Download as KEY, PPTX



















































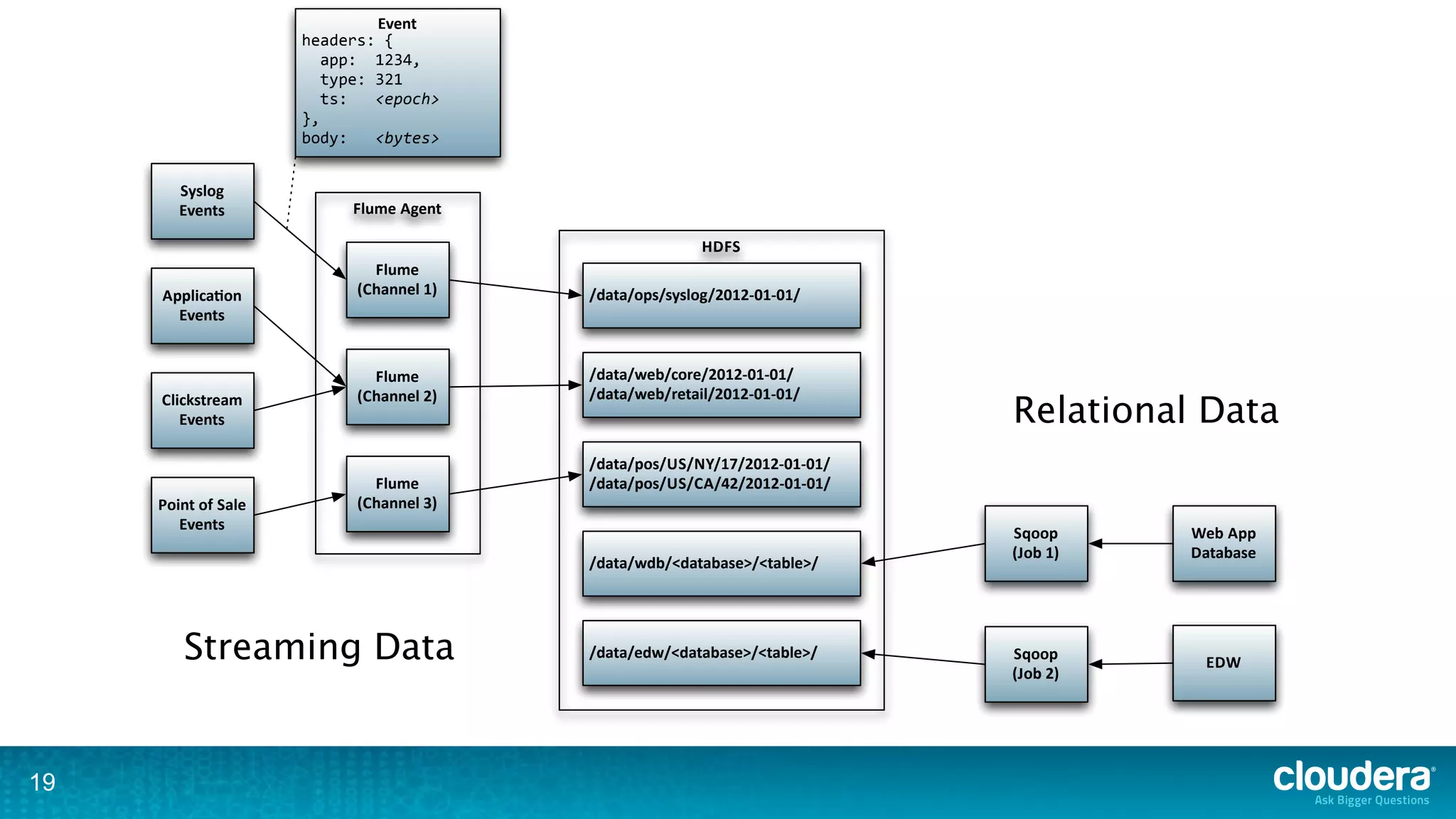








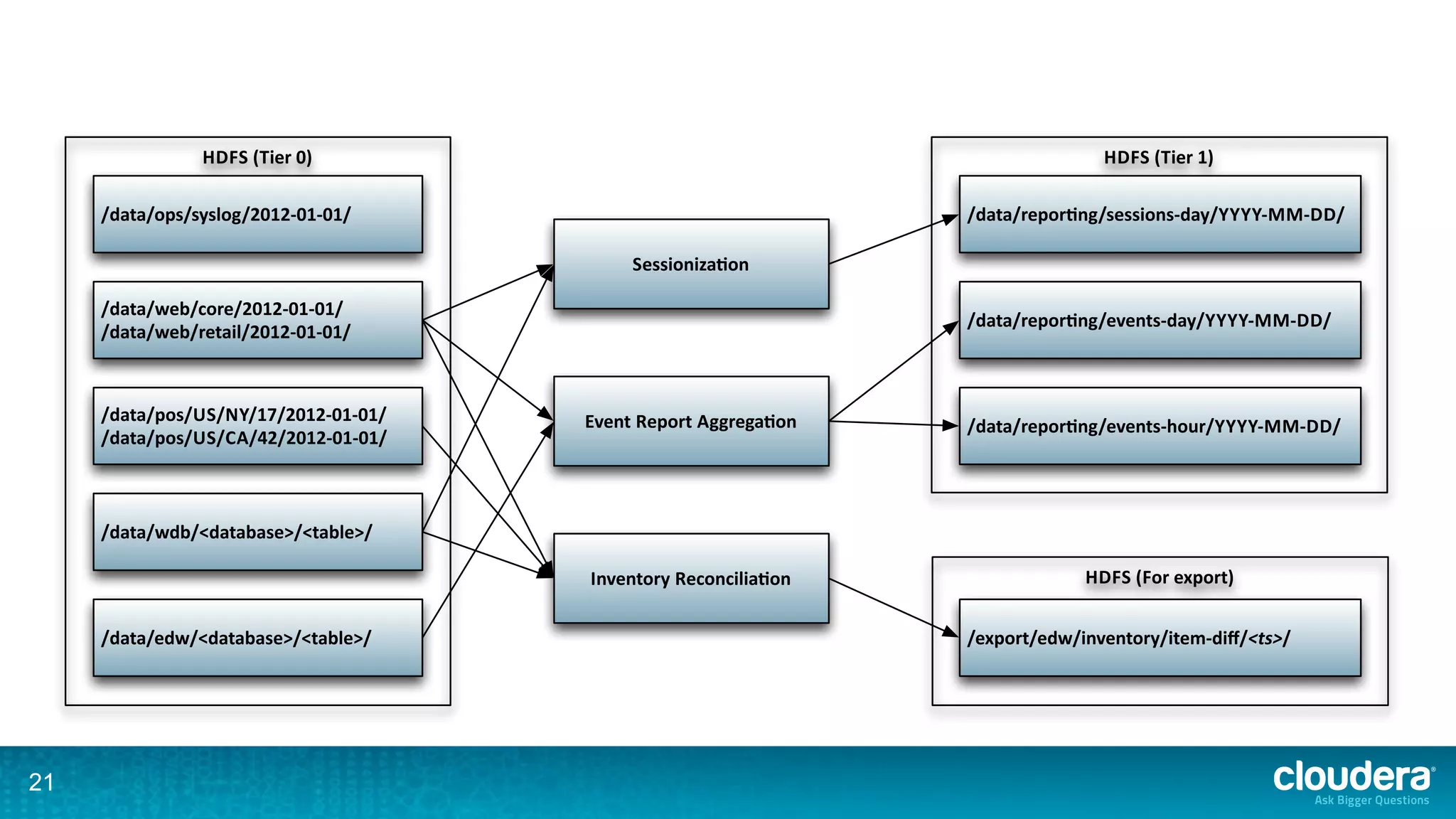















The document discusses the complexities of large-scale ETL processes using Hadoop, emphasizing the differences in definitions and challenges associated with data integration. It explores Hadoop's core components, including HDFS and MapReduce, as well as the ecosystem's tools for data processing and management, like Flume and Oozie. Additionally, it highlights the need for better structure, metadata management, and the separation of infrastructure from processes for scalable ETL solutions.





























































