Downloaded 891 times




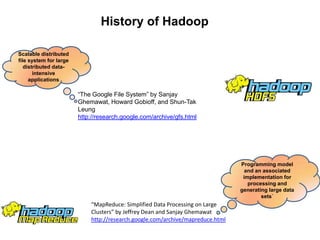

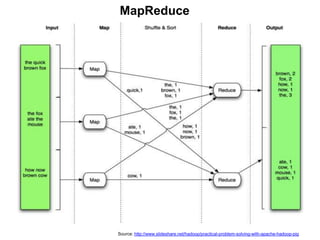


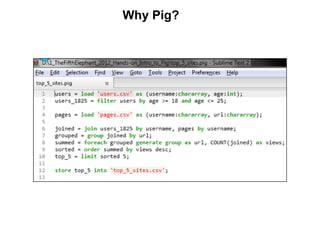

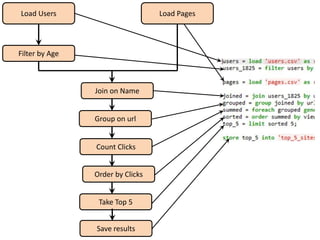
![Pig vs Hadoop
5% of the MR code.
5% of the MR development time.
Within 25% of the MR execution time.
Readable and reusable.
Easy to learn DSL.
Increases programmer productivity.
No Java expertise required.
Anyone [eg. BI folks] can trigger the Jobs.
Insulates against Hadoop complexity
Version upgrades
Changes in Hadoop interfaces
JobConf configuration tuning
Job Chains](https://image.slidesharecdn.com/thefifthelephant2012hands-onintrotopig-130126072429-phpapp01/85/Introduction-to-Pig-19-320.jpg)



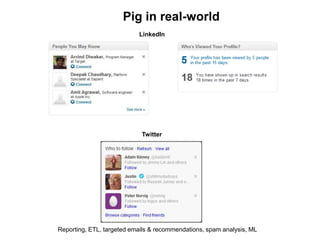



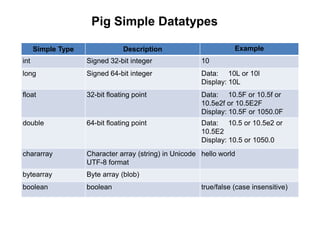
![Pig Complex Datatypes
Type Description Example
tuple An ordered set of fields. (19,2)
bag An collection of tuples. {(19,2), (18,1)}
map A set of key value pairs. [open#apache]](https://image.slidesharecdn.com/thefifthelephant2012hands-onintrotopig-130126072429-phpapp01/85/Introduction-to-Pig-28-320.jpg)
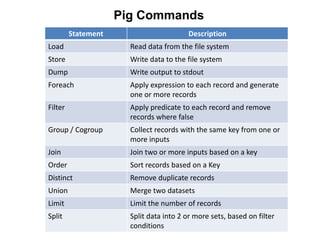

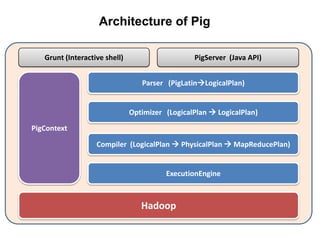
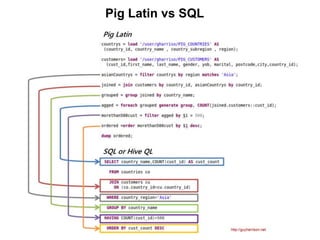


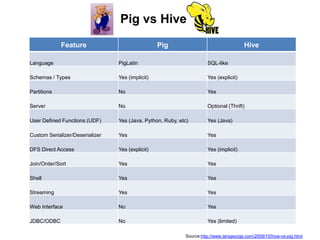









This document provides an introduction to the Pig analytics platform for Hadoop. It begins with an overview of big data and Hadoop, then discusses the basics of Pig including its data model, language called Pig Latin, and components. Key points made are that Pig provides a high-level language for expressing data analysis processes, compiles queries into MapReduce programs for execution, and allows for easier programming than lower-level systems like Java MapReduce. The document also compares Pig to SQL and Hive, and demonstrates visualizing Pig jobs with the Twitter Ambrose tool.





























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)













