Downloaded 67 times













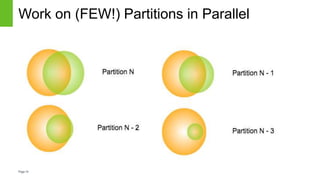







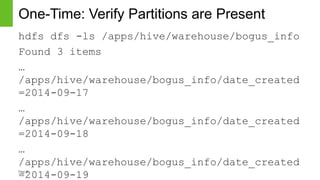





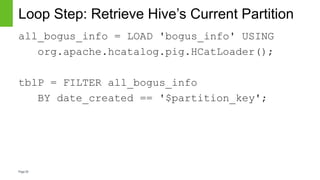








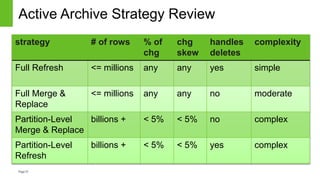





The document discusses strategies for managing mutable data within the immutable structure of Hive, emphasizing the importance of partitioning and refresh techniques for data ingestion. It outlines various methods such as full refresh, merge and replace, and partition-level strategies to ensure efficient handling of time-series immutable data in Hadoop. Additionally, it highlights the implications of using Hive's new insert, update, and delete features while offering recommendations for evaluating data workloads.























































































