






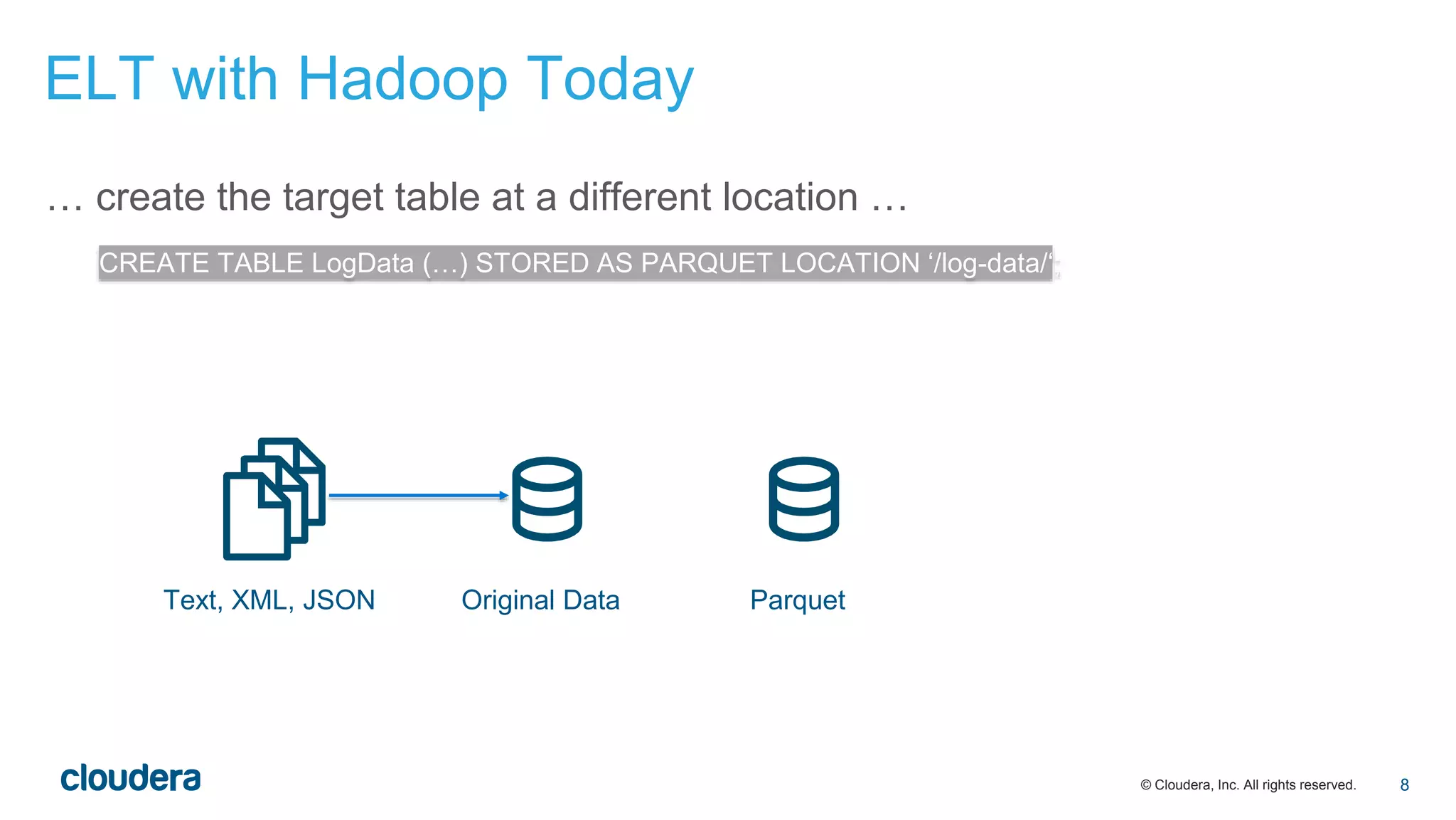
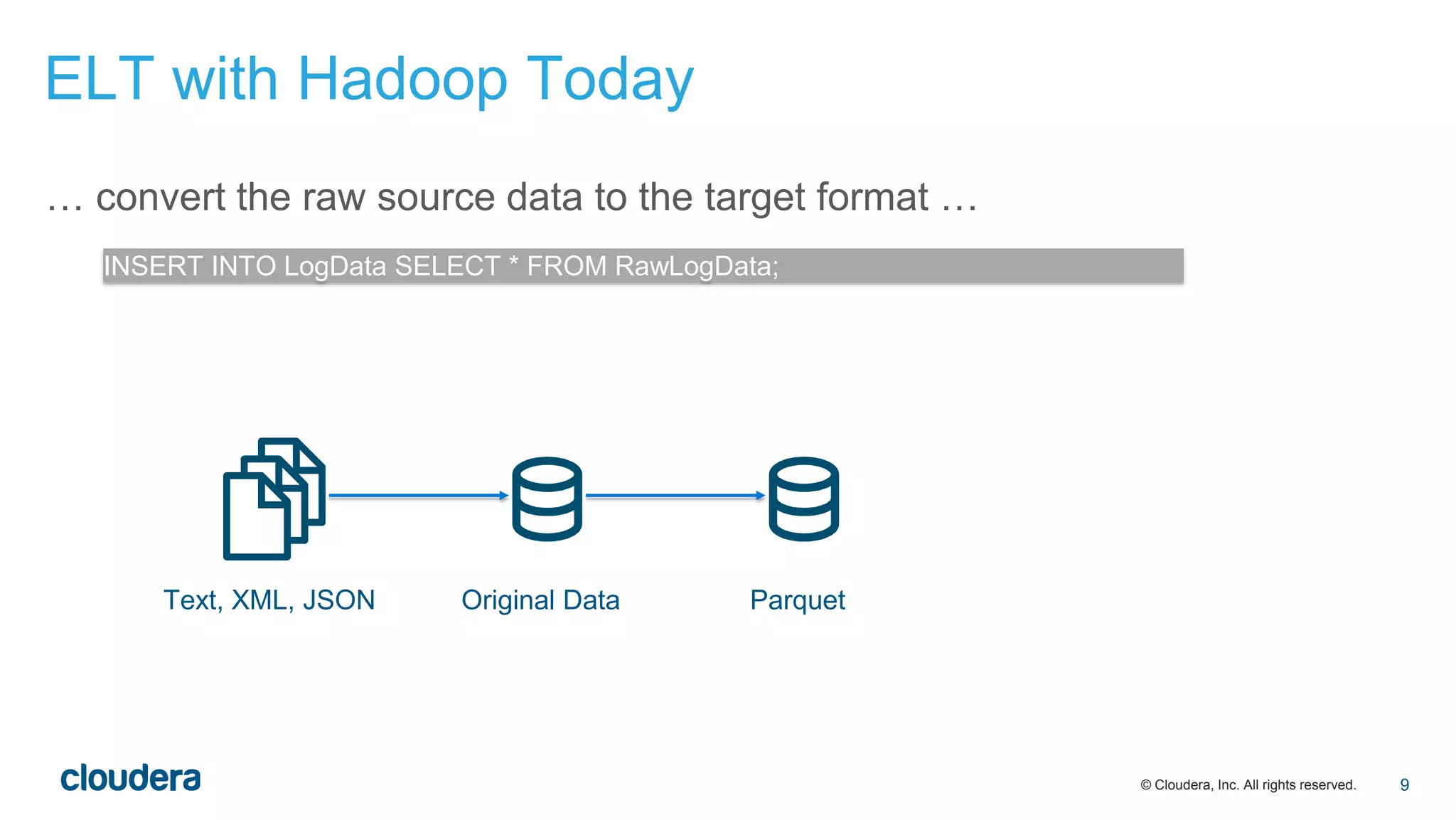
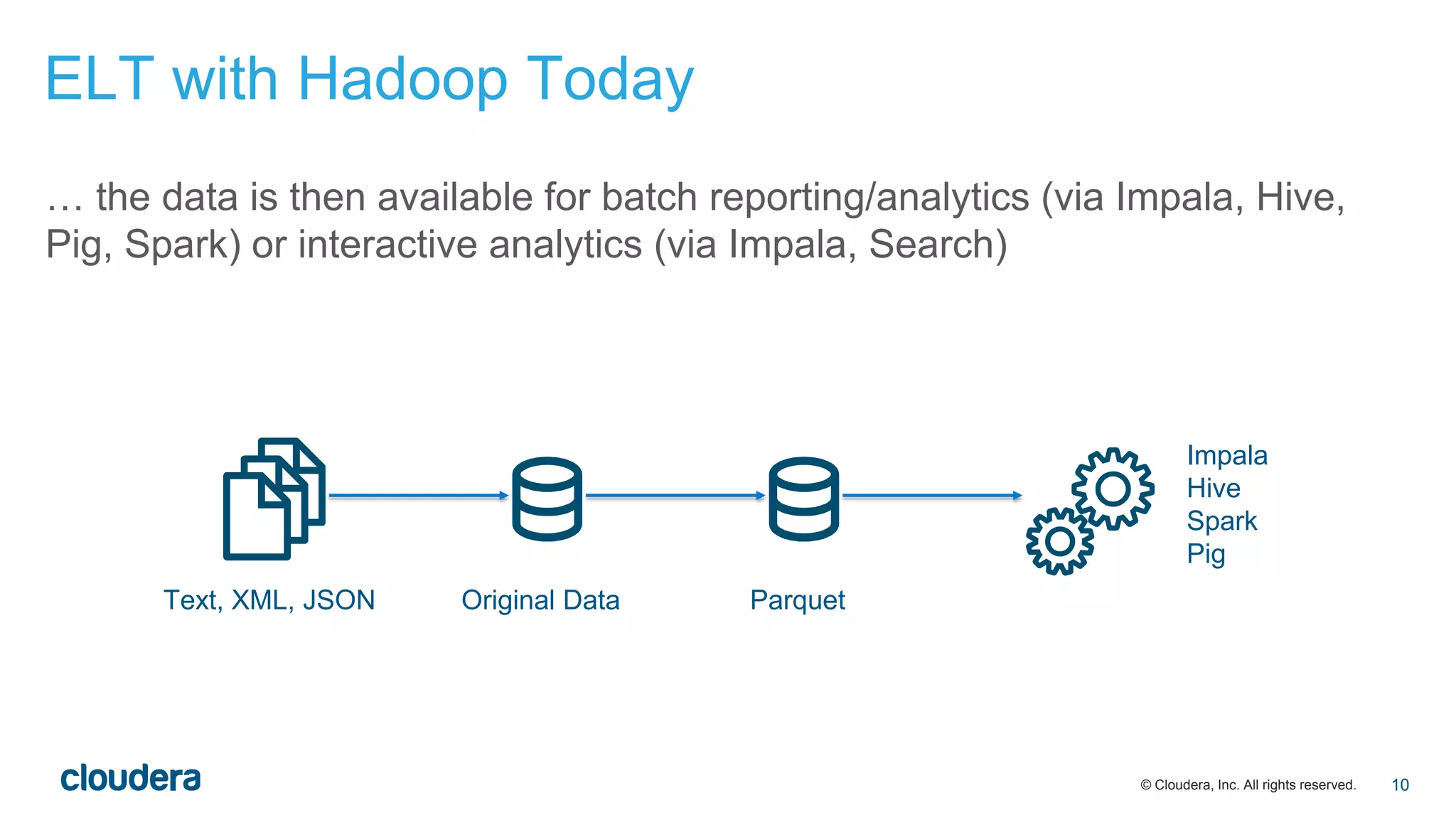

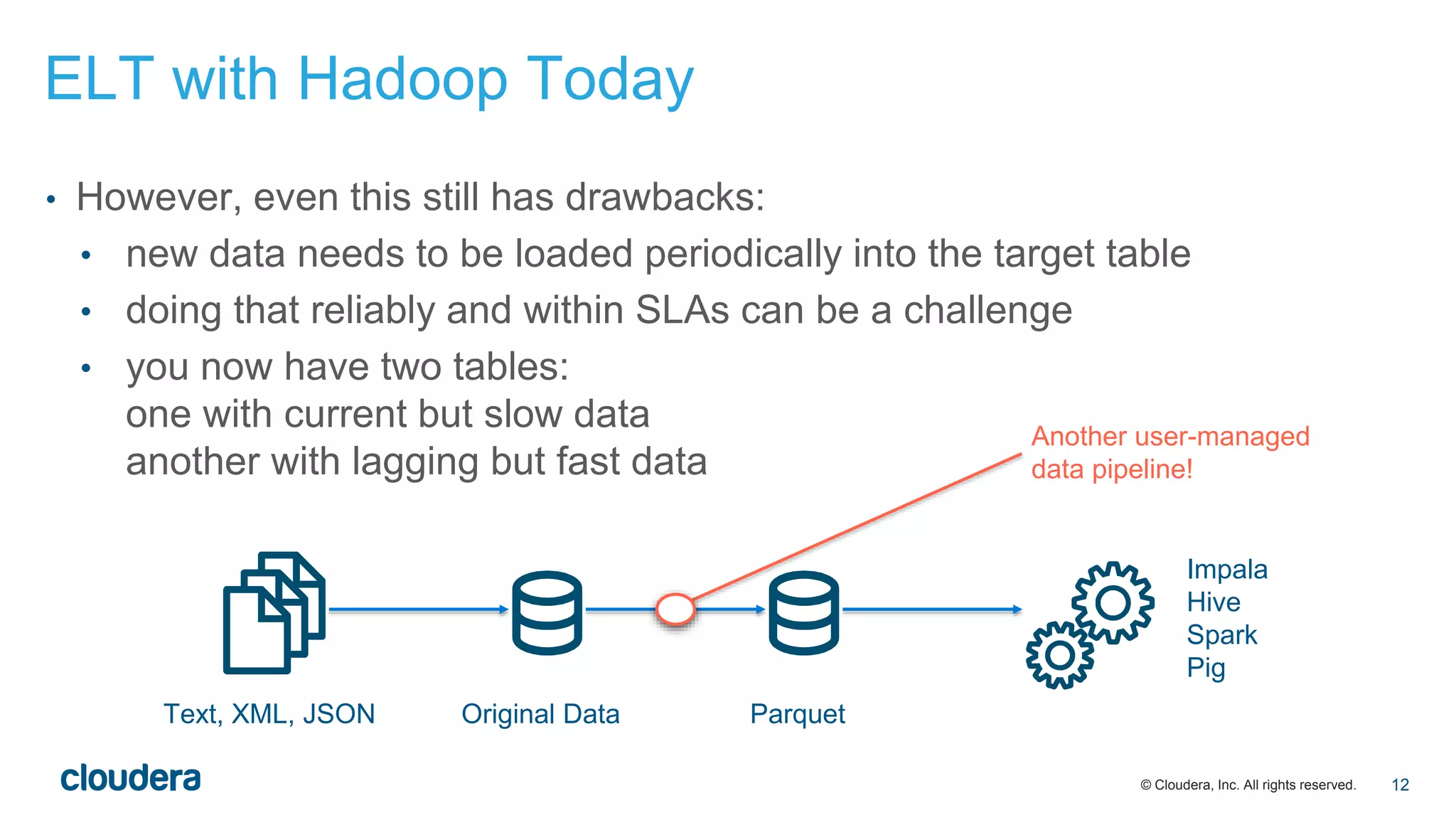
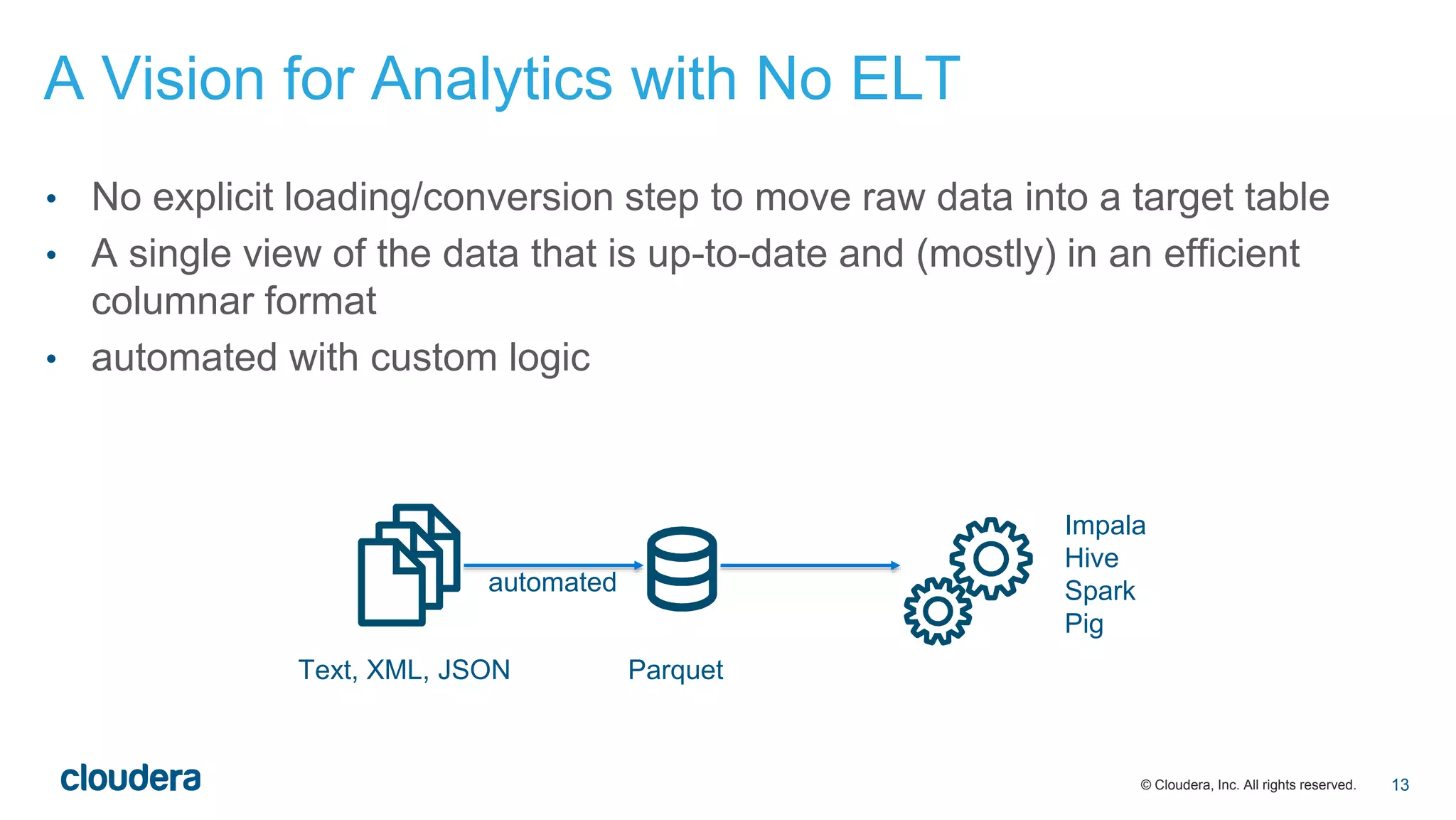











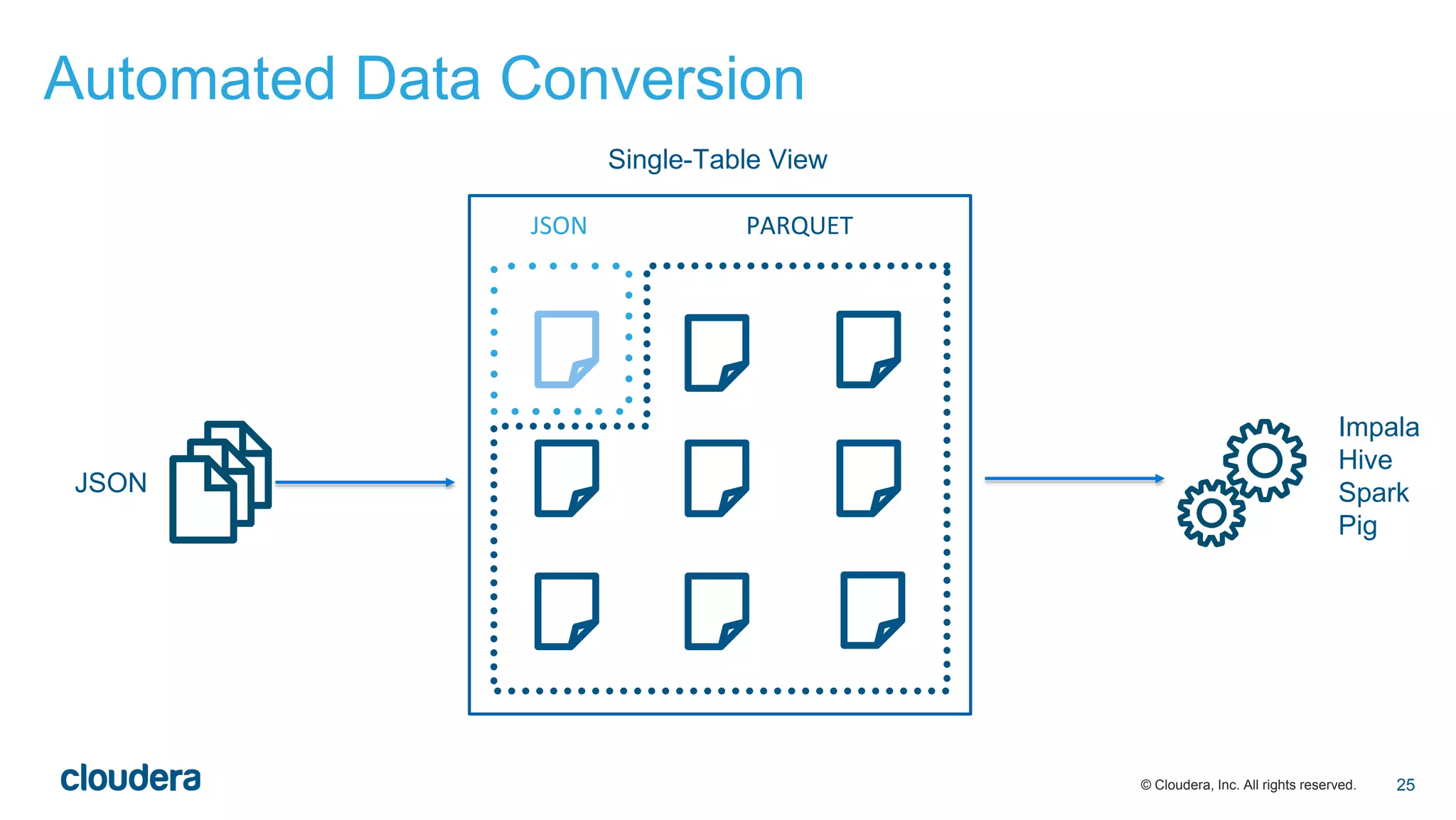



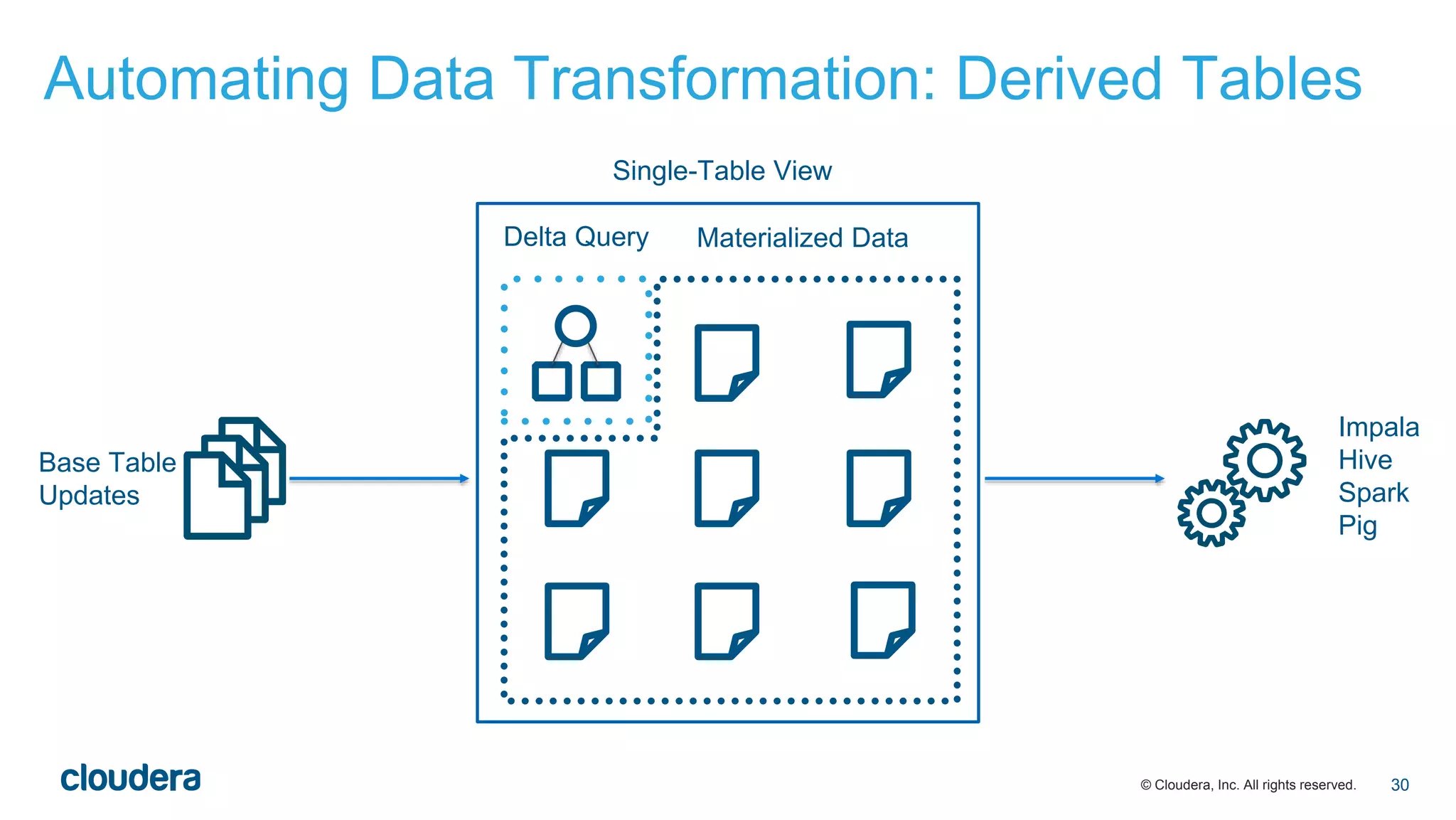







The document discusses the evolution of Extract, Load, Transform (ELT) processes in analytics, highlighting the transition from traditional systems to a more automated solution using Cloudera Impala with Hadoop. It outlines Cloudera's vision of minimizing data transformation overhead by automating data conversion and supporting complex/nested schemas, thereby simplifying the analytics workflow. Ultimately, the aim is to create a friction-free data transformation environment that retains real-time accessibility and reduces operational complexities.























































































