Download as PDF, PPTX










![10
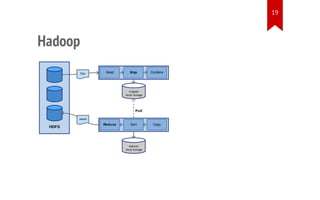
MapReduce Stages
data
source
data
source
data
source
data
source
map
map
map
map
reduce
reduce
reduce
mp
a:
(nky i_a)i_e, nvl >
[otky otvl]
(u_e, u_a)
rdc:
eue
(u_e,[u_a] otky otvl) >
[e_a]
rsvl](https://image.slidesharecdn.com/hadoopindatawarehousing-140124060739-phpapp01/85/Hadoop-in-Data-Warehousing-10-320.jpg)


![13
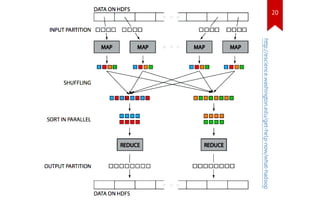
MapReduce Example
w
)1 ,w(
• reduce stage: for each
pairs into
)]1 , . . . ,1 ,1[ ,w(
• group a list of
w
• map stage: output 1 for each word
calculate how many ones there are](https://image.slidesharecdn.com/hadoopindatawarehousing-140124060739-phpapp01/85/Hadoop-in-Data-Warehousing-13-320.jpg)





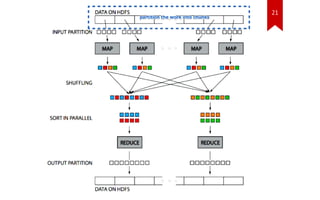
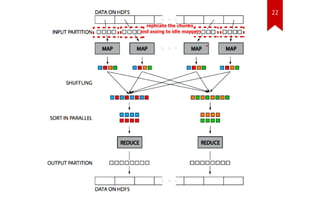



![30
Disadvantages
[Abouzeid, Azza et al 2009]](https://image.slidesharecdn.com/hadoopindatawarehousing-140124060739-phpapp01/85/Hadoop-in-Data-Warehousing-30-320.jpg)



















![51
References
1. Lee, Kyong-Ha, et al. "Parallel data processing with MapReduce: a survey." ACM SIGMOD Record 40.4 (2012): 11-20.
[pdf]
2. "MapReduce vs Data Warehouse". Webpage, [link]. Accessed 15/12/2013.
3. Ordonez, Carlos, Il-Yeol Song, and Carlos Garcia-Alvarado. "Relational versus non-relational database systems for
data warehousing." Proceedings of the ACM 13th international workshop on Data warehousing and OLAP. ACM, 2010.
[pdf]
4. A. Awadallah, D. Graham. "Hadoop and the Data Warehouse: When to Use Which." (2011). [pdf] (by Cloudera and
Teradata)
5. Thusoo, Ashish, et al. "Hive: a warehousing solution over a map-reduce framework." Proceedings of the VLDB
Endowment 2.2 (2009): 1626-1629. [pdf]
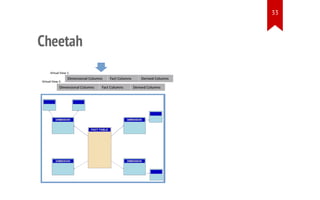
6. Chen, Songting. "Cheetah: a high performance, custom data warehouse on top of MapReduce." Proceedings of the
VLDB Endowment 3.1-2 (2010): 1459-1468. [pdf]](https://image.slidesharecdn.com/hadoopindatawarehousing-140124060739-phpapp01/85/Hadoop-in-Data-Warehousing-51-320.jpg)
![52
References
7. "How (and Why) Hadoop is Changing the Data Warehousing Paradigm." Webpage [link]. Accessed 15/12/2013.
8. P. Russom. "Integrating Hadoop into Business Intelligence and Data Warehousing." (2013). [pdf]
9. M. Ferguson. "Offloading and Accelerating Data Warehouse ETL Processing Using Hadoop." [pdf]
10. Dean, Jeffrey, and Sanjay Ghemawat. "MapReduce: simplified data processing on large clusters." Communications of
the ACM 51.1 (2008): 107-113. [pdf]
11. "What is Hadoop?" Webpage [link]. Accessed 15/12/2013.
12. Apache Hadoop project home page, url: [link].
13. Apache HBase home page, [link].
14. Apache Mahout home page, [link].
15. "How Hadoop Cuts Big Data Costs" [link]. Accessed 05/01/2014.
16. "The Impact of Data Temperature on the Data Warehouse." whitepaper by Terradata (2012). [pdf]
17. Abouzeid, Azza, et al. "HadoopDB: an architectural hybrid of MapReduce and DBMS technologies for analytical
workloads." Proceedings of the VLDB Endowment 2.1 (2009): 922-933. [pdf]](https://image.slidesharecdn.com/hadoopindatawarehousing-140124060739-phpapp01/85/Hadoop-in-Data-Warehousing-52-320.jpg)



The document discusses the role of Hadoop in data warehousing, explaining its origins, the MapReduce framework, and its applications in processing large datasets. It highlights the advantages and disadvantages of using Hadoop, alongside its integration with data warehouses for ETL processes and analytical purposes. Additionally, the presentation covers tools like Hive and Cheetah, outlining their respective functionalities in data analysis and storage.







![[DSC 2016] 系列活動:李泳泉 / 星火燎原 - Spark 機器學習初探](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmllib-161026052038-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































































