Downloaded 104 times





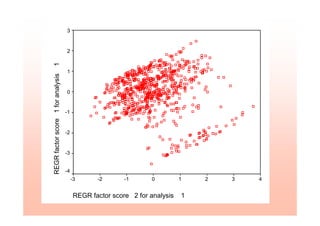




























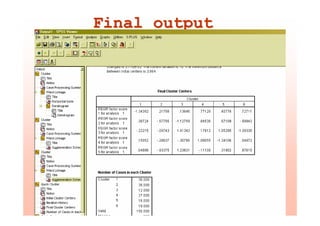


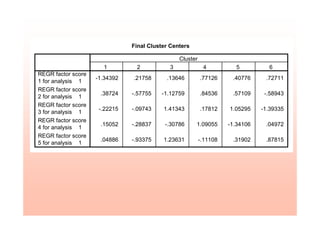




This document provides an overview of cluster analysis techniques. It defines cluster analysis as classifying cases into homogeneous groups based on a set of variables. The document then discusses how cluster analysis can be used in marketing research for market segmentation, understanding consumer behaviors, and identifying new product opportunities. It outlines the typical steps to conduct a cluster analysis, including selecting a distance measure and clustering algorithm, determining the number of clusters, and validating the analysis. Specific clustering methods like hierarchical, k-means, and deciding the number of clusters using the elbow rule are explained. The document concludes with an example of conducting a cluster analysis in SPSS.




































































































