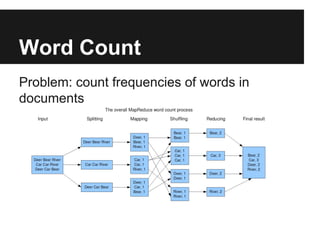
The document discusses the MapReduce programming model, specifically its application in analyzing user data through functions like word count, sessionization, and product recommendations using Python's mrjob library. It describes various data processing tasks, including counting word frequencies, collating user activity into sessions, and generating purchase recommendations based on user behavior. The document also includes sample outputs for various methods and tools used in the ecommerce context, providing insights into user statistics and metrics.










![Sample Output
"998" ["1384389407", "1384389417", "1384389422",
"1384389425", "1384390407", "1384390417",
"1384391416", "1384392410", "1384392416",
"1384395420", "1384396405"]
"999" ["1384388414", "1384388425", "1384389419",
"1384389420", "1384390420", "1384391415",
"1384391418", "1384393413", "1384393425",
"1384394426", "1384395416", "1384396415",
"1384396422"]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-11-320.jpg)
![Segment into Sessions
MAX_SESSION_INACTIVITY = 60 * 5
...
def reducer(self, uid, timestamps):
timestamps = sorted(timestamps)
start_index = 0
for index, timestamp in enumerate(timestamps):
if index > 0:
if timestamp - timestamps[index-1] >
MAX_SESSION_INACTIVITY:
yield uid, timestamps[start_index:index]
start_index = index
yield uid, timestamps[start_index:]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-12-320.jpg)
![Sample Output
"999"[1384388414, 1384388425]
"999"[1384389419, 1384389420]
"999"[1384390420]
"999"[1384391415, 1384391418]
"999"[1384393413, 1384393425]
"999"[1384394426]
"999"[1384395416]
"999"[1384396415, 1384396422]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-13-320.jpg)


![Sample output
"8" ["5", 11]
"8" ["6", 19]
"8" ["7", 14]
"8" ["9", 11]
"9" ["1", 20]
"9" ["10", 22]
"9" ["11", 21]
"9" ["12", 13]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-16-320.jpg)
![Top Recommendations
def reducer(self, purchase_pair, occurrences):
p1, p2 = purchase_pair
yield p1, (sum(occurrences), p2)
def reducer_find_best_recos(self, p1, p2_occurrences):
top_products = sorted(p2_occurrences, reverse=True)[:5]
top_products = [p2 for occurrences, p2 in top_products]
yield p1, top_products
def steps(self):
return [self.mr(mapper=self.mapper, reducer=self.reducer),
self.mr(reducer=self.reducer_find_best_recos)]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-17-320.jpg)
![Sample Output
"7"
"8"
"9"
["15", "18", "17", "16", "3"]
["14", "15", "20", "6", "3"]
["15", "17", "19", "6", "3"]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-18-320.jpg)

![Sample Output
["9", "20"]
["9", "3"]
["9", "4"]
["9", "5"]
["9", "6"]
["9", "7"]
["9", "8"]
["9", "9"]
["8", "14", "13", "10", "1"]
["2", "4", "16", "11", "17"]
["3", "18", "11", "16", "15"]
["2", "1", "7", "18", "17"]
["12", "3", "2", "17", "16"]
["18", "5", "17", "1", "9"]
["20", "14", "13", "10", "4"]
["18", "7", "6", "5", "4"]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-20-320.jpg)





![Sample Output
["8", "average session length"] [99, 24463, 7968891]
["8", "conversion rate"] [99, 45, 45]
["9", "average session length"] [115, 29515, 10071591]
["9", "conversion rate"] [115, 55, 55]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-26-320.jpg)

![Sample Output
["9", 0, "average session length"] [32, 8405, 3031009]
["9", 0, "conversion rate"] [32, 20, 20]
["9", 1, "average session length"] [23, 5405, 1770785]
["9", 1, "conversion rate"] [23, 14, 14]
["9", 2, "average session length"] [39, 9481, 2965651]
["9", 2, "conversion rate"] [39, 20, 20]
["9", 3, "average session length"] [25, 6276, 2151014]
["9", 3, "conversion rate"] [25, 13, 13]
["9", 4, "average session length"] [27, 5721, 1797715]
["9", 4, "conversion rate"] [27, 16, 16]](https://image.slidesharecdn.com/mapreducebeyondwordcount-131120132222-phpapp02/85/Map-reduce-beyond-word-count-28-320.jpg)




































































