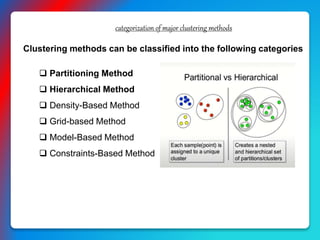
The document presents an overview of clustering methods, highlighting unsupervised learning techniques that group similar data points. It discusses various clustering algorithms, including partitioning methods like k-means and hierarchical methods such as the CURE algorithm, emphasizing their applications in fields like biology and fraud detection. The document also points out the limitations of traditional clustering methods and presents strategies for handling outliers.