


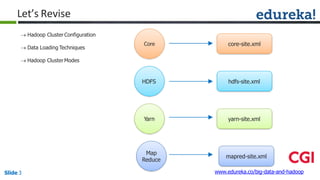
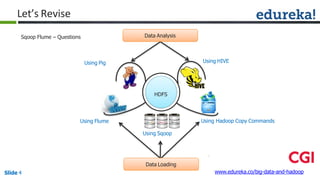


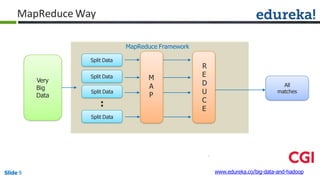



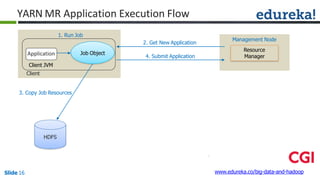
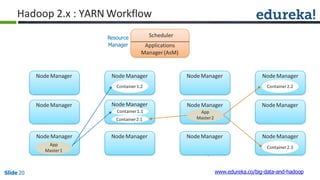





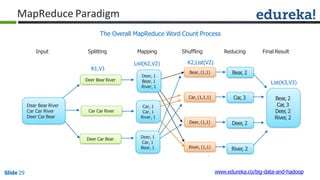




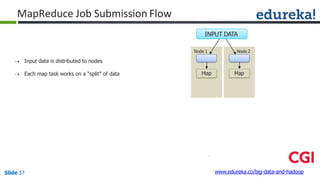
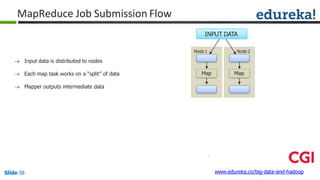
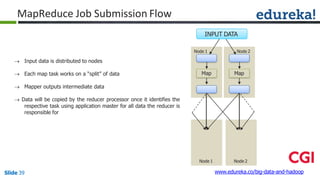
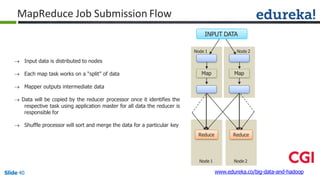
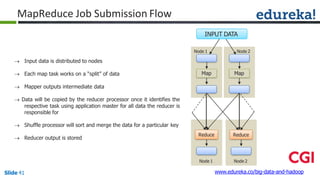



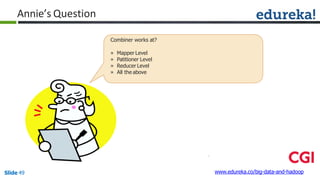
![Combiner
Combiner
Reducer
(B,1)
(C,1)
(D,1)
(E,1)
(D,1)
(B,1)
(D,1)
(A,1)
(A,1)
(C,1)
(B,1)
(D,1)
(B,2)
(C,1)
(D,2)
(E,1)
(D,2)
(A,2)
(C,1)
(B,1)
(A, [2])
(B, [2,1])
(C, [1,1])
(D, [2,2])
(E, [1])
(A,2)
(B,3)
(C,2)
(D,4)
(E,1)
Shuffle
CombinerMapper
Mapper
B
C
D
E
D
B
D
A
A
C
B
D
Block1Block2
www.edureka.co/big-data-and-hadoopSlide 48](https://image.slidesharecdn.com/module3-bigdataandhadoop-160425063358/85/Hadoop-MapReduce-Framework-48-320.jpg)







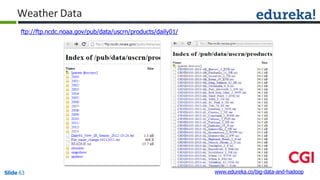
![public static String encrypt(String strToEncrypt, byte[] key)
{
try
{
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
SecretKeySpec secretKey = new SecretKeySpec(key, "AES");
cipher.init(Cipher.ENCRYPT_MODE, secretKey);
String encryptedString = Base64.encodeBase64String(cipher.doFinal(strToEncrypt.getBytes()));
return encryptedString.trim();
}
catch (Exception e)
{
logger.error("Error while encrypting", e);
}
return null;
}
}
www.edureka.co/big-data-and-hadoopSlide 61
DeIdentify MapReduce Code](https://image.slidesharecdn.com/module3-bigdataandhadoop-160425063358/85/Hadoop-MapReduce-Framework-61-320.jpg)








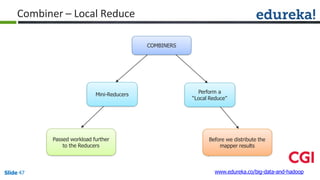
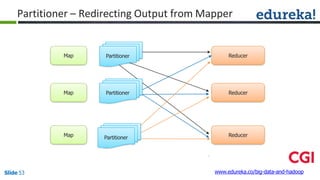
No, combiner and reducer logic cannot be same. Combiner is an optional step that performs local aggregation of the intermediate key-value pairs generated by the mappers. Its goal is to reduce the amount of data transferred from the mapper to the reducer. Reducer performs the final aggregation of the values associated with a particular key. It receives the intermediate outputs from all the mappers, groups them by key, and produces the final output. So while combiner and reducer both perform aggregation, their scopes of operation are different - combiner works locally on mapper output to minimize data transfer, whereas reducer operates globally on all mapper outputs to produce the final output. The logic needs to be optimized for their respective purposes.























































































