Downloaded 71 times





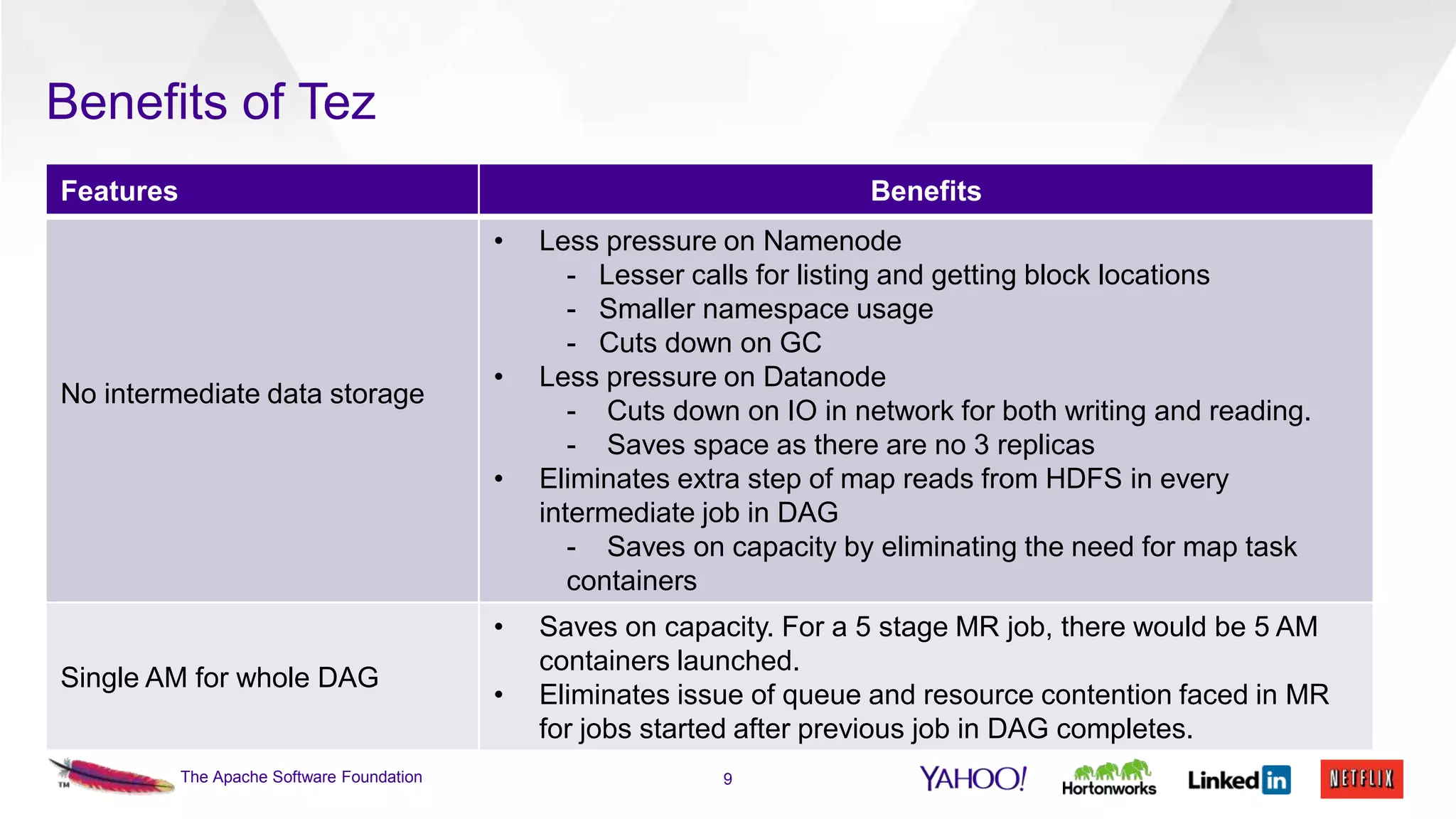
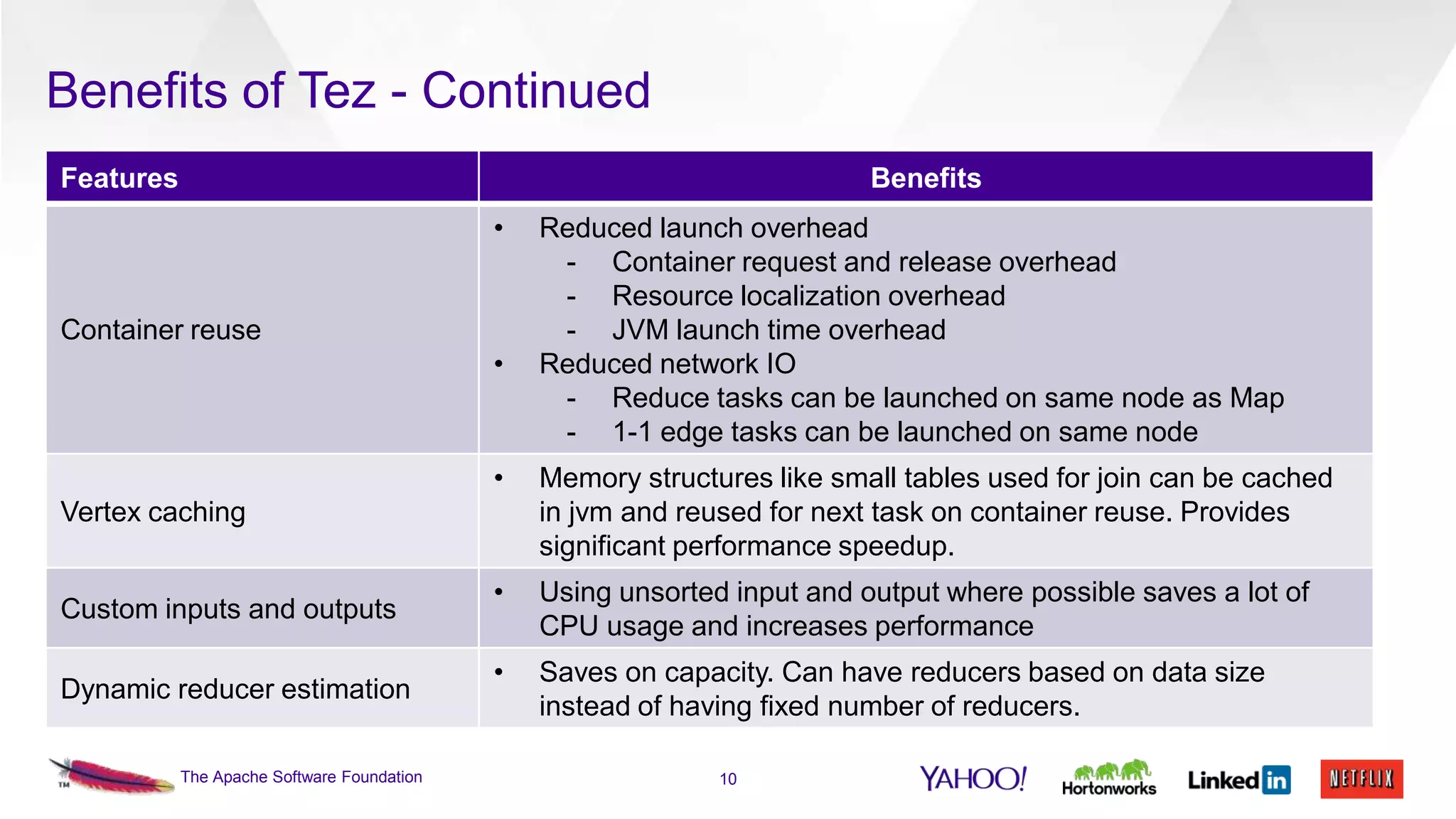
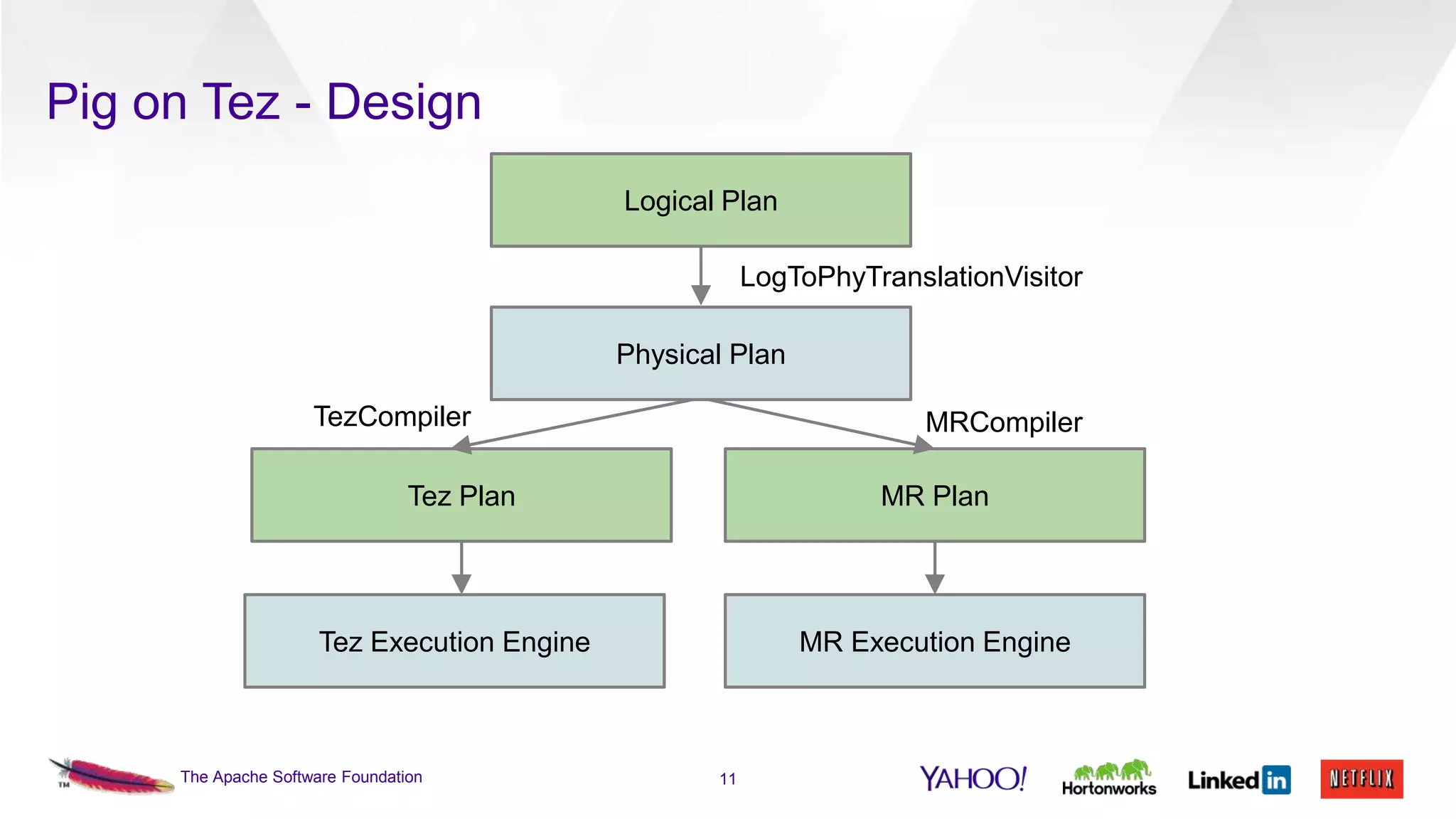
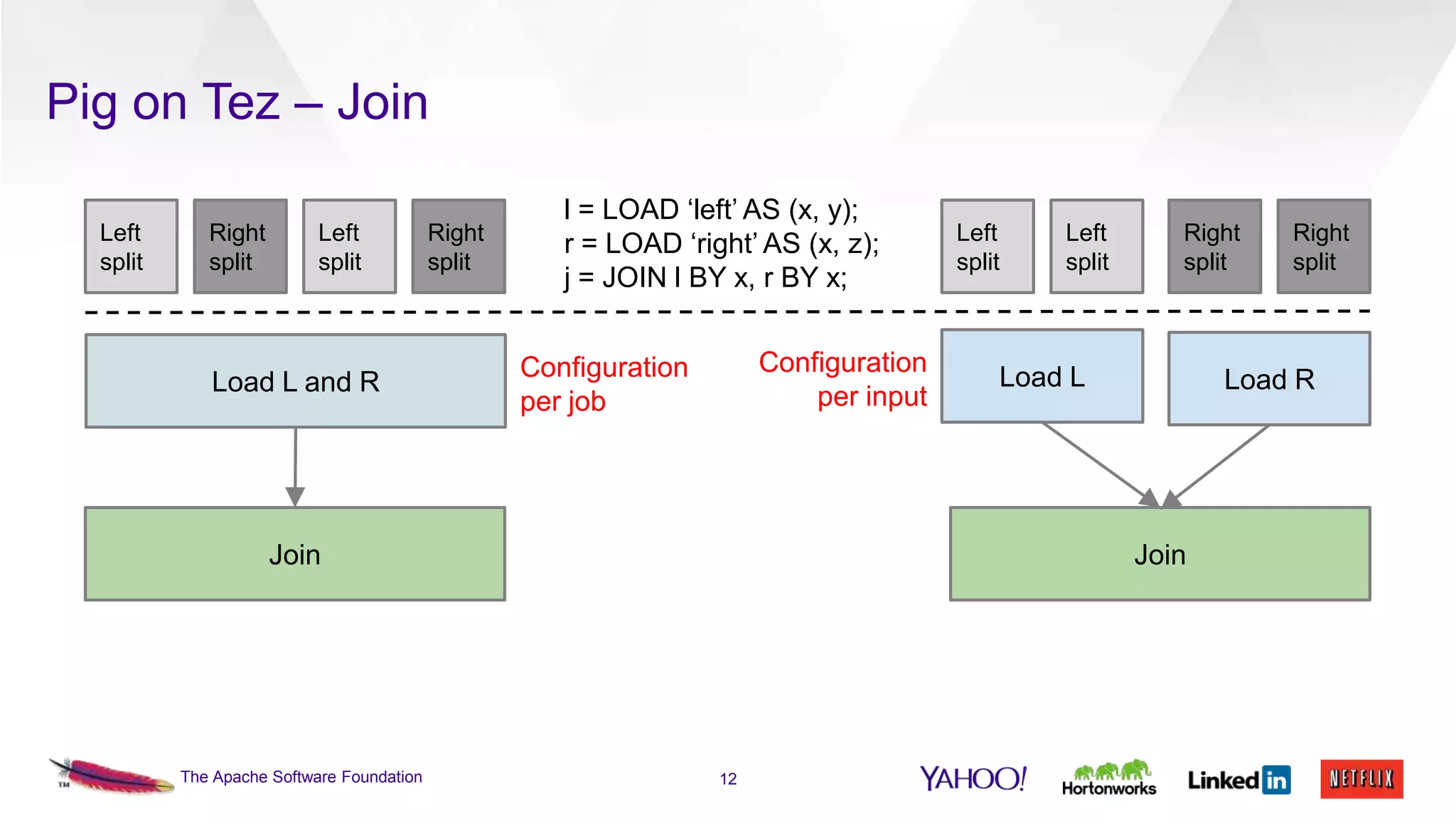
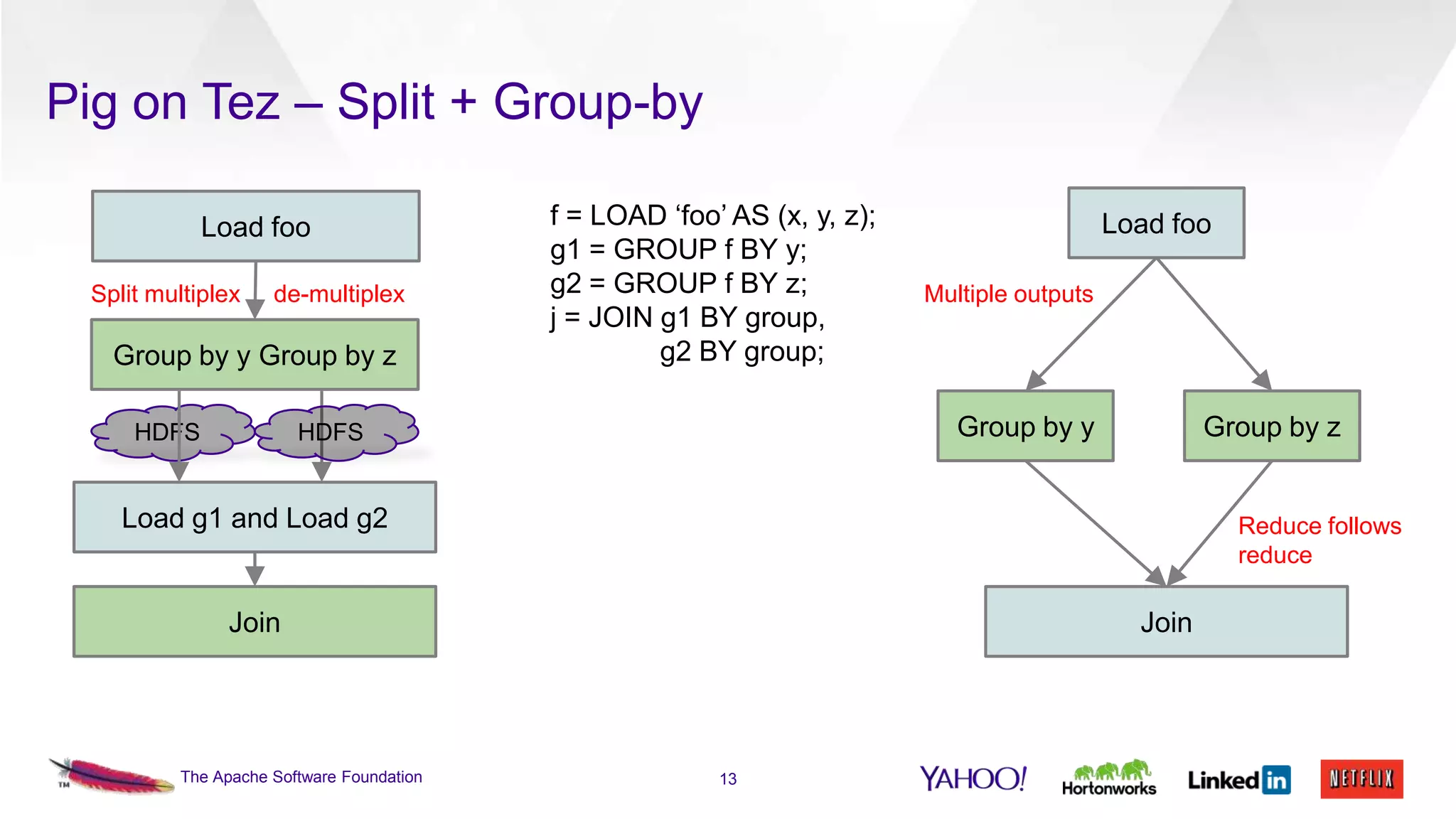
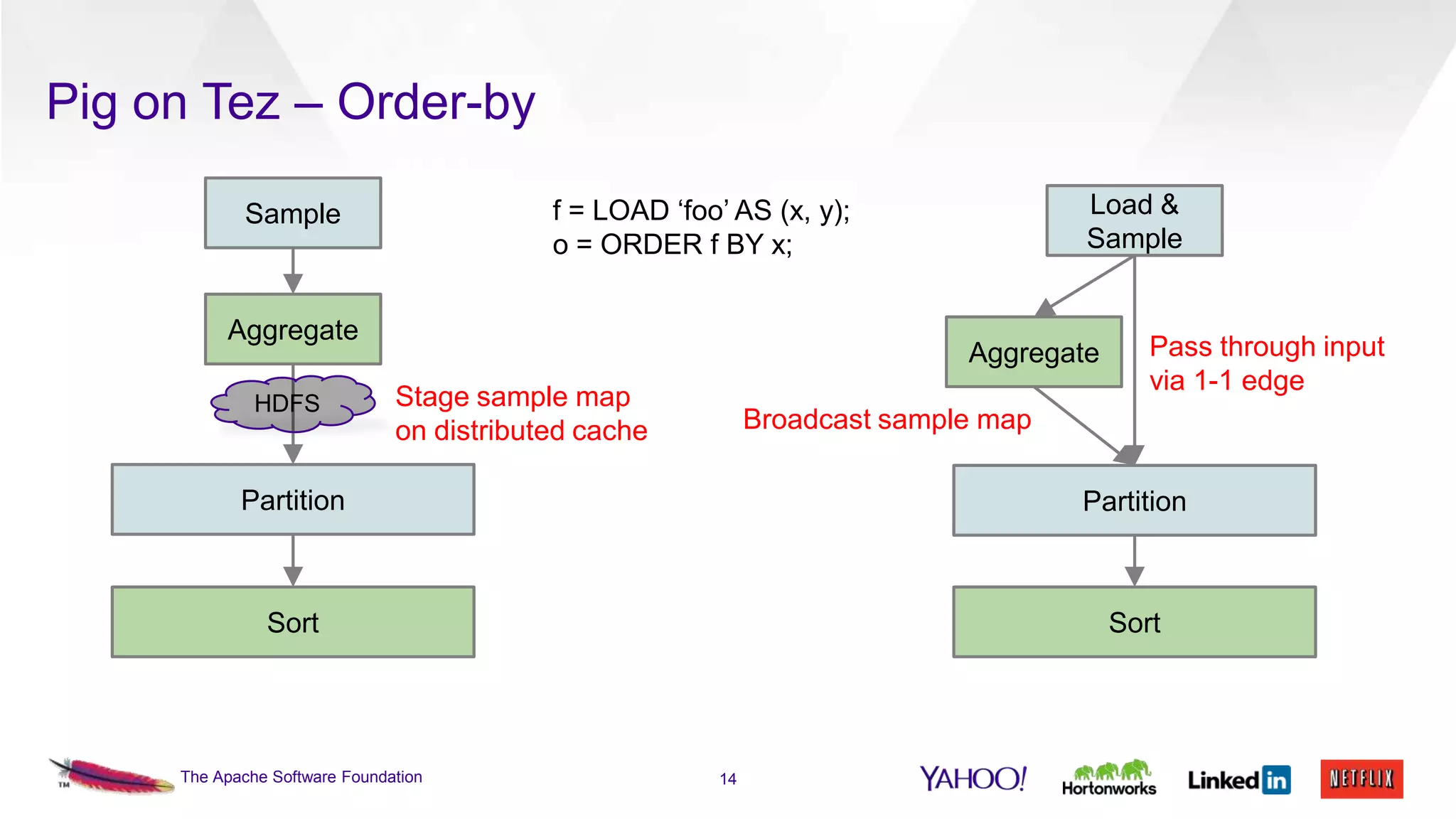
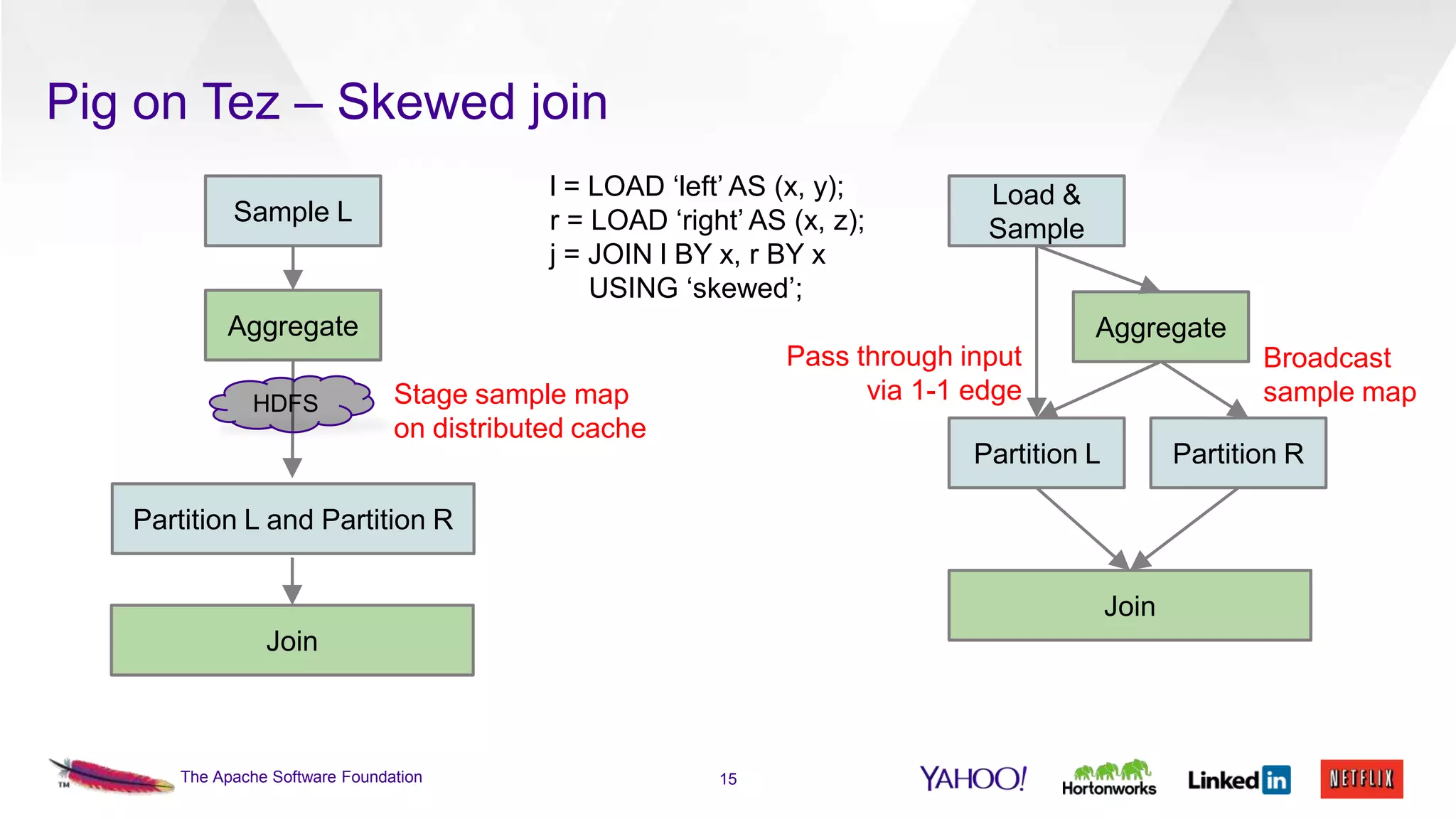
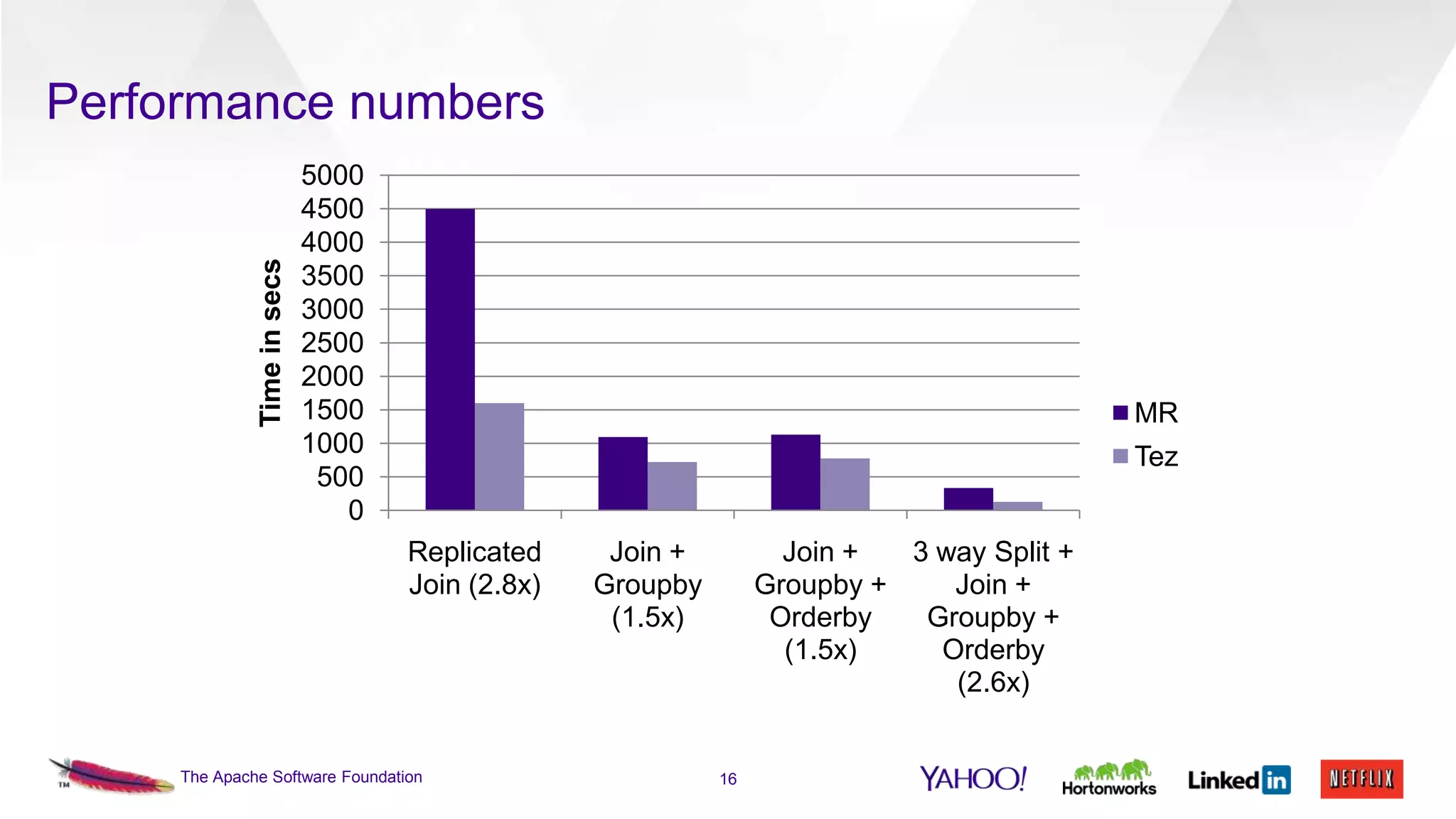

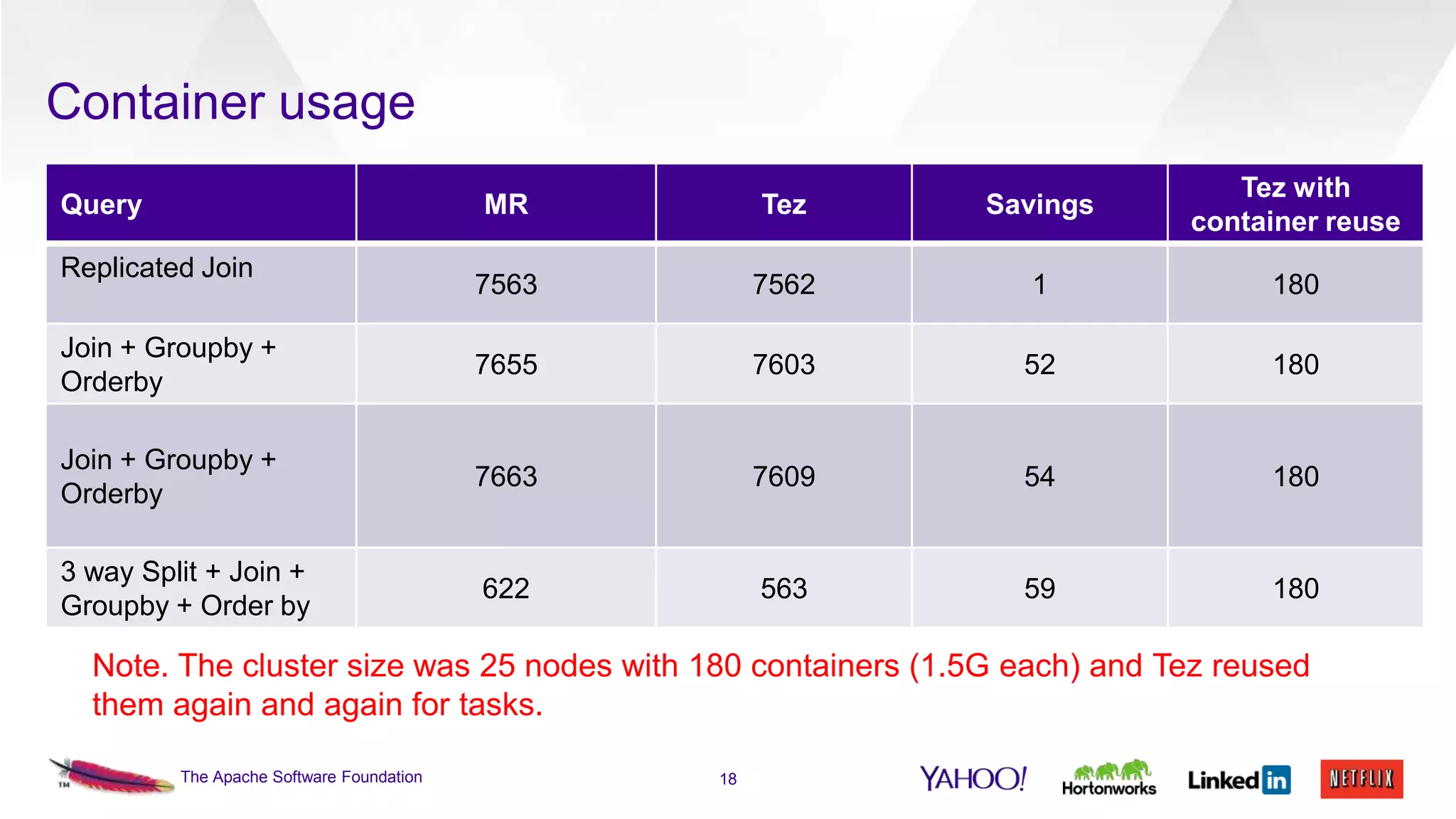








This document discusses the integration of Apache Pig with Apache Tez. Pig provides a procedural scripting language for data processing workflows, while Tez is a framework for executing directed acyclic graphs (DAGs) of tasks. Migrating Pig to use Tez as its execution engine provides benefits like reduced resource usage, improved performance, and container reuse compared to Pig's default MapReduce execution. The document outlines the design changes needed to compile Pig scripts to Tez DAGs and provides examples and performance results. It also discusses ongoing work to achieve full feature parity with MapReduce and further optimize performance.

















































![[2C1] 아파치 피그를 위한 테즈 연산 엔진 개발하기 최종](https://cdn.slidesharecdn.com/ss_thumbnails/2b1-140929191628-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













































