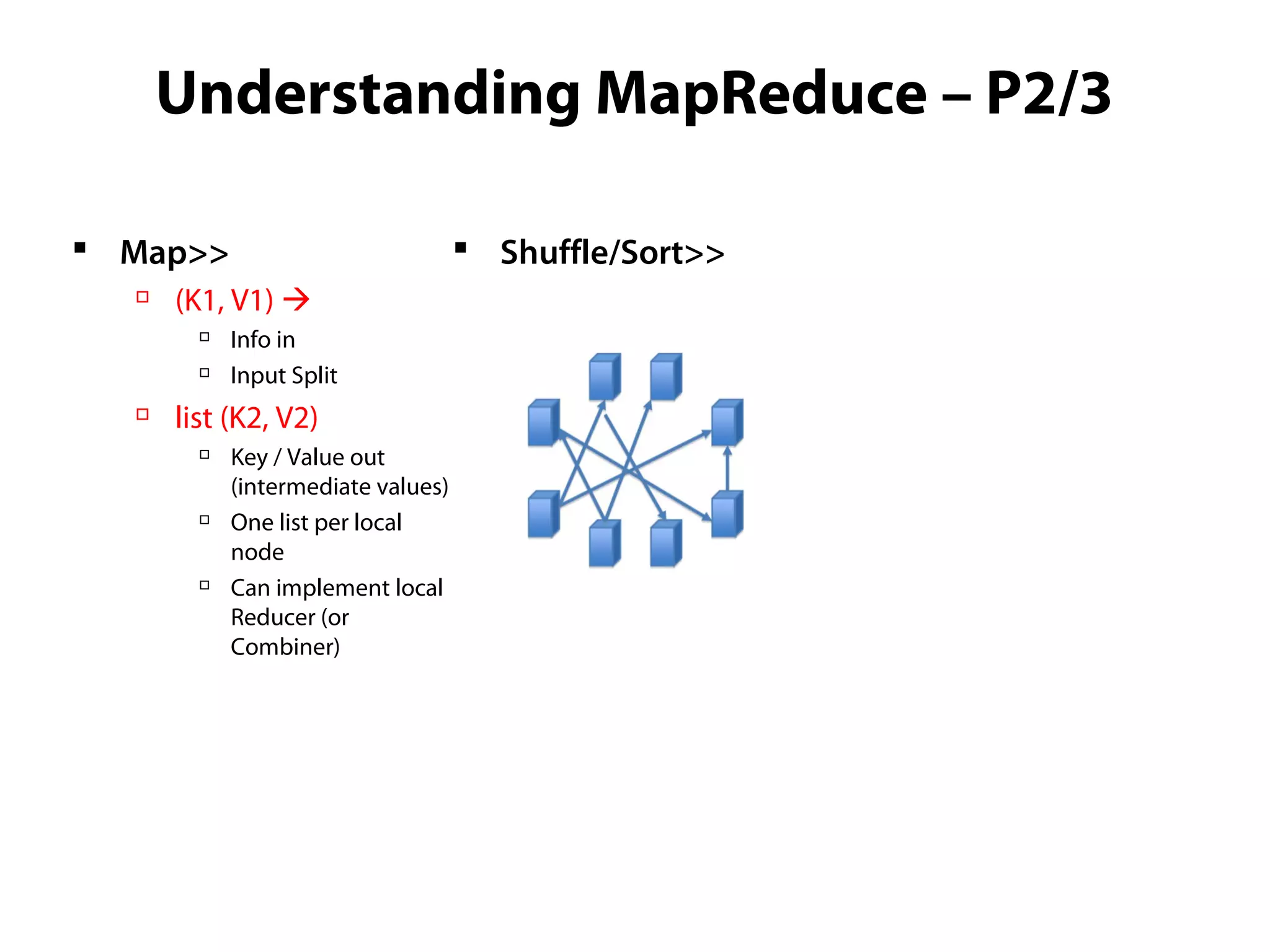
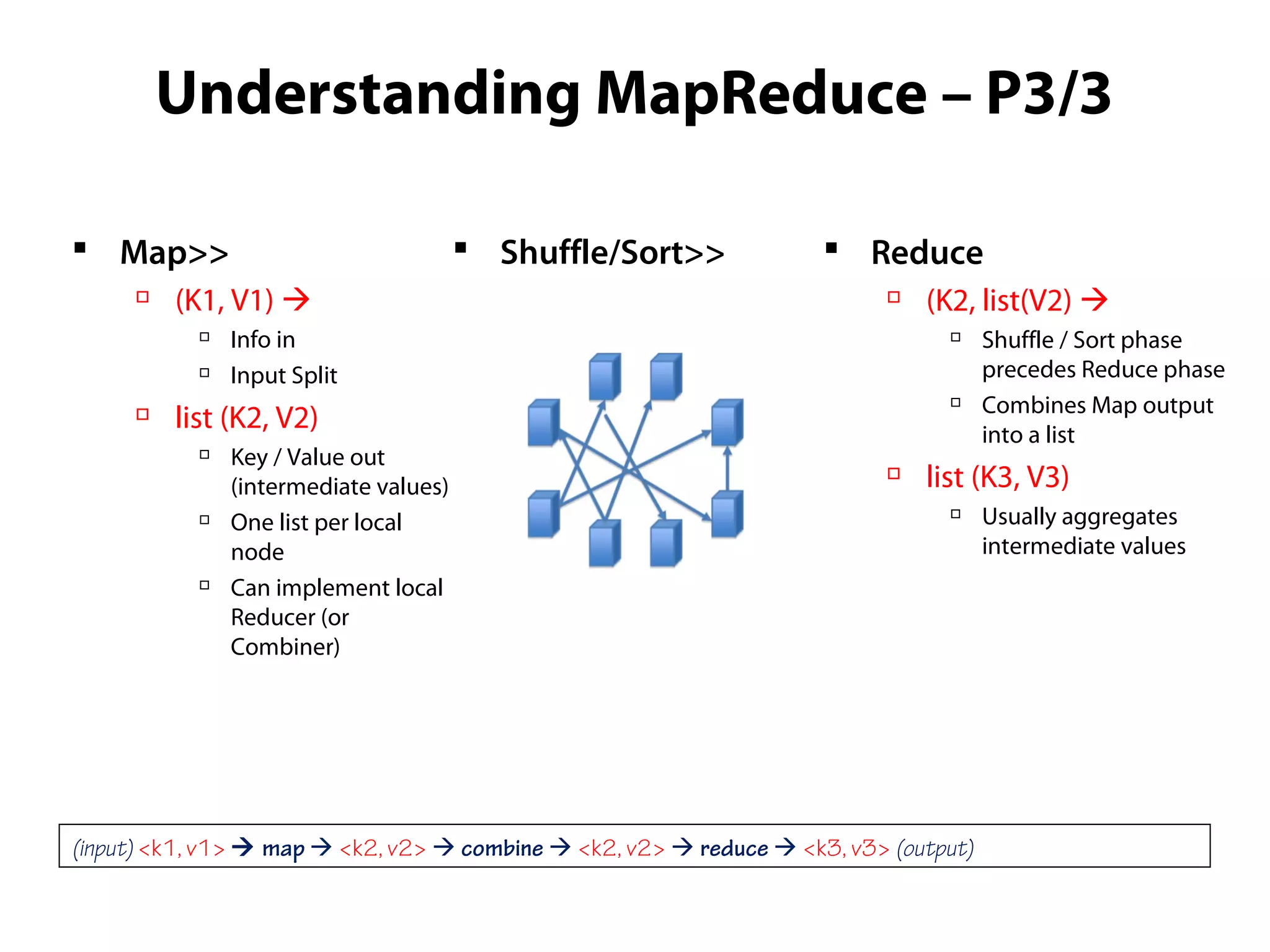
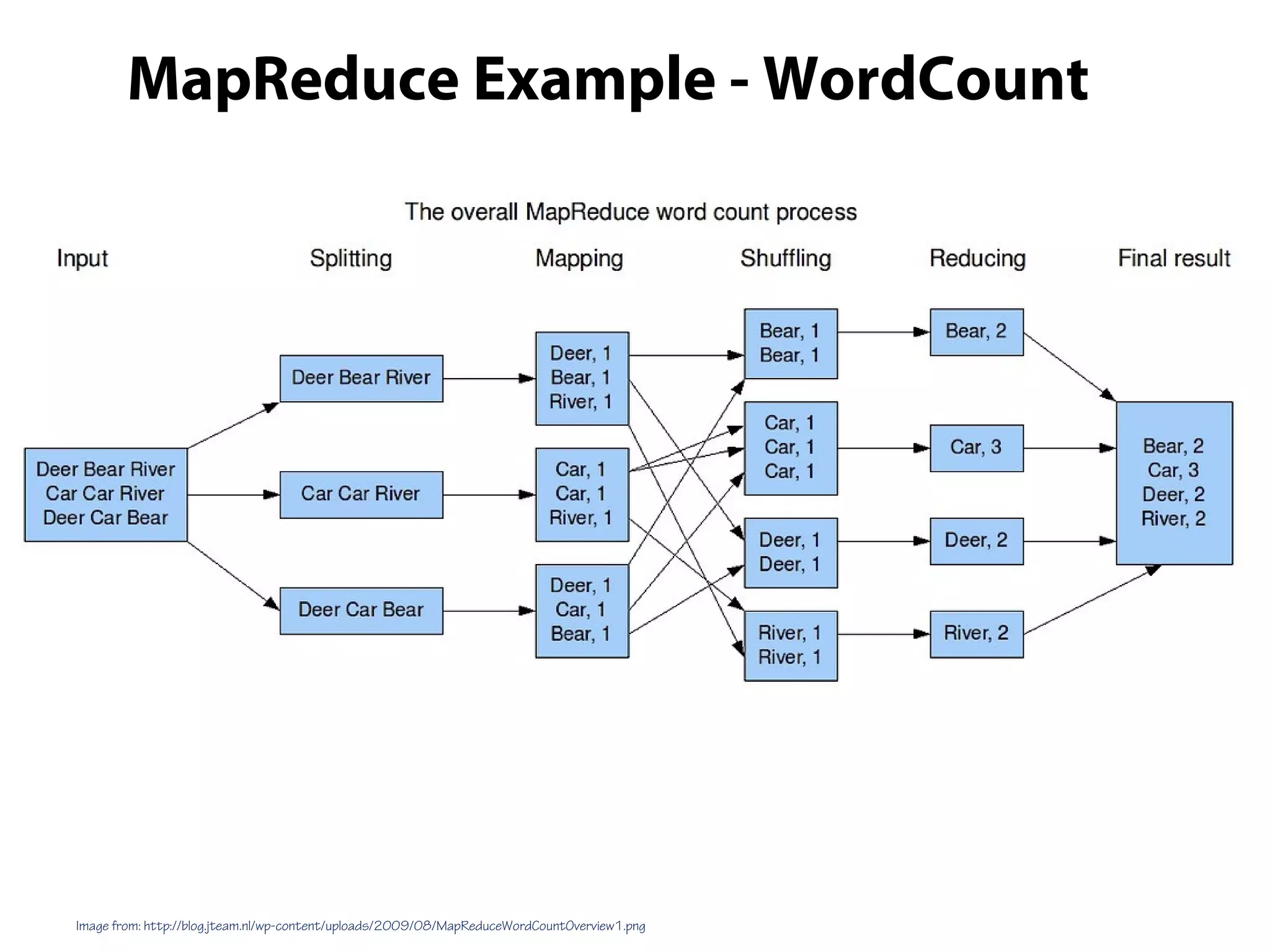
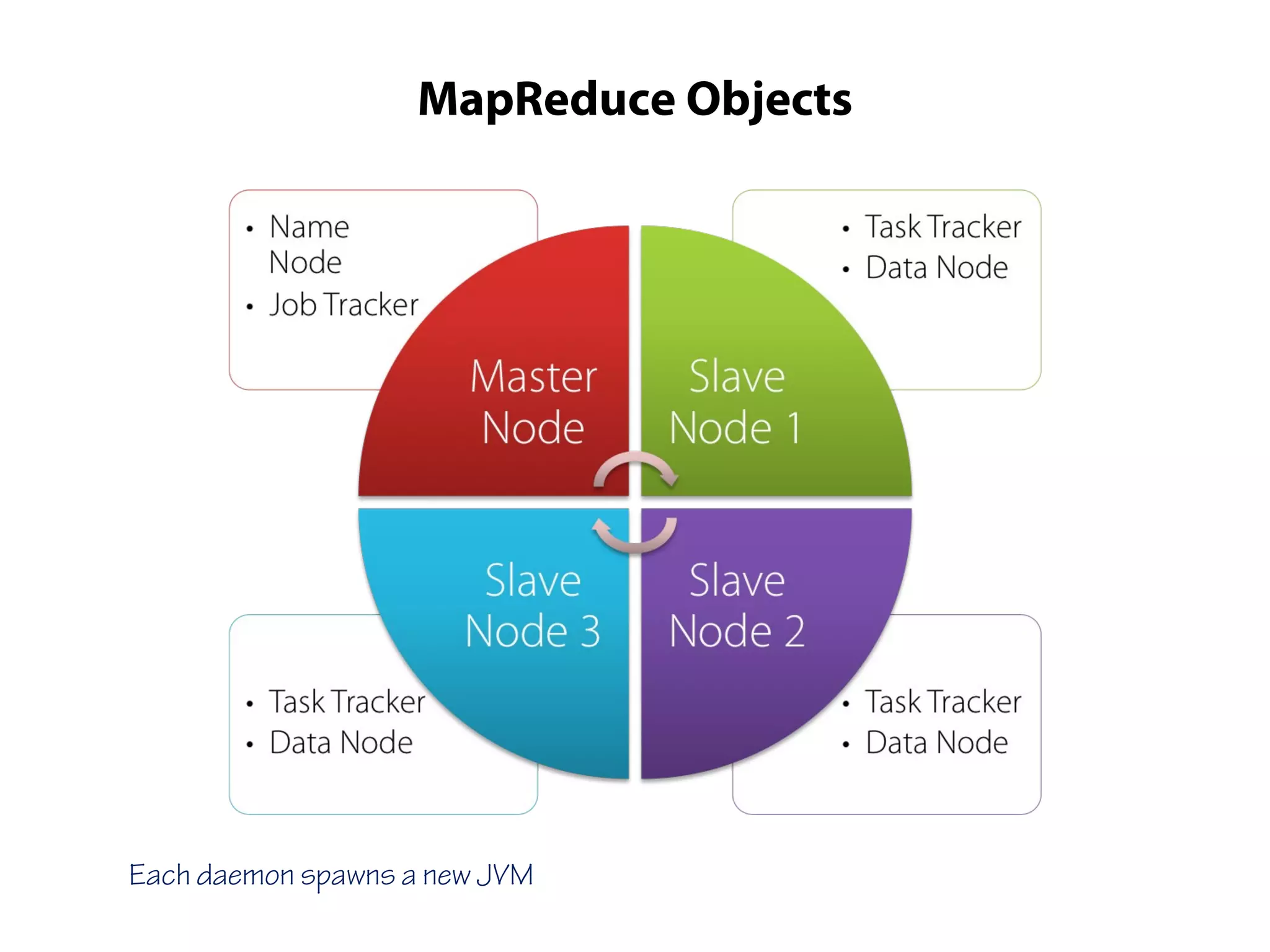

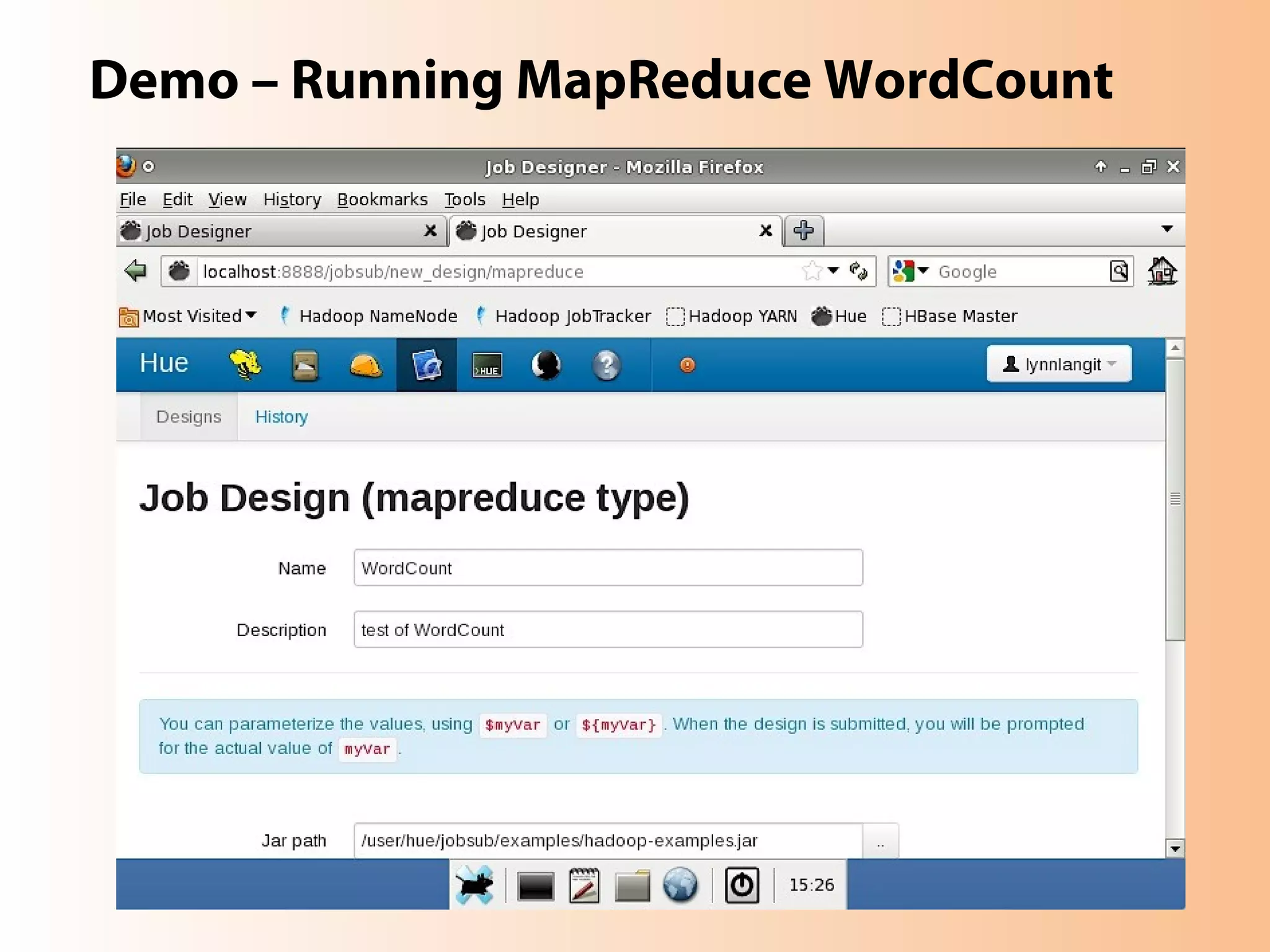



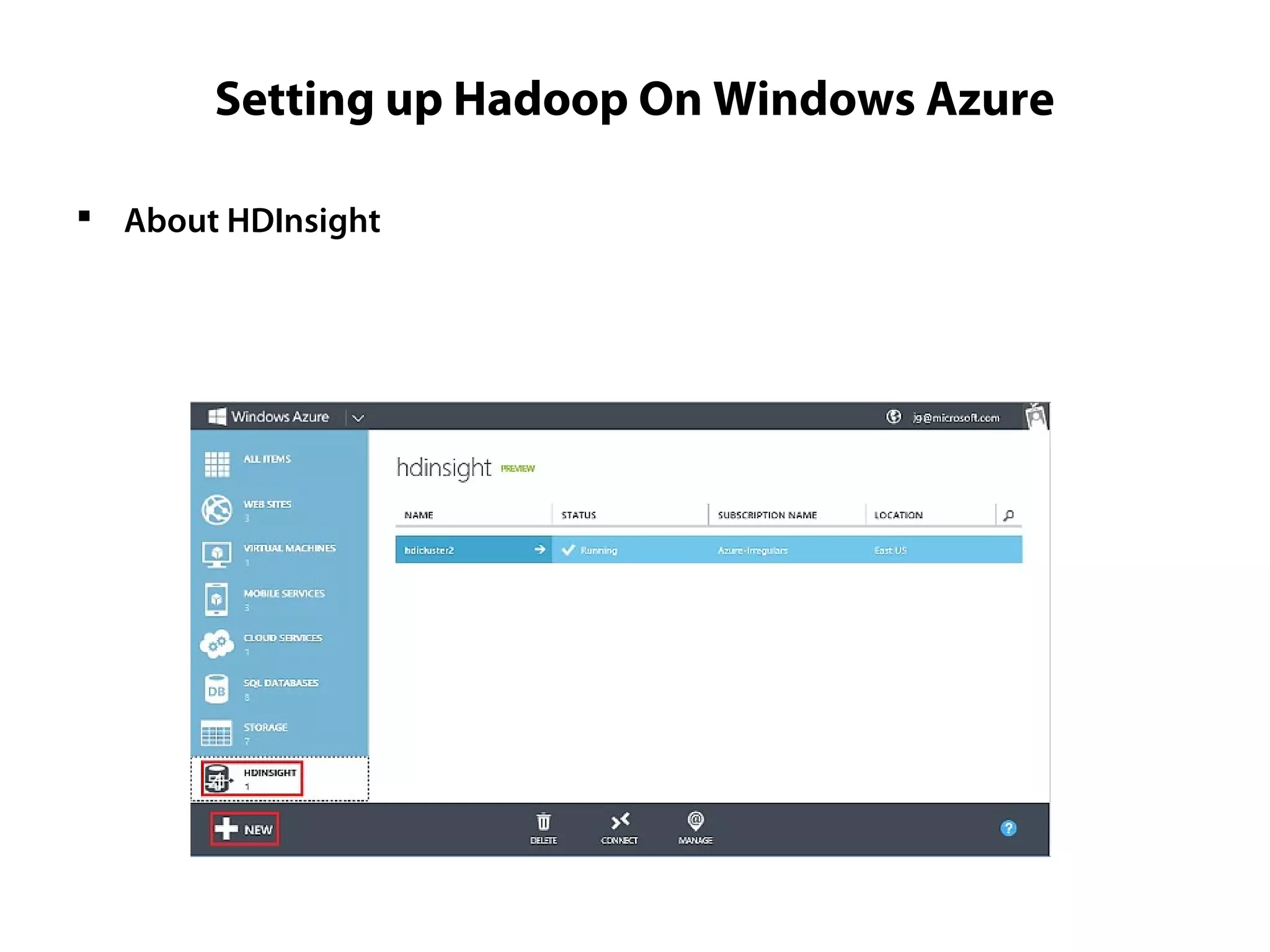



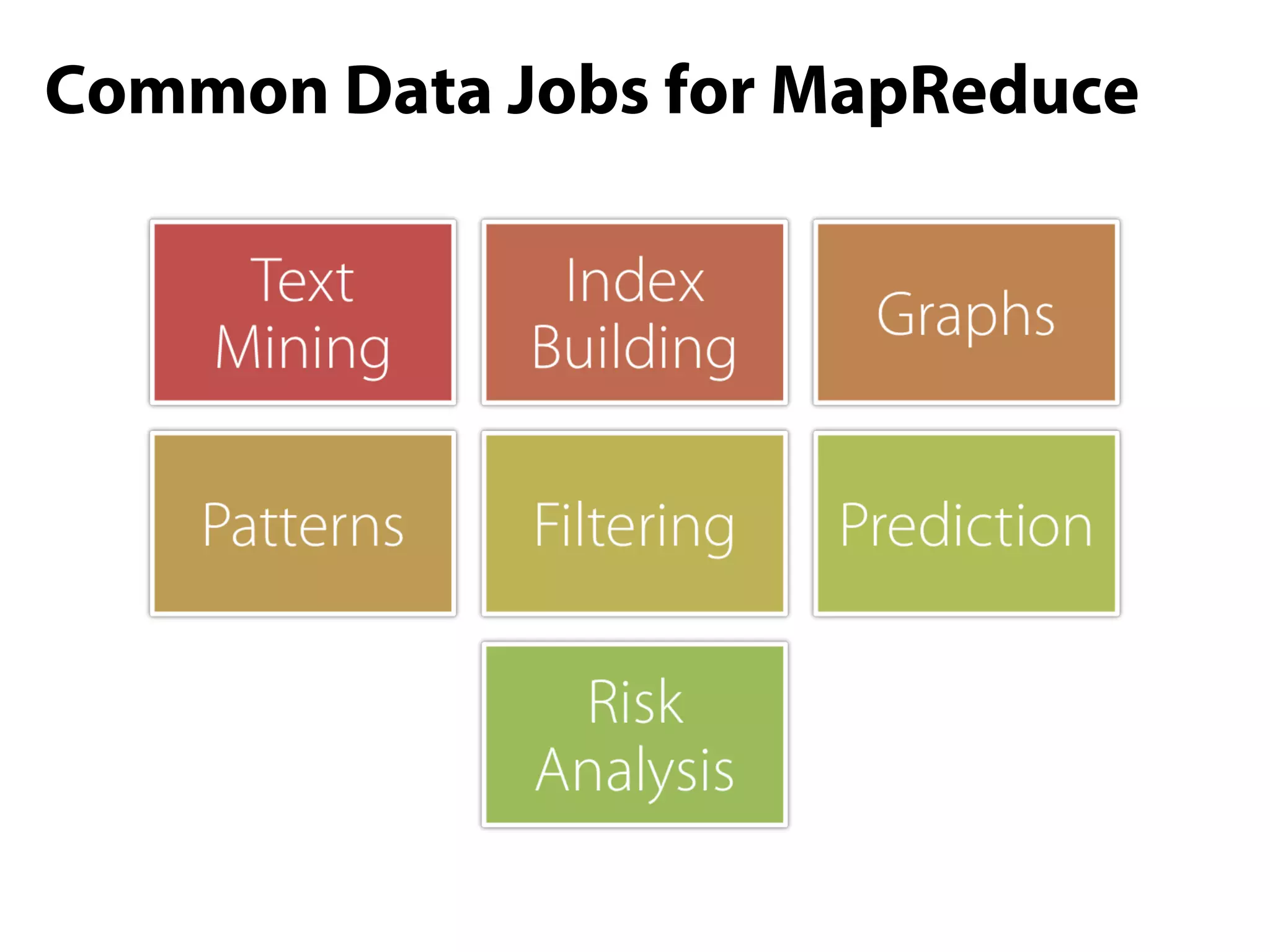





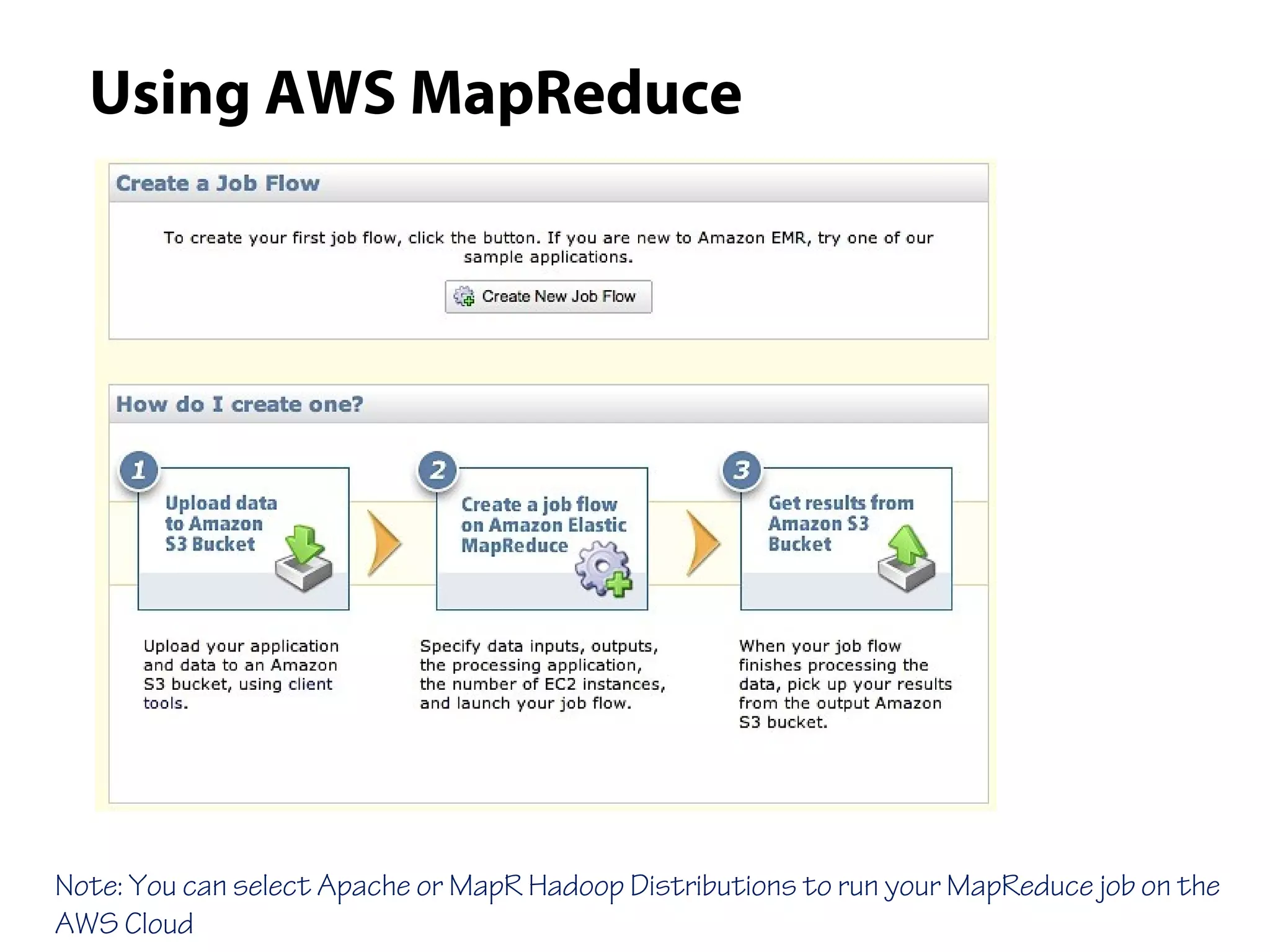


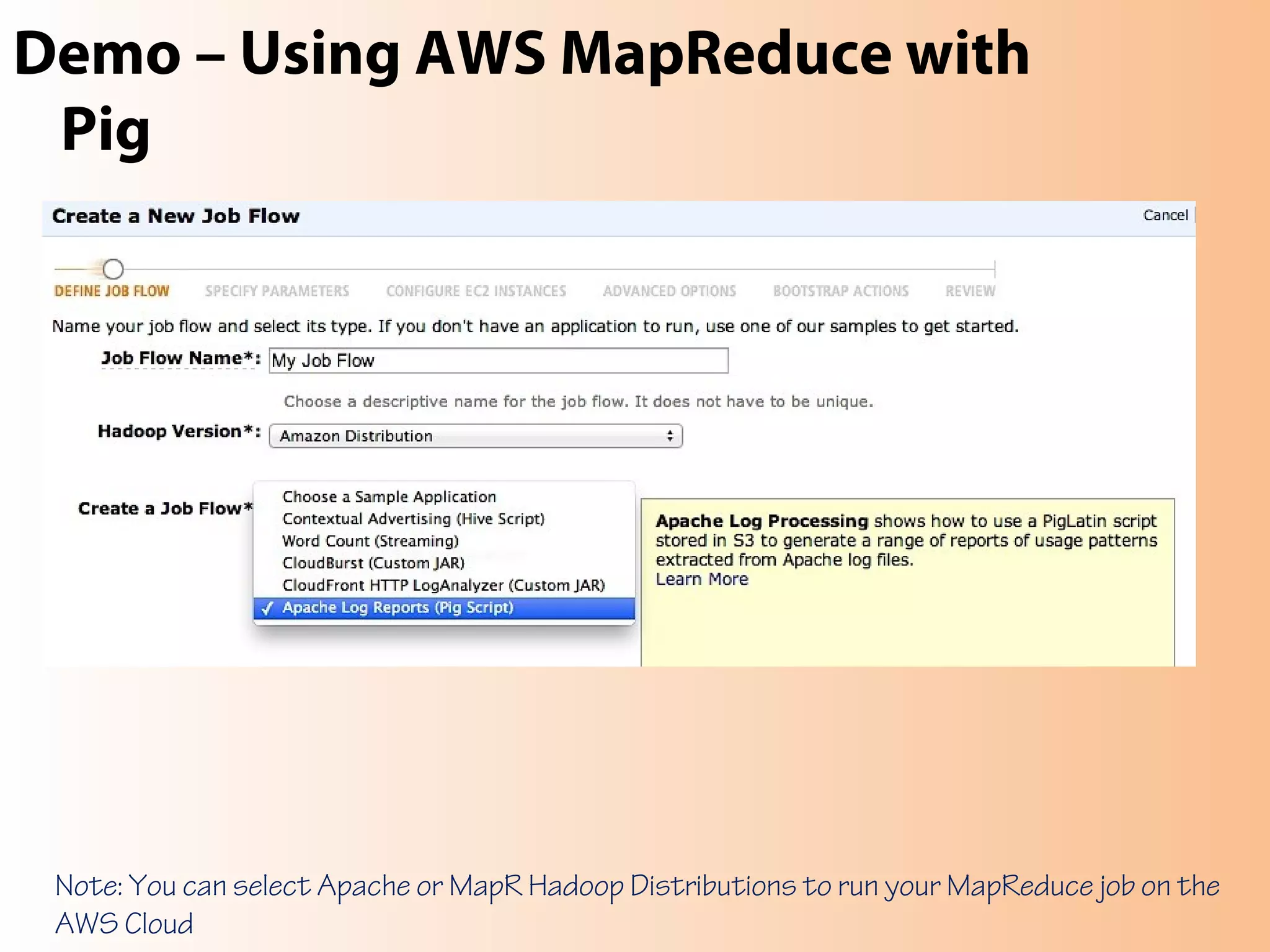
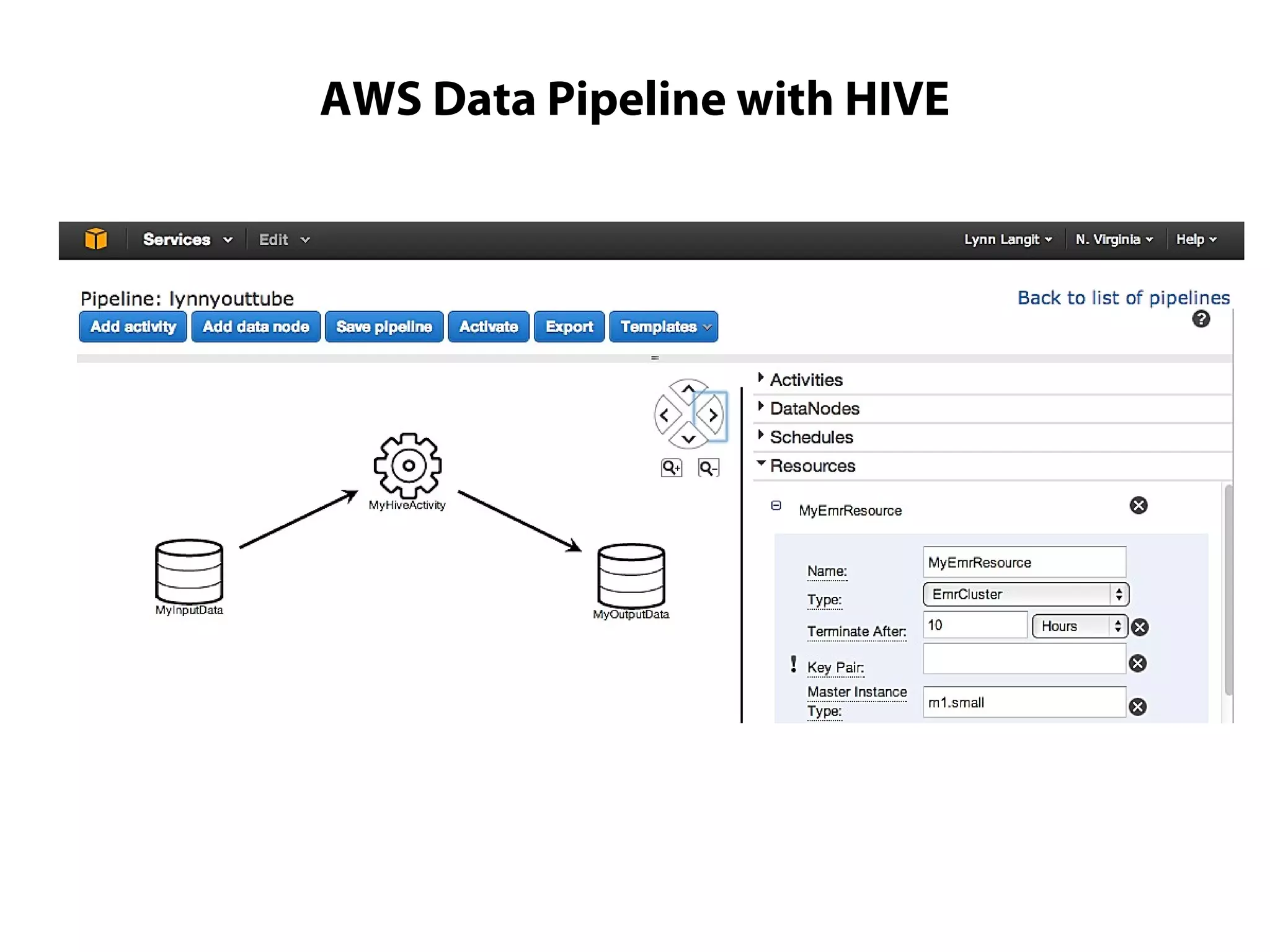

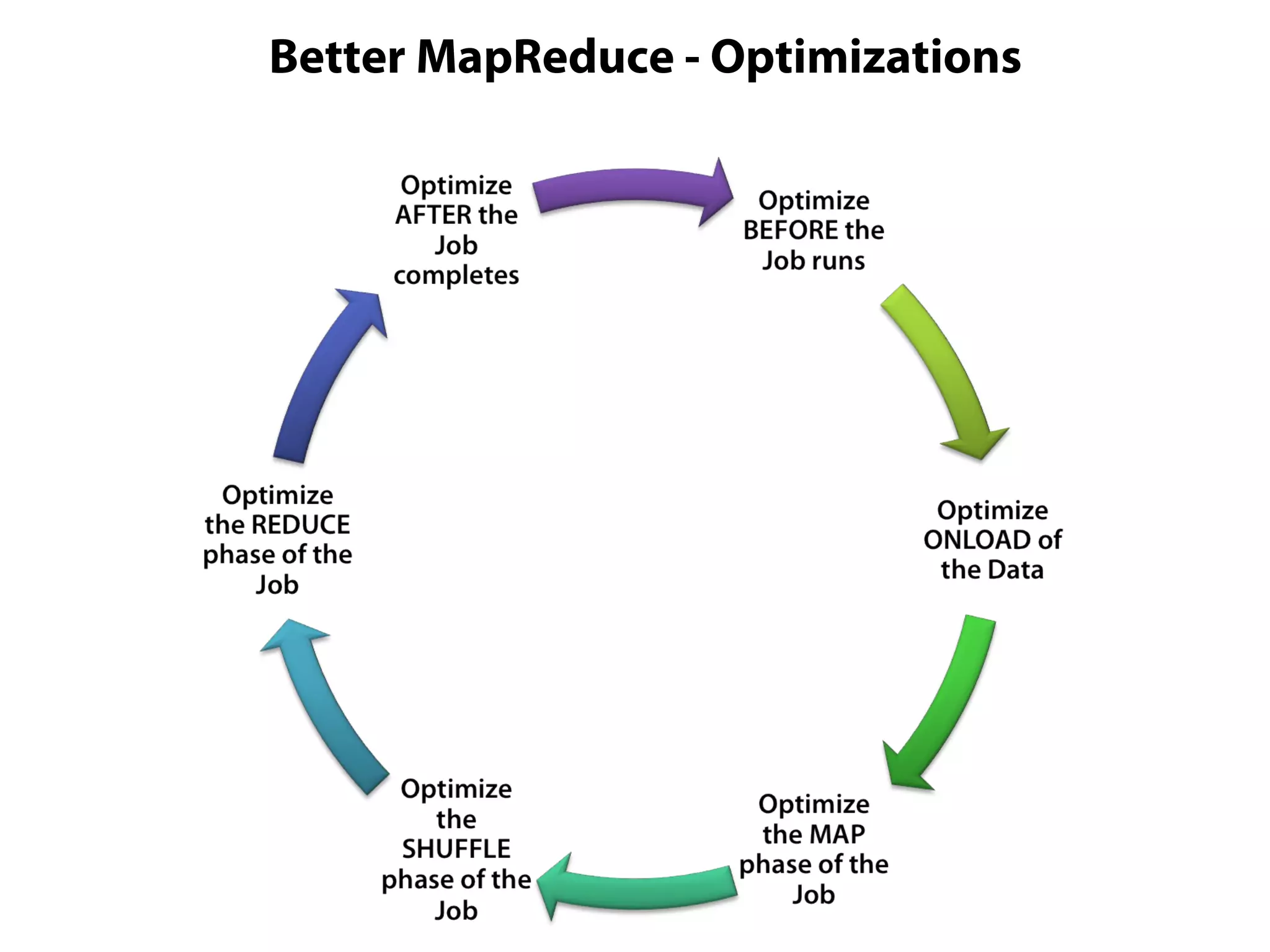
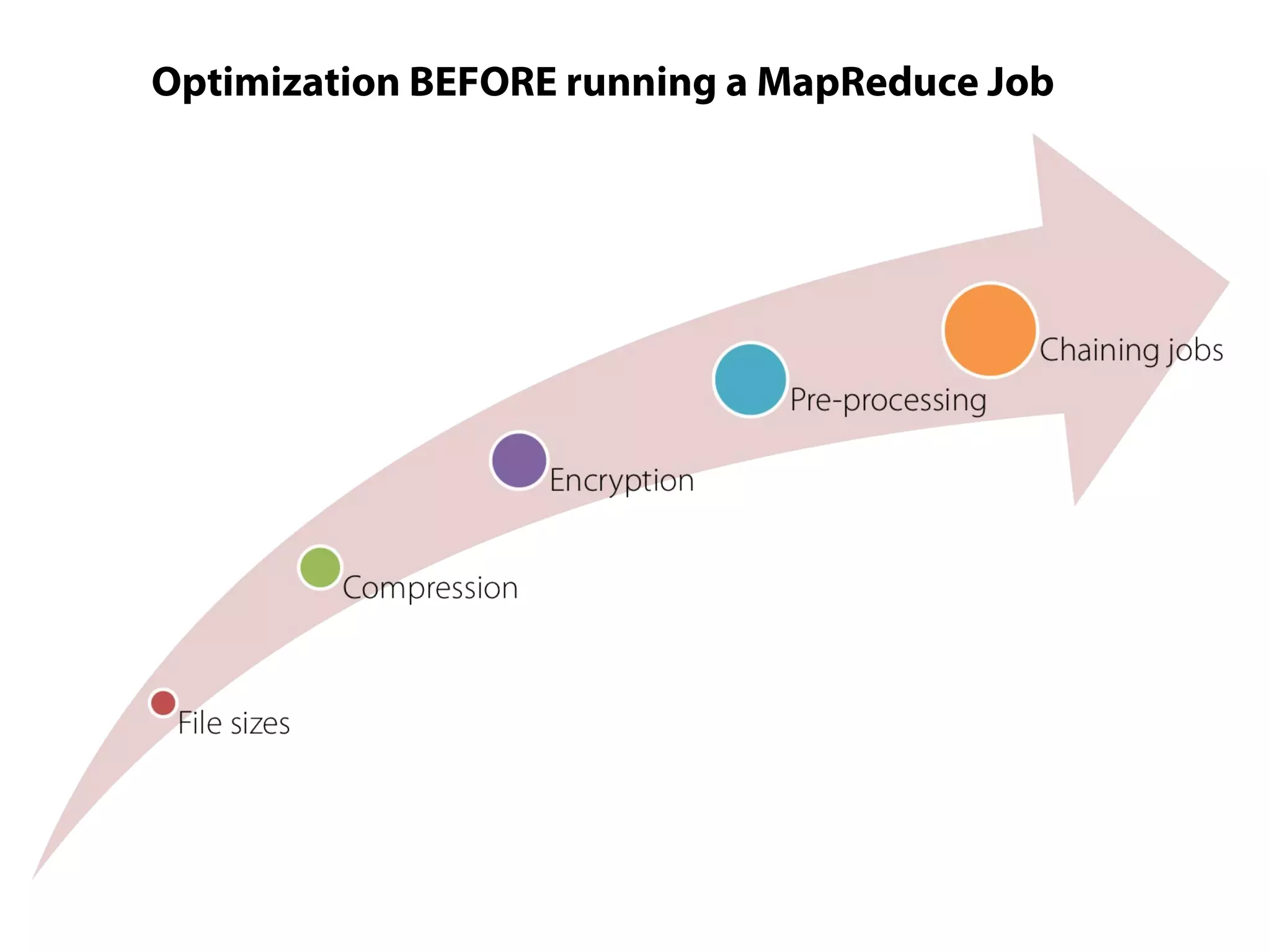

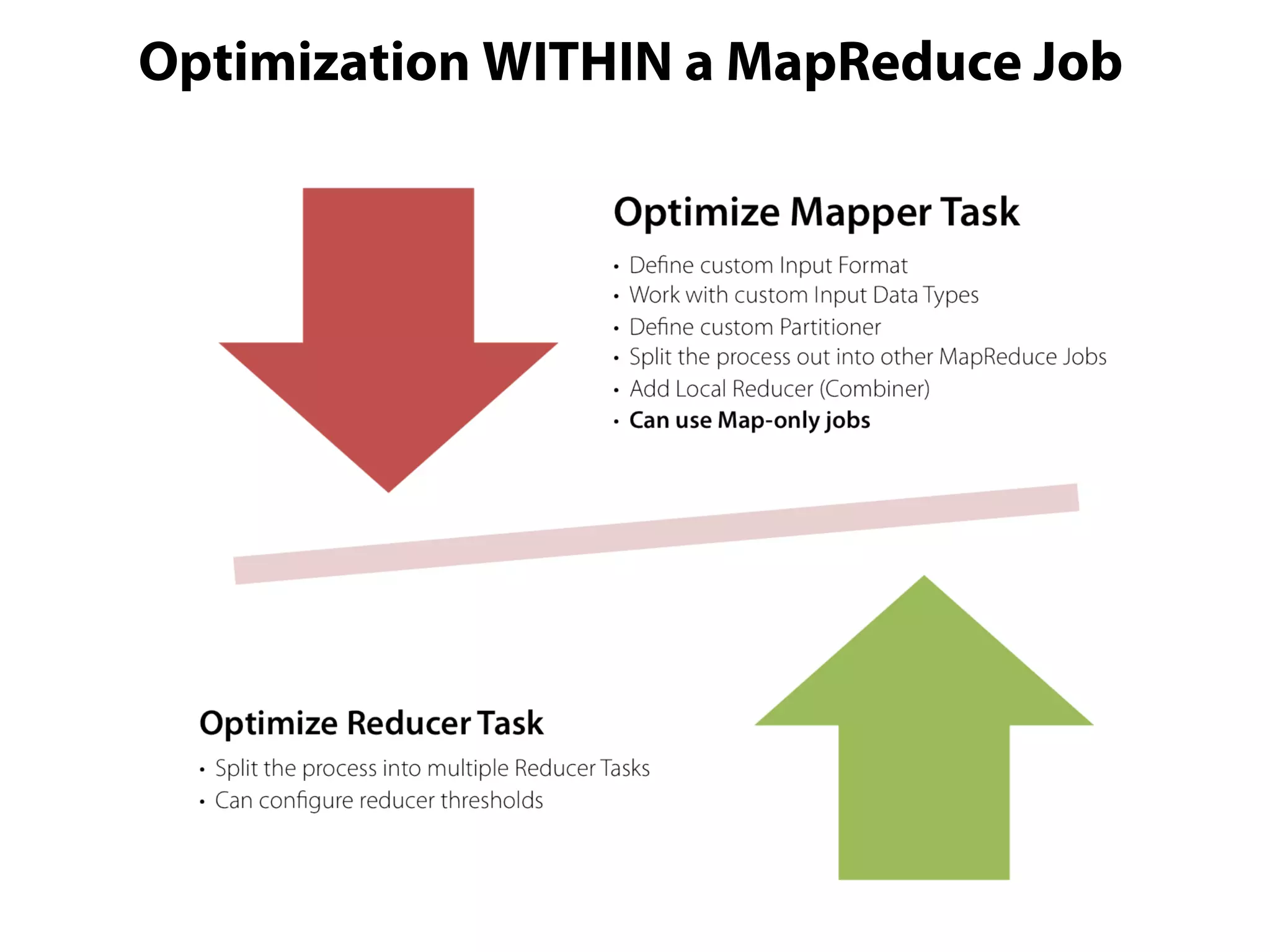
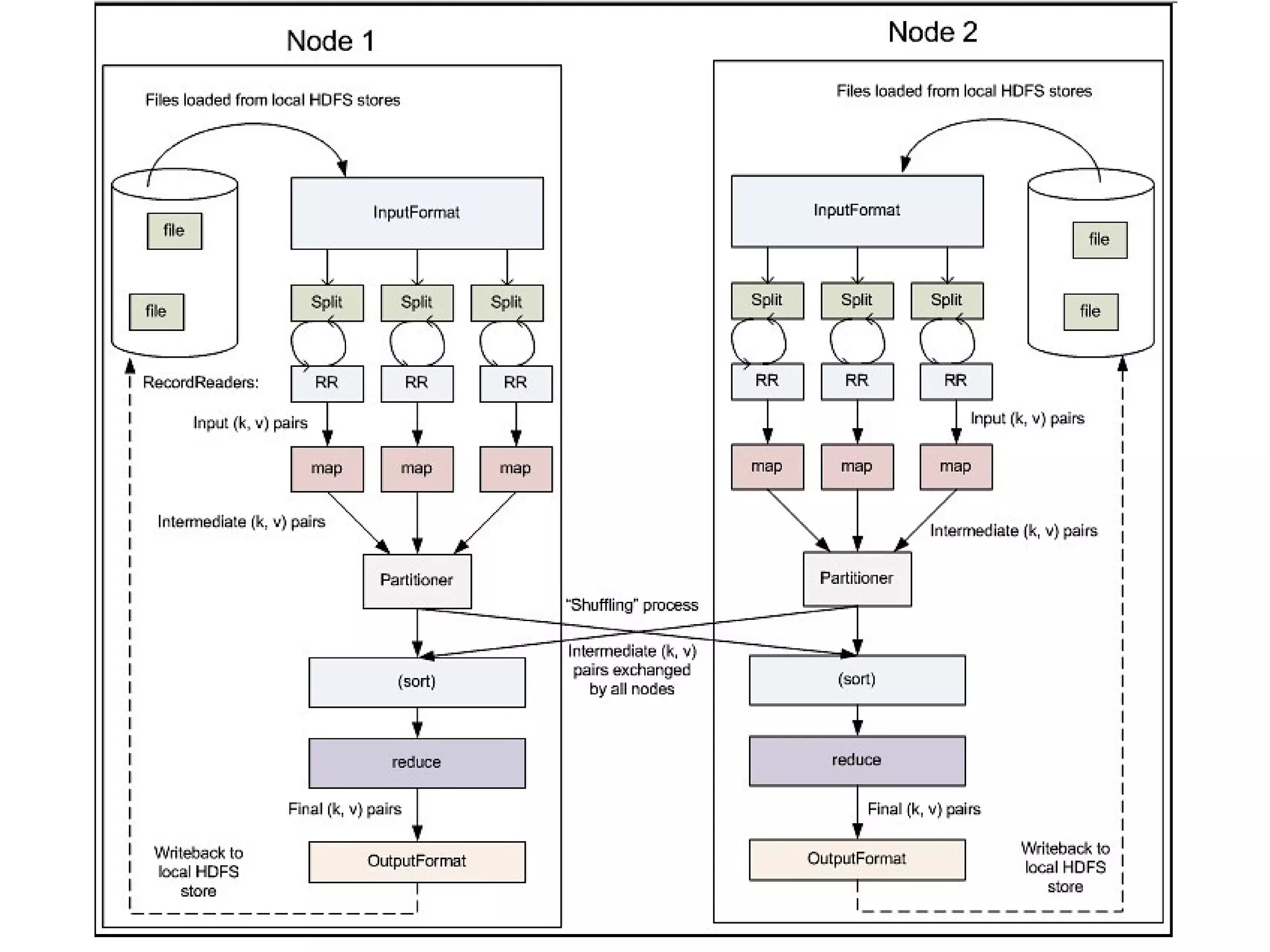


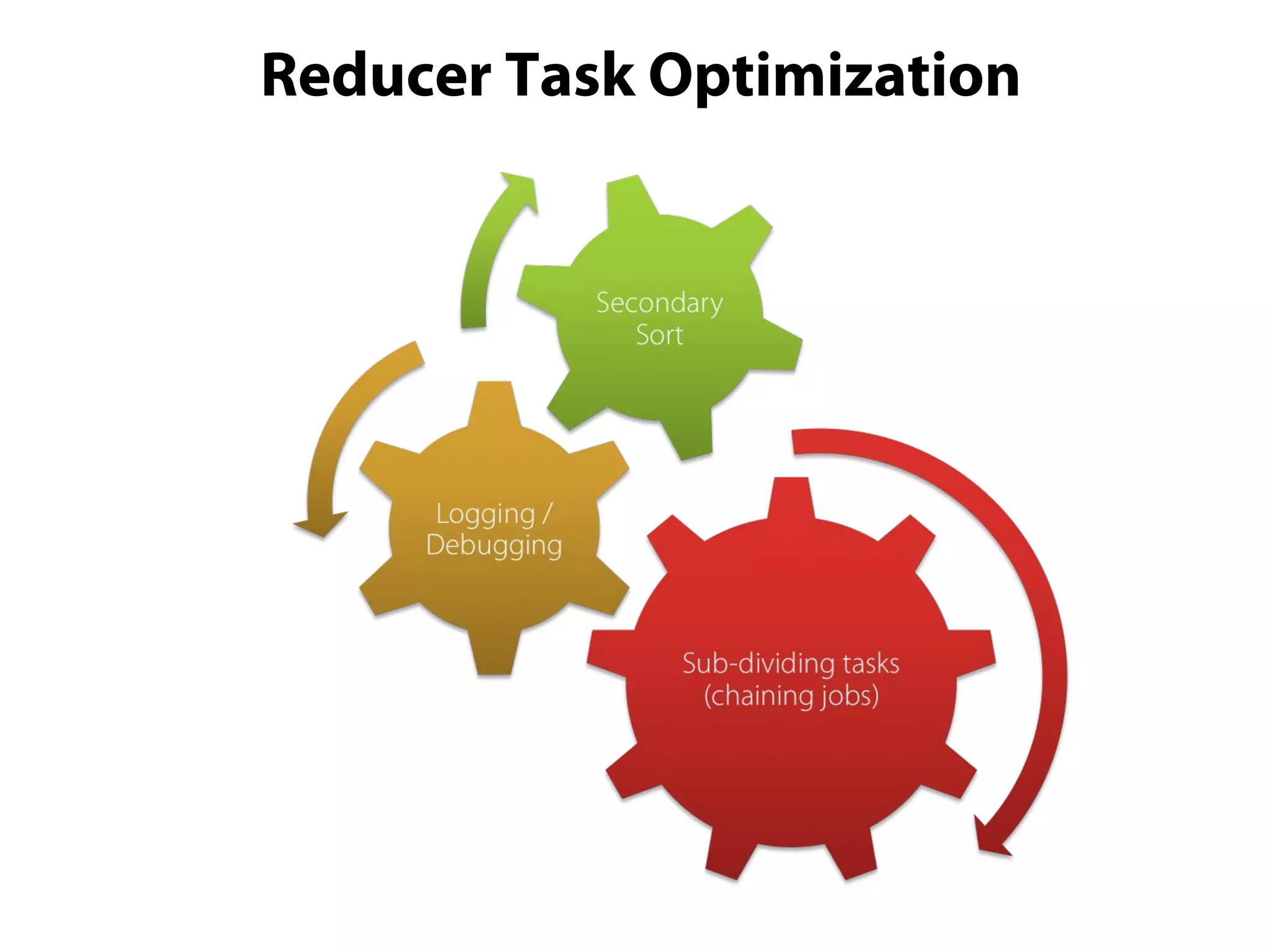
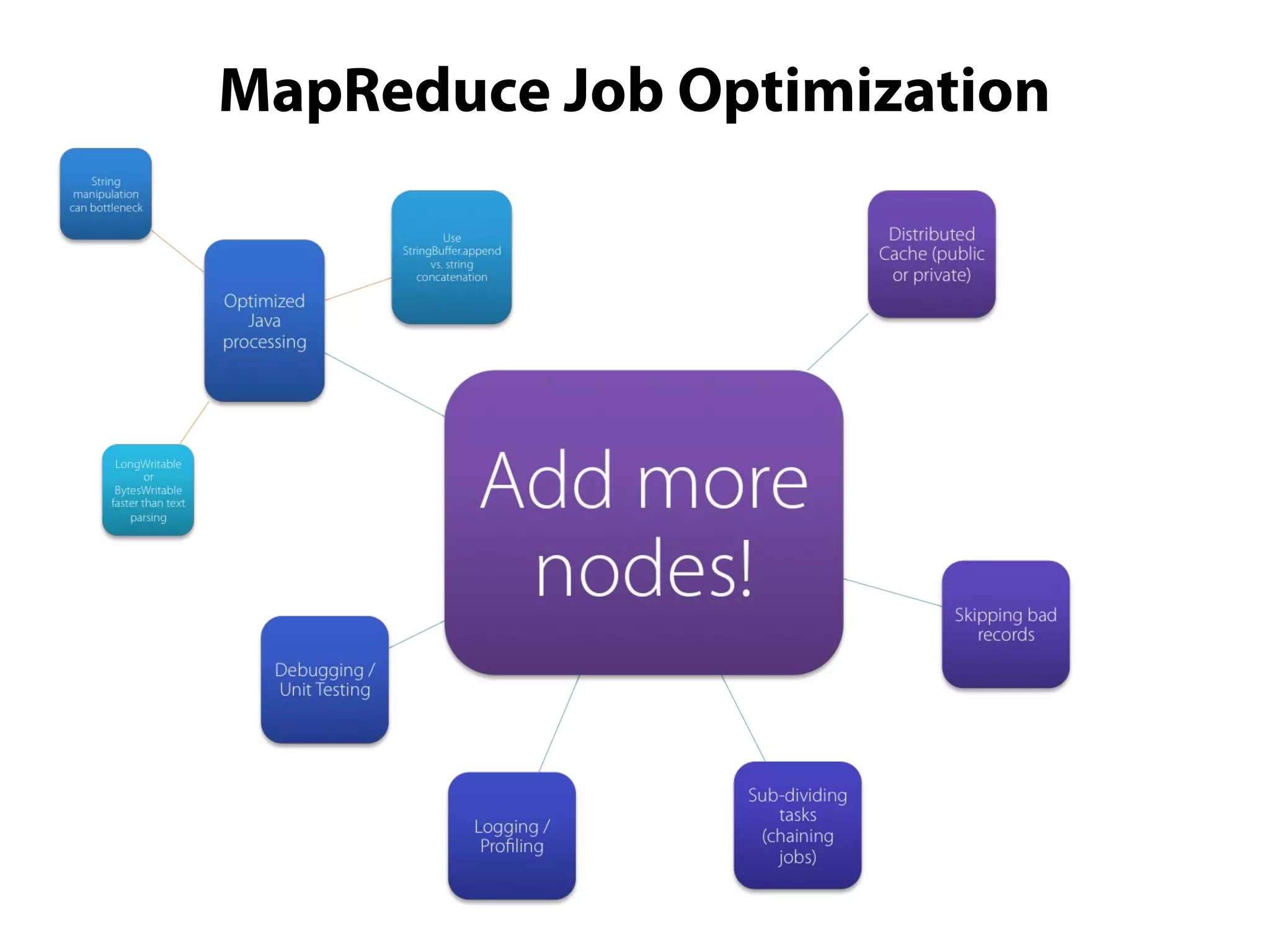




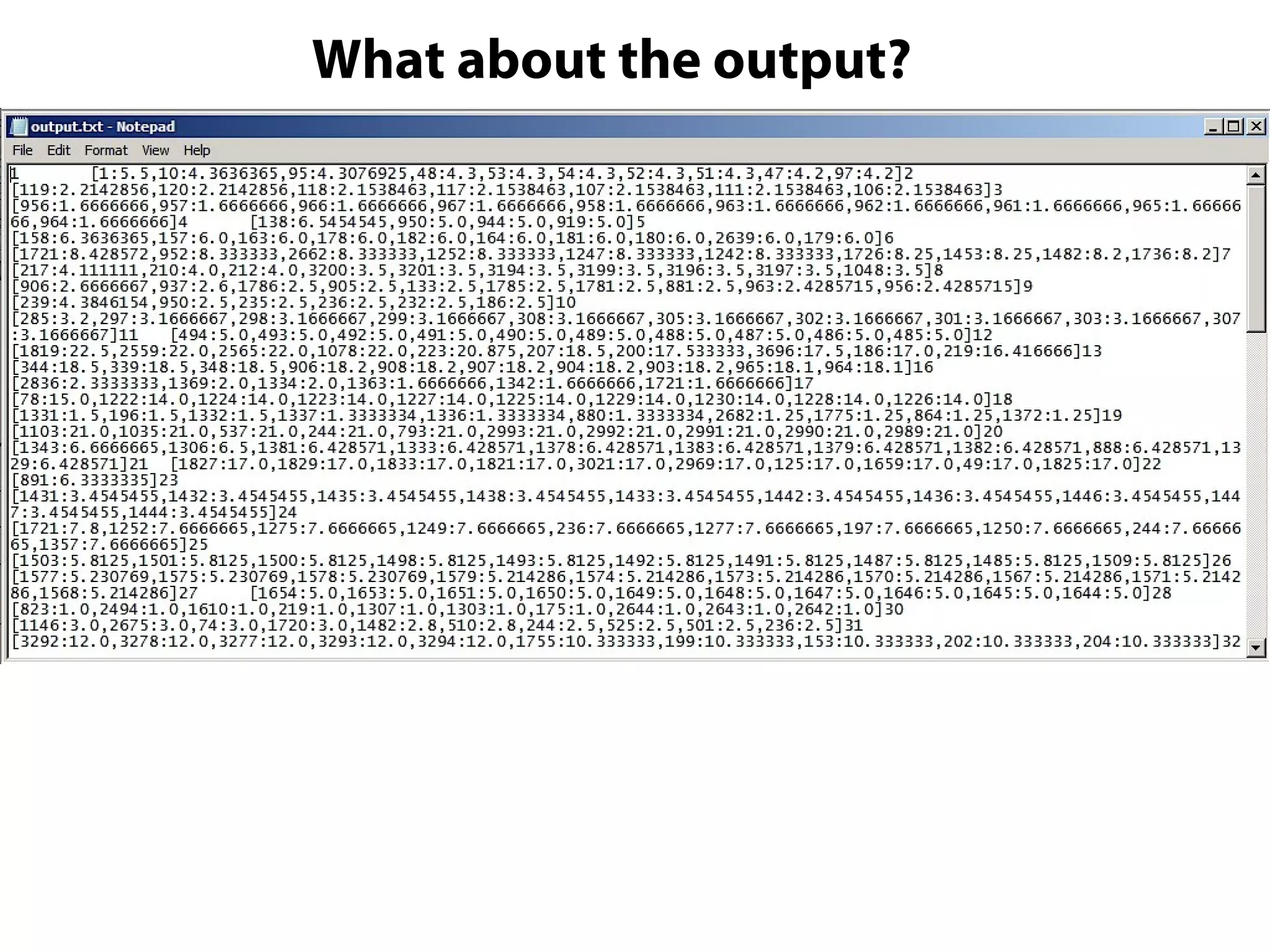

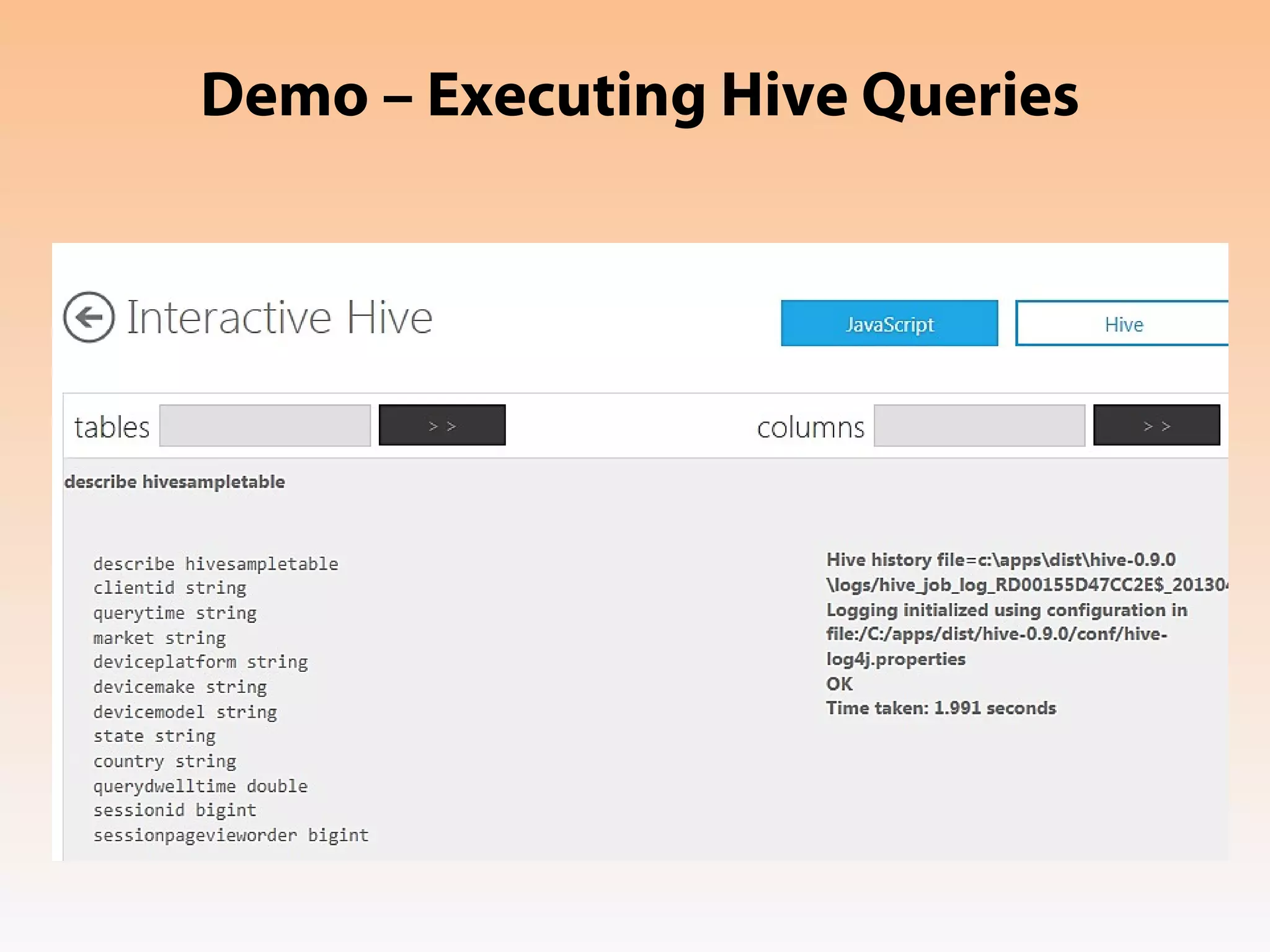
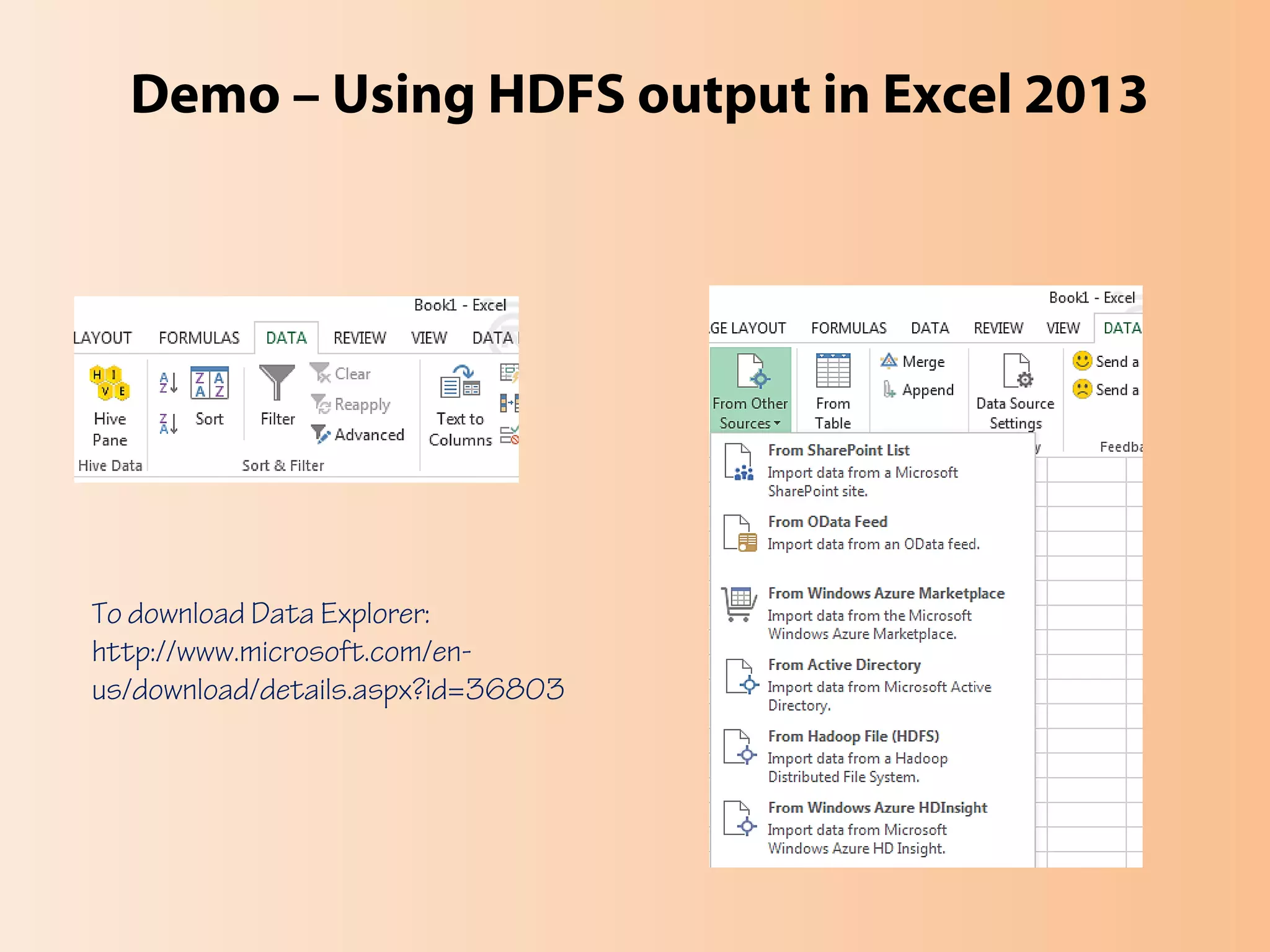


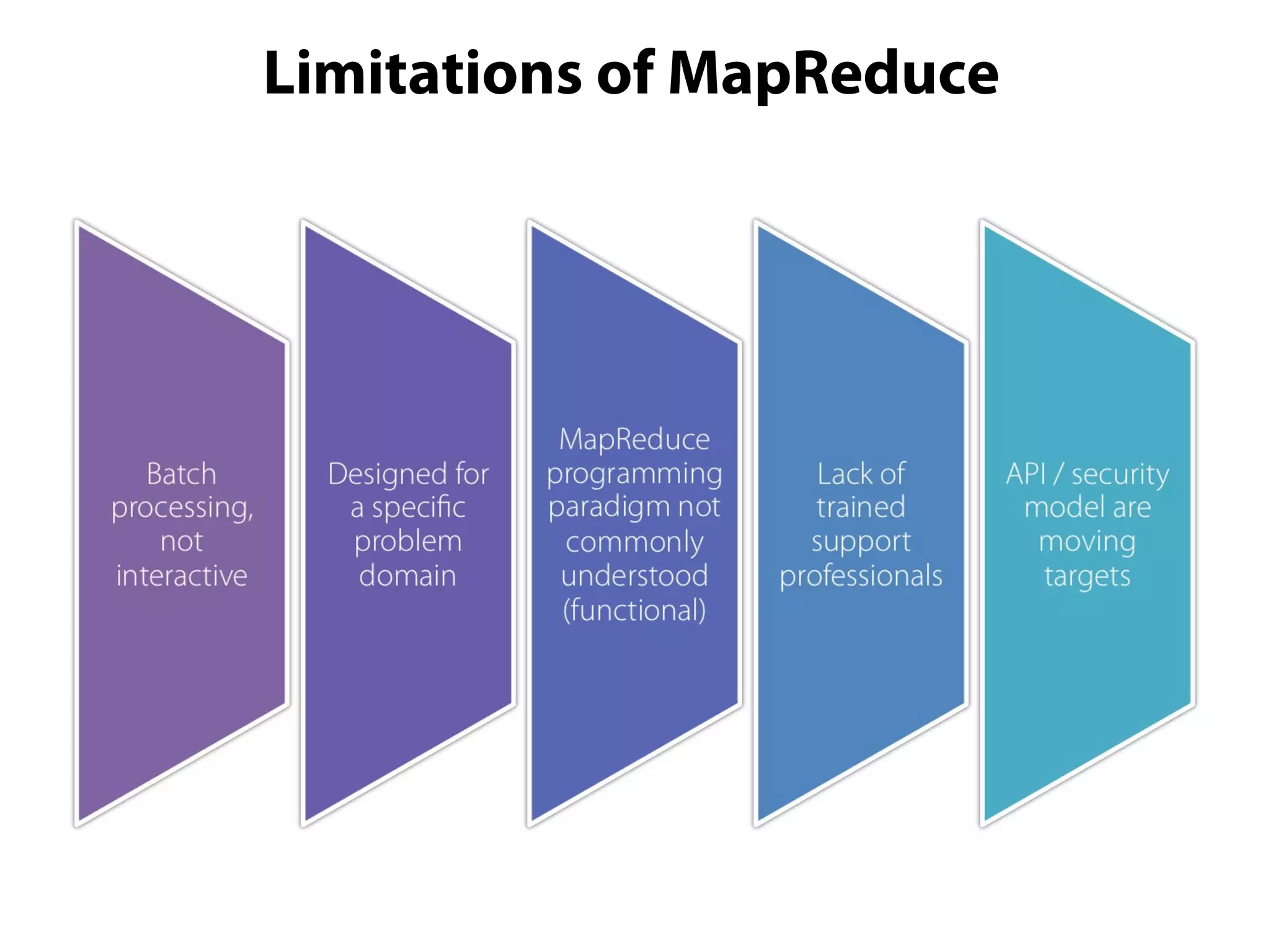

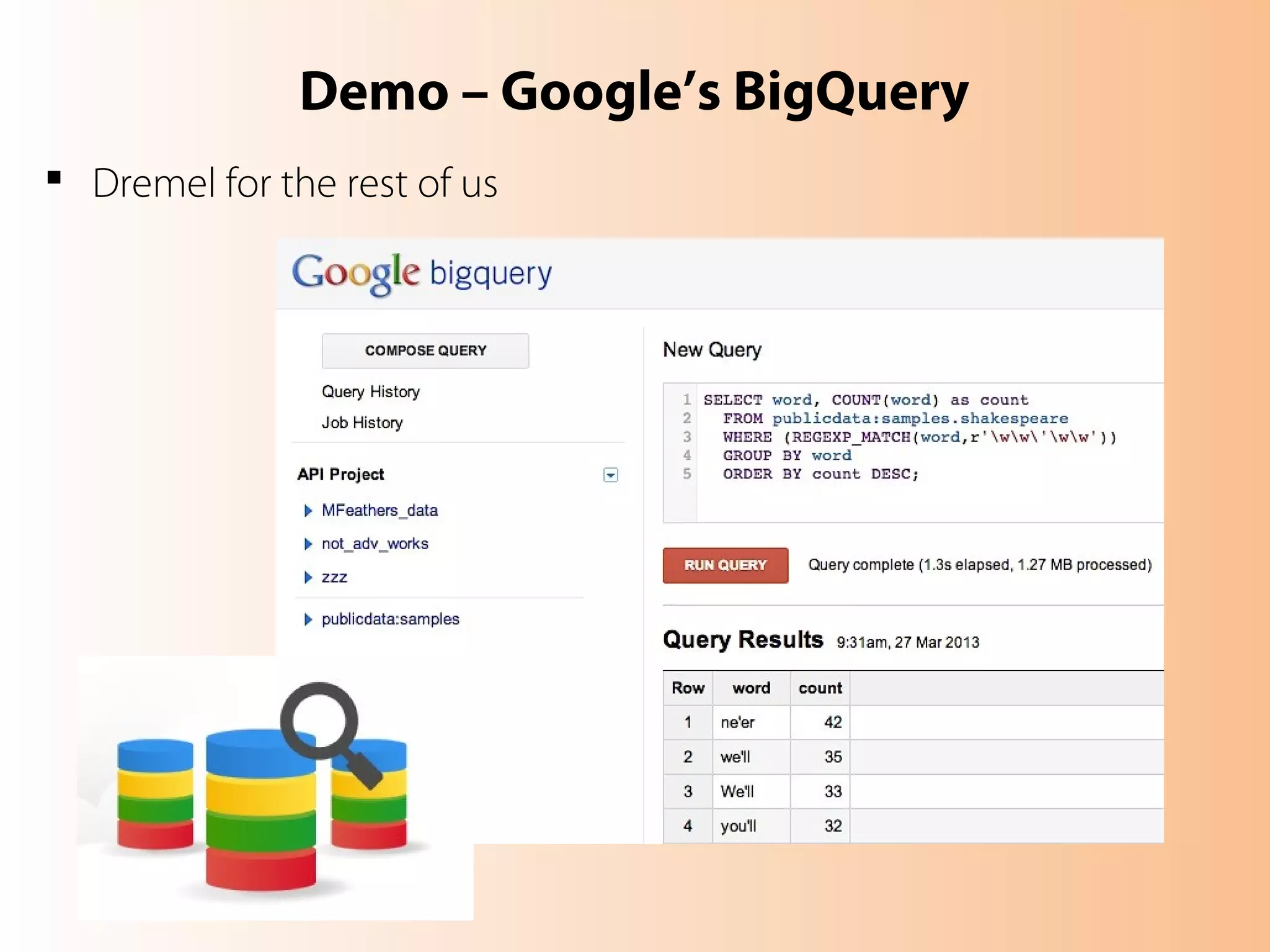


This document provides an overview of the Hadoop MapReduce Fundamentals course. It discusses what Hadoop is, why it is used, common business problems it can address, and companies that use Hadoop. It also outlines the core parts of Hadoop distributions and the Hadoop ecosystem. Additionally, it covers common MapReduce concepts like HDFS, the MapReduce programming model, and Hadoop distributions. The document includes several code examples and screenshots related to Hadoop and MapReduce.








































![[Sneak Preview] Apache Spark: Preparing for the next wave of Reactive Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/coll-report-typesafe-apache-spark-slide-share-150127023731-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













