






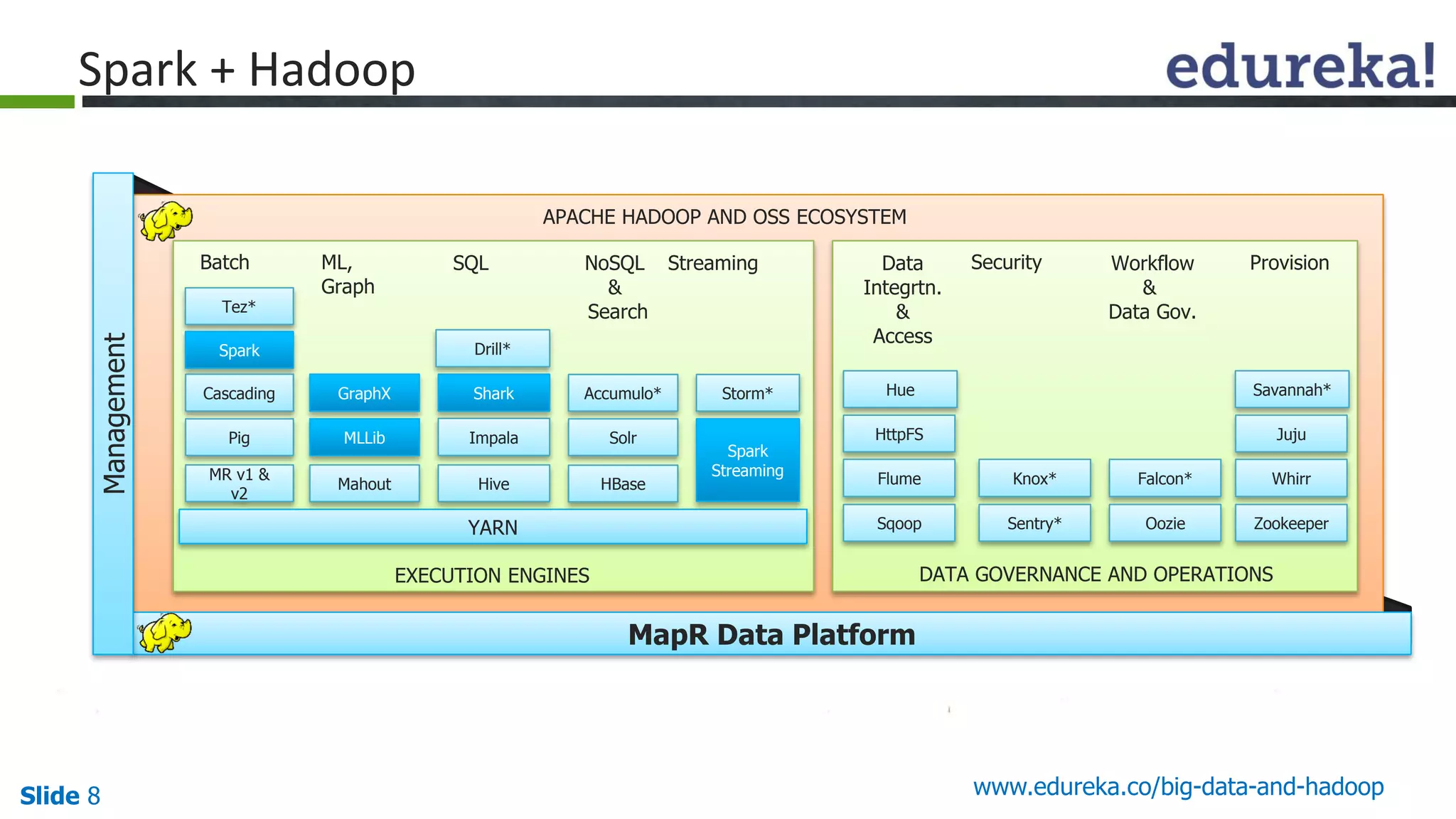
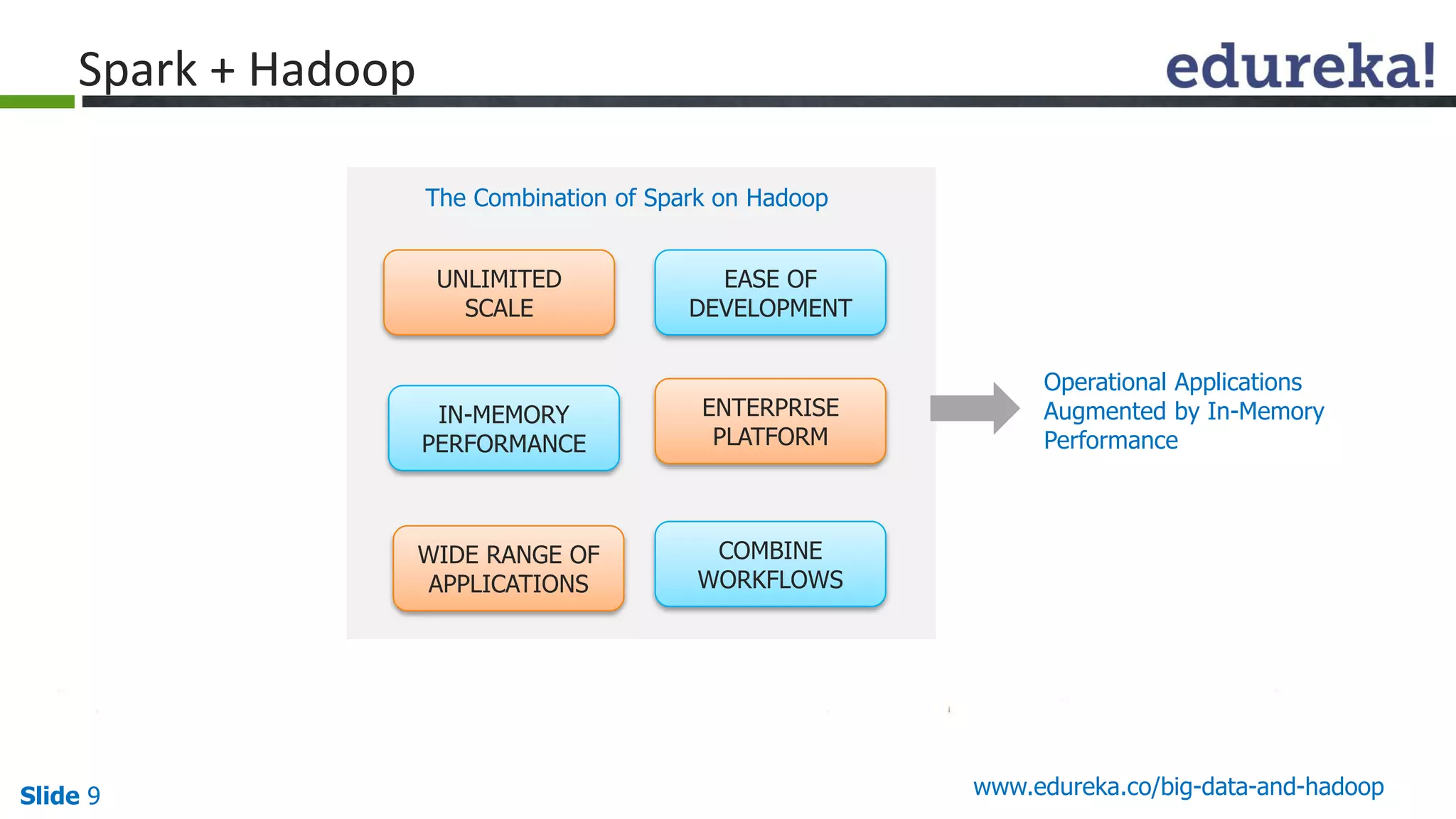


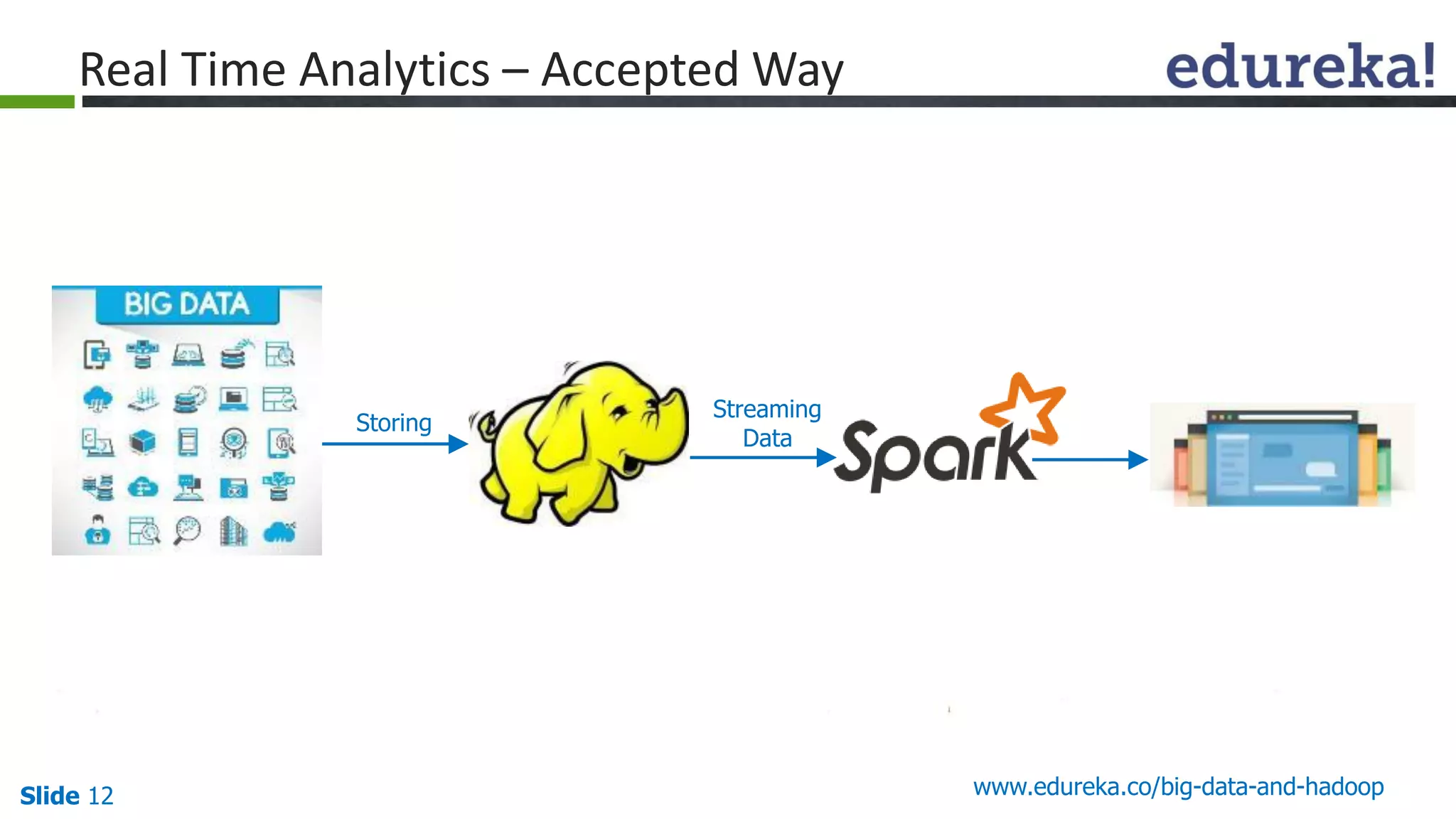
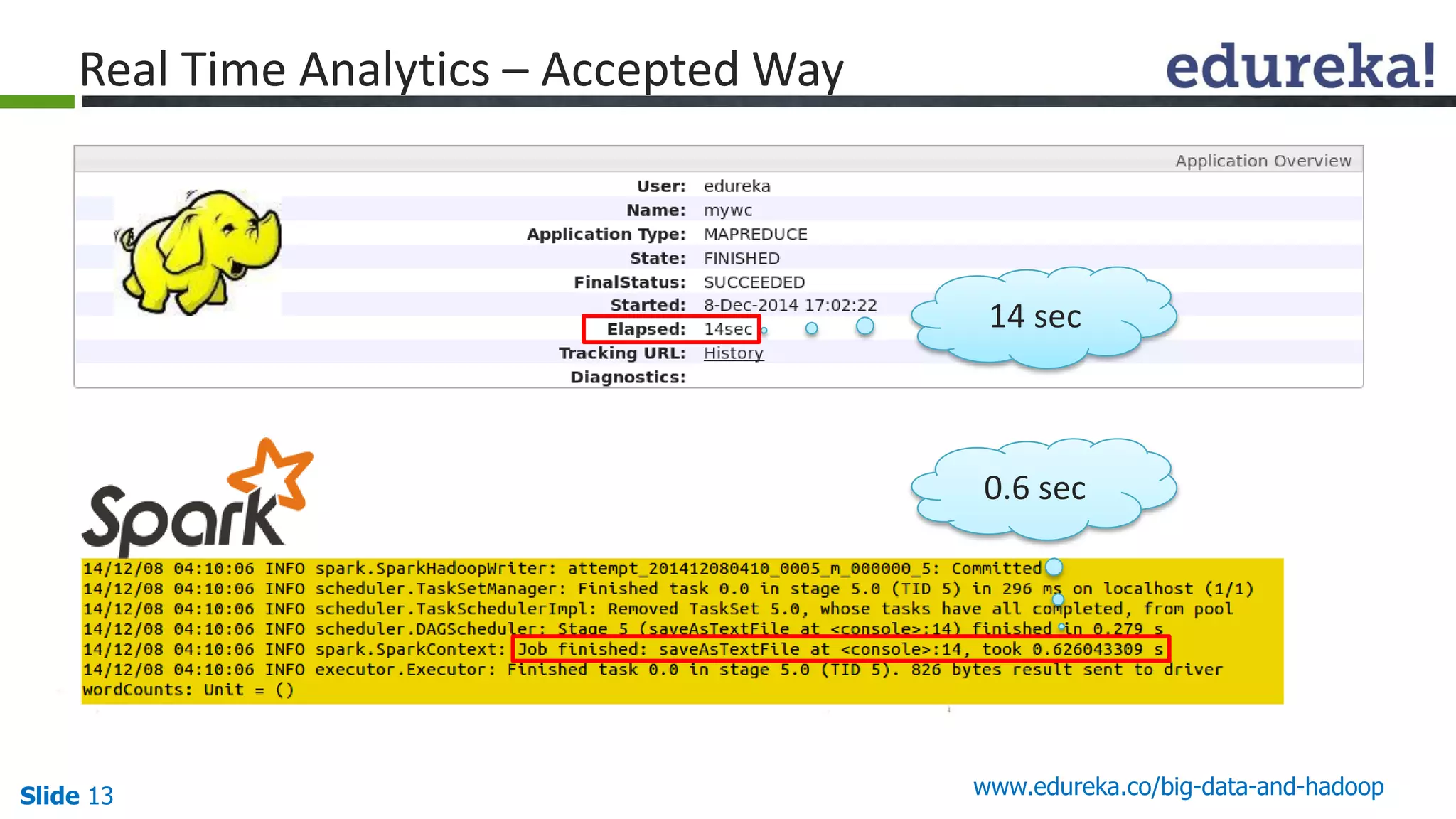
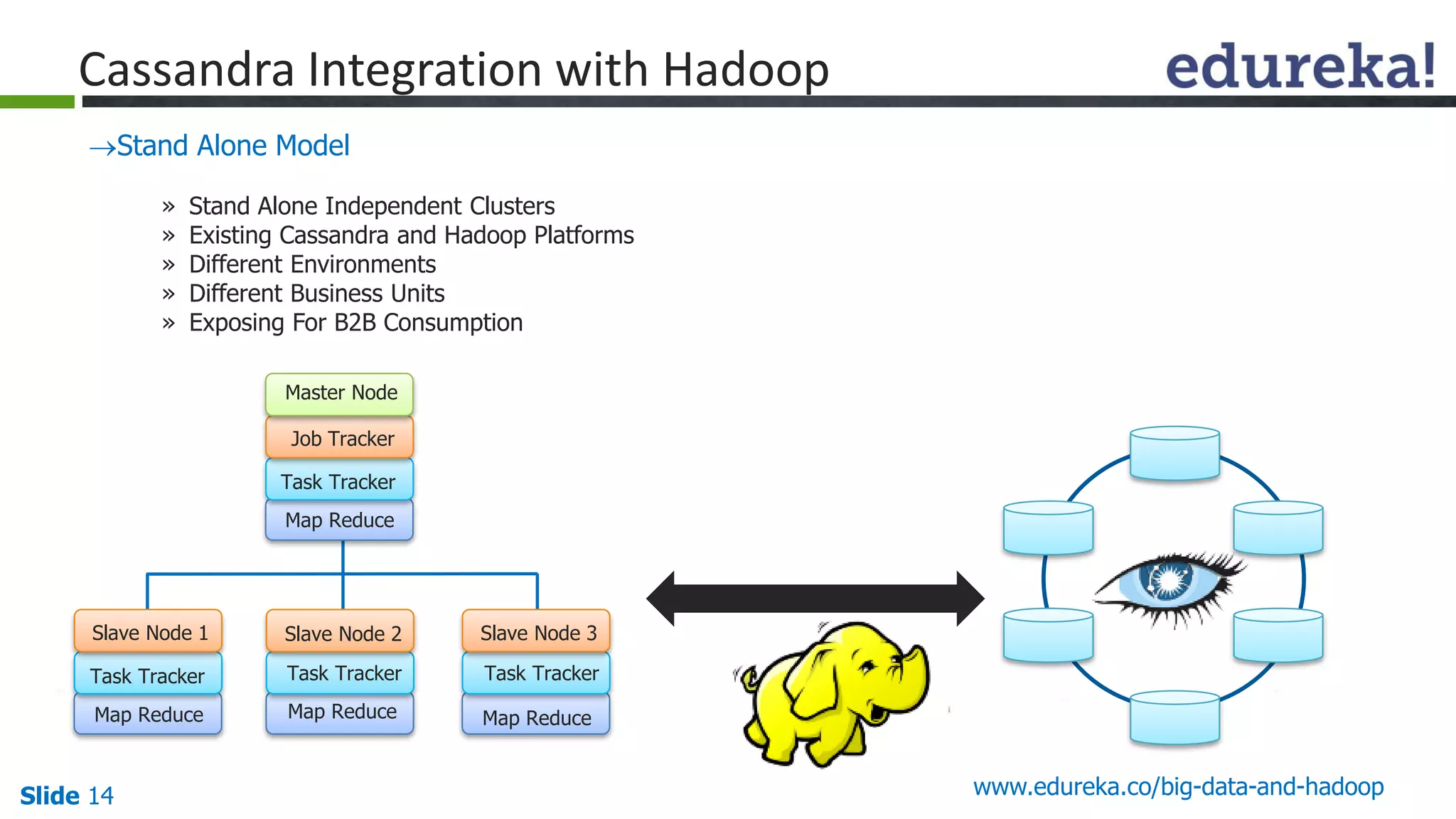
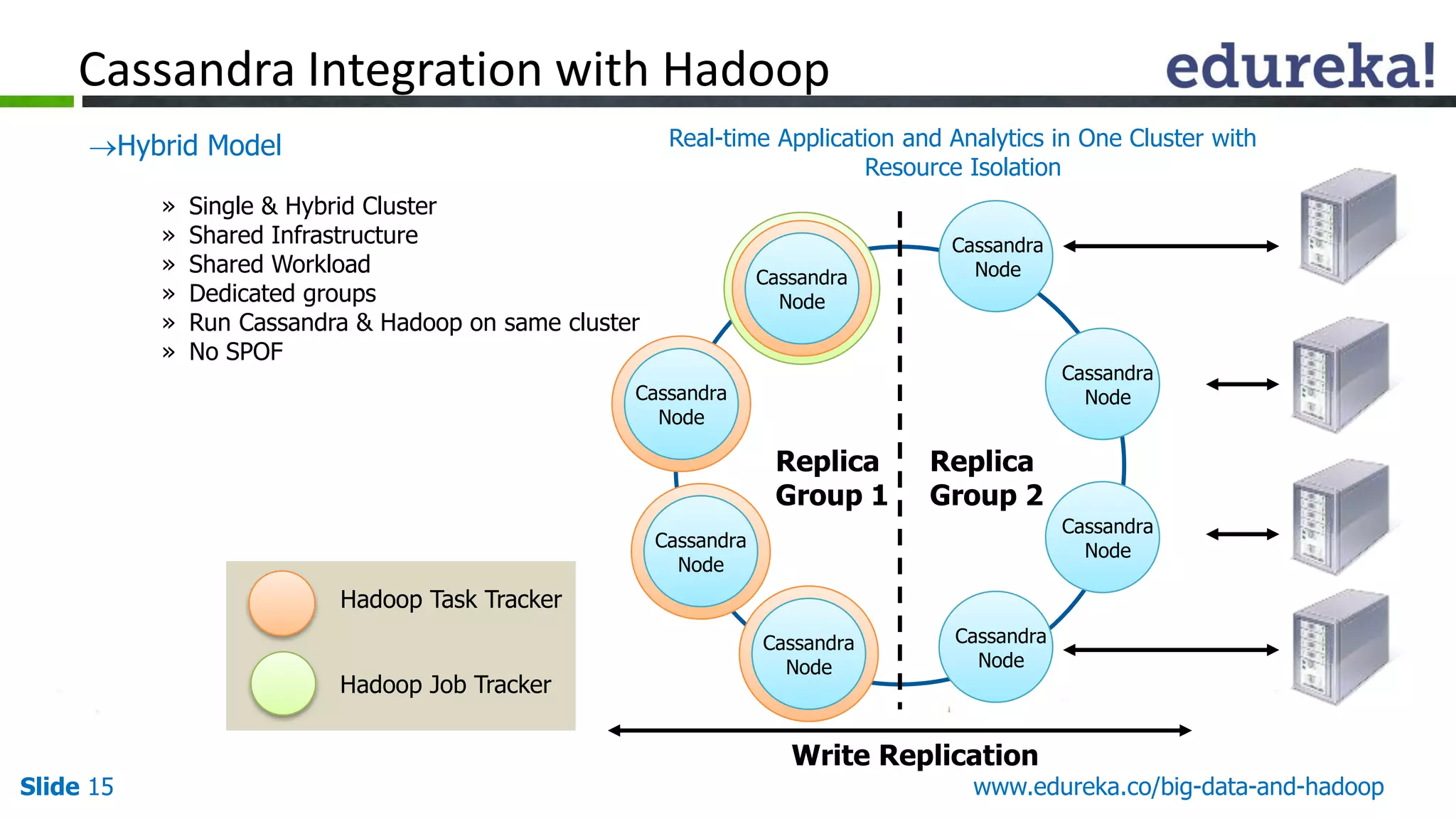


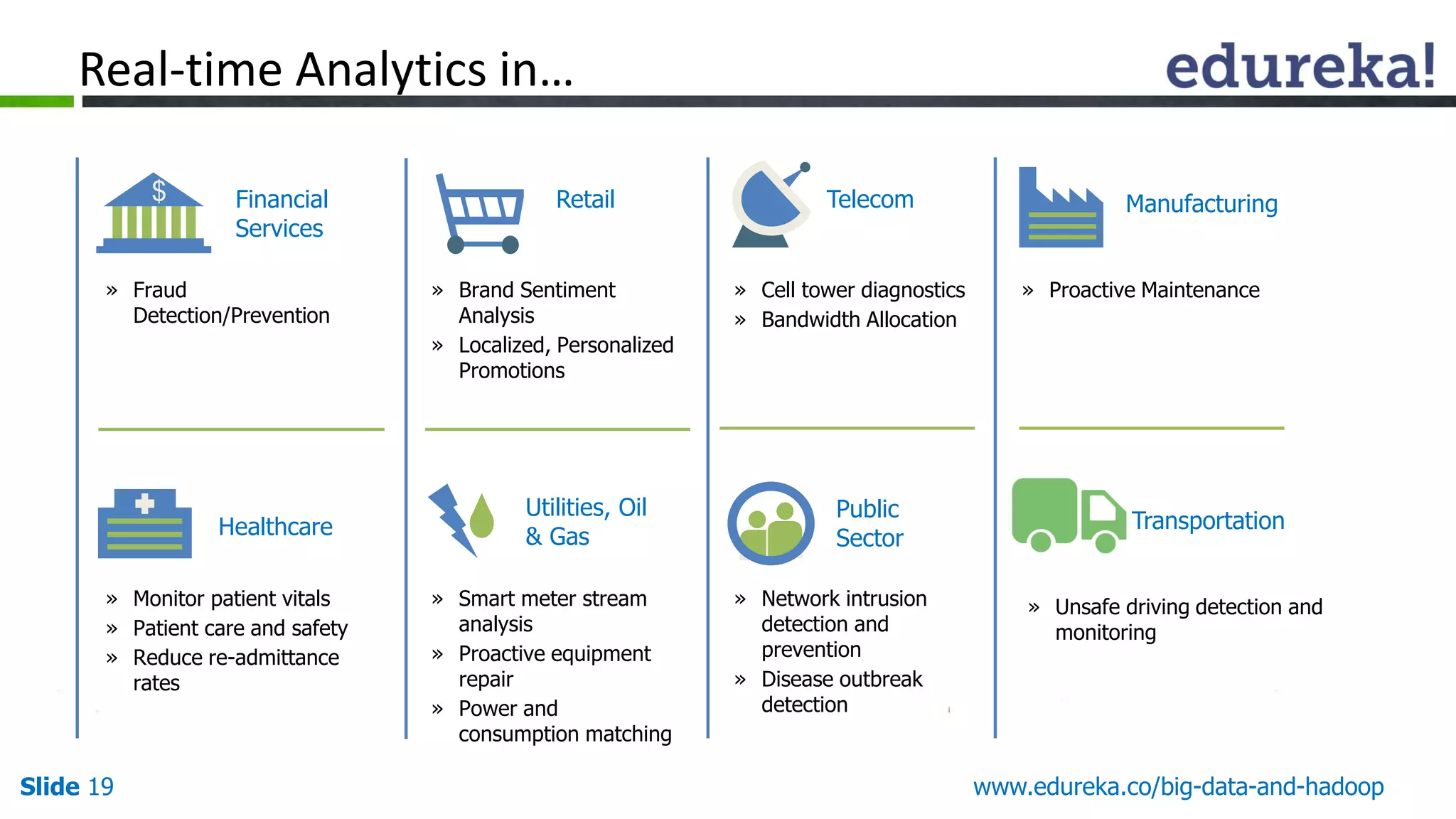
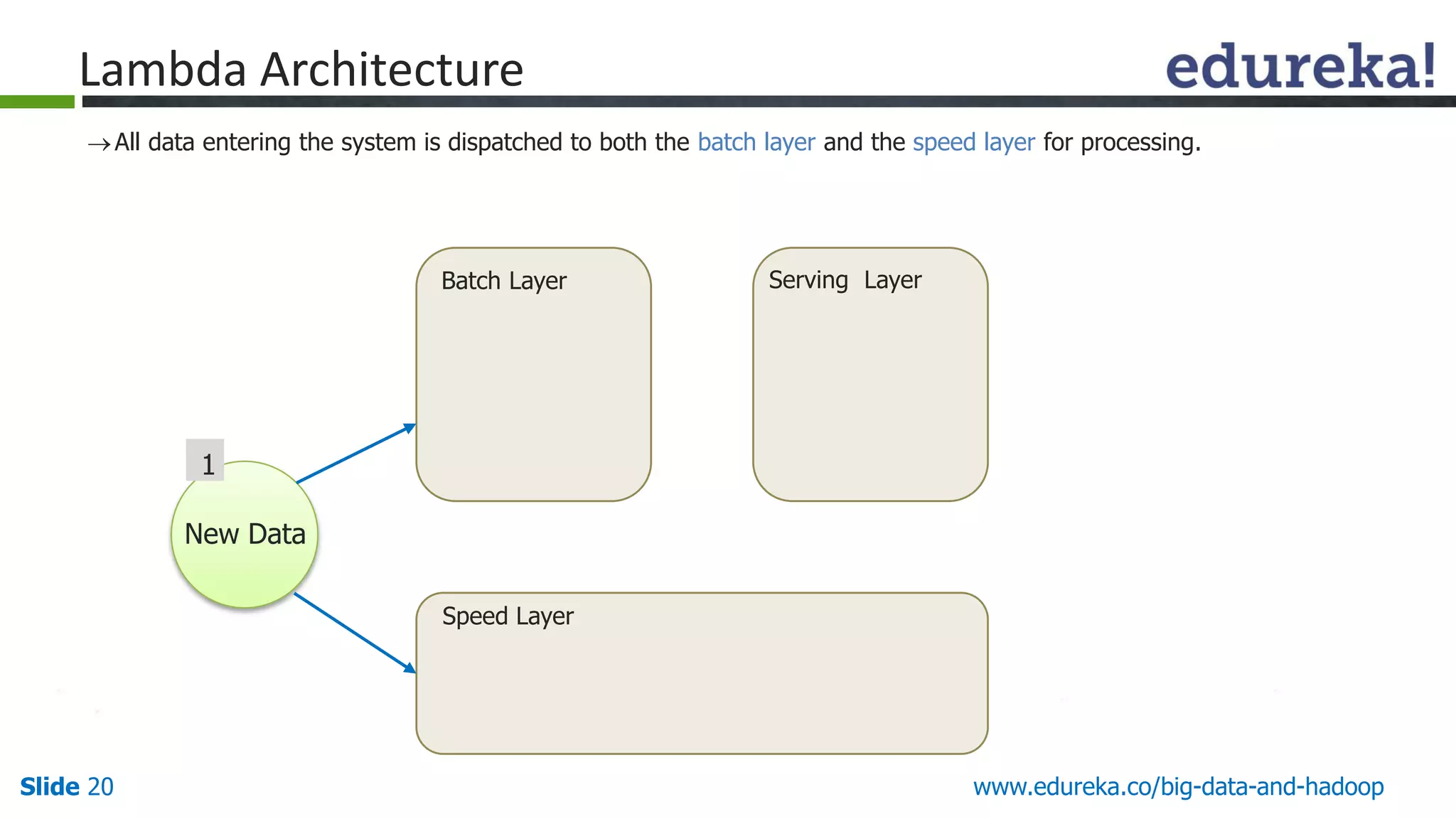
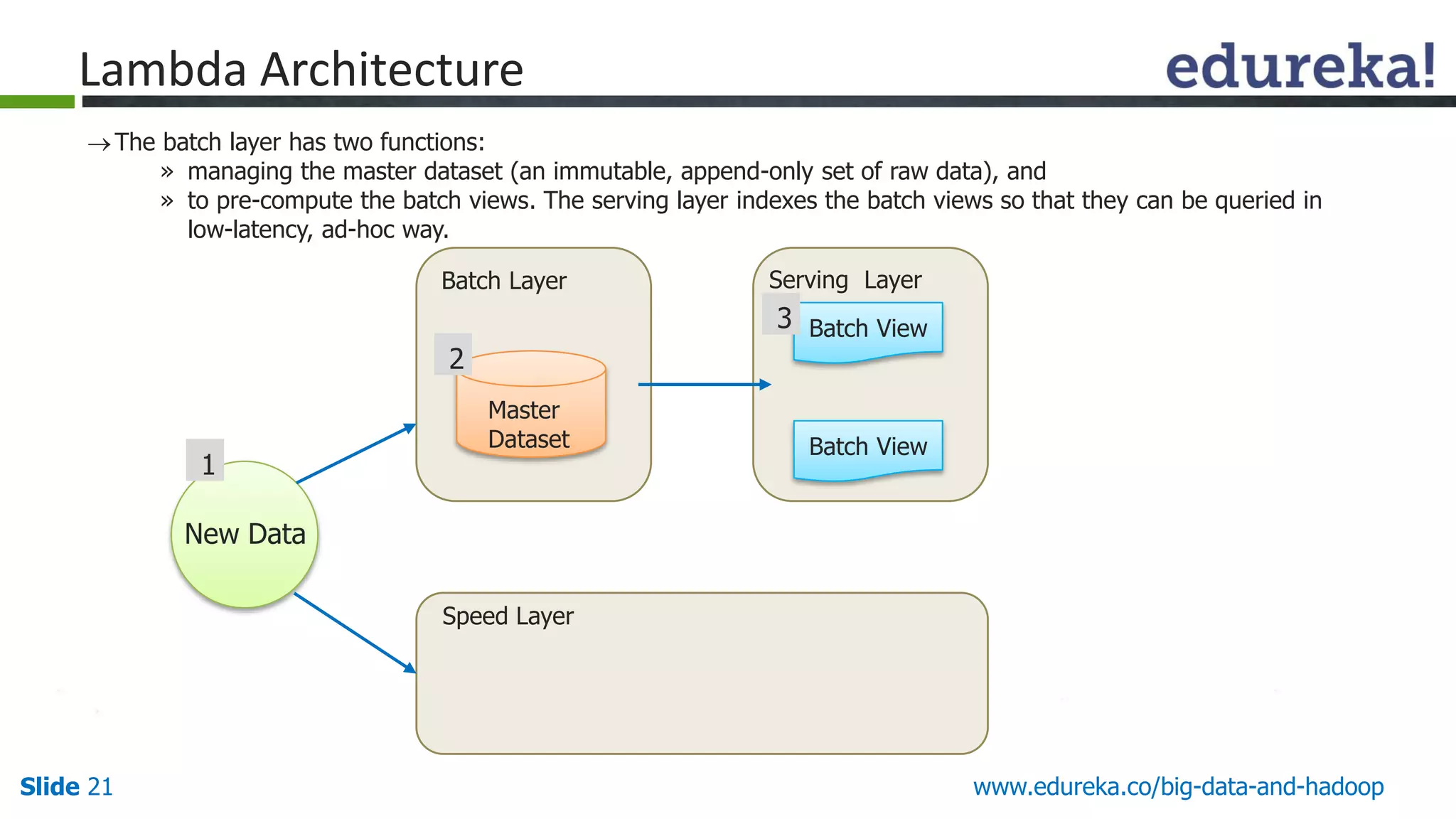

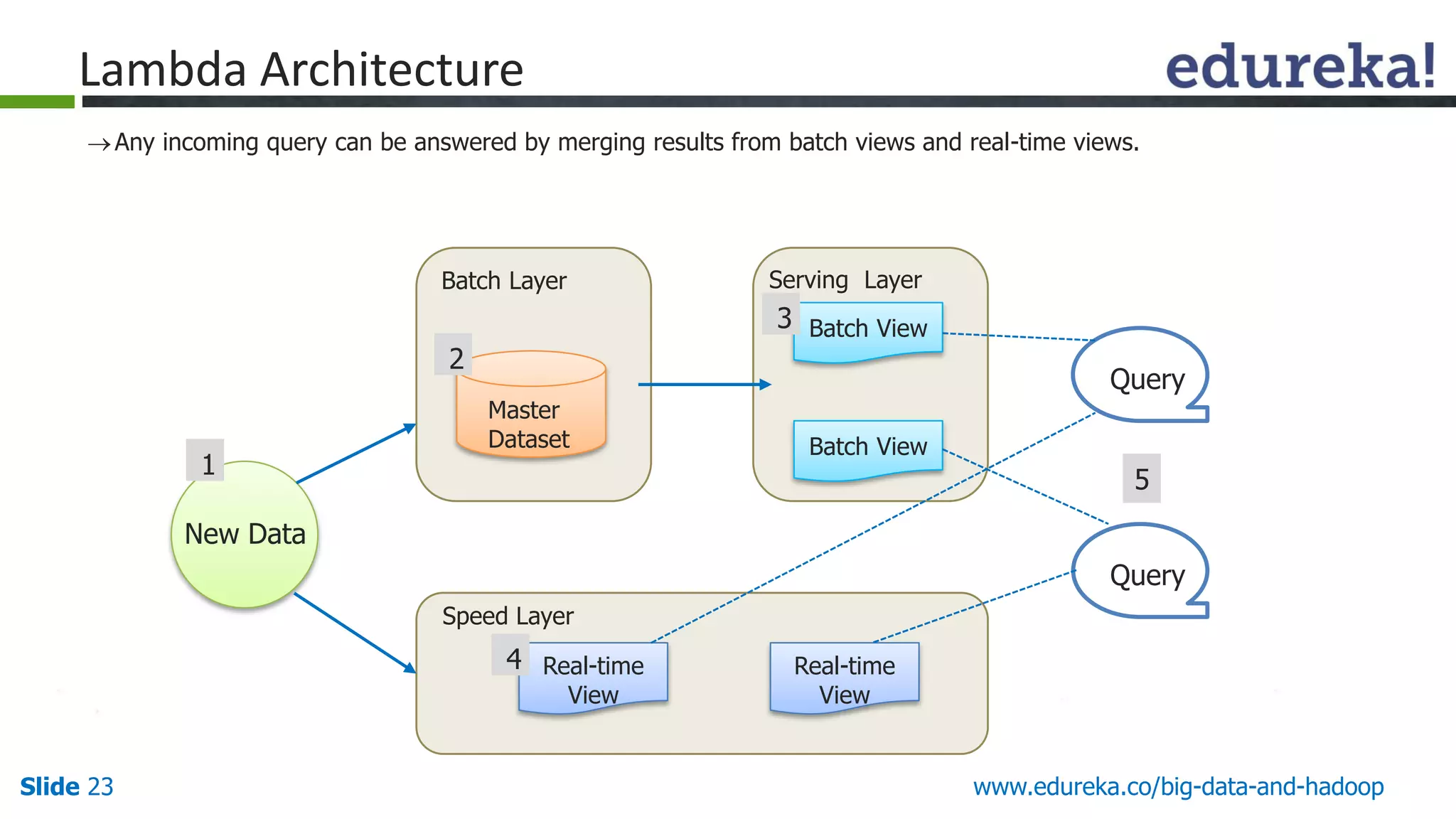







The document details the integration and functionalities of Hadoop with various tools like Spark, Cassandra, and Pentaho, emphasizing its versatility and real-time processing capabilities. It highlights predictions for Hadoop's growth in 2015, including the emergence of new IT jobs and its transition from experimental use to standard enterprise components. Additionally, it outlines the Lambda architecture for data processing and introduces upcoming tools in the big data landscape.





































































































