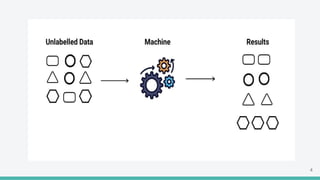
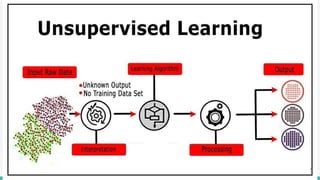
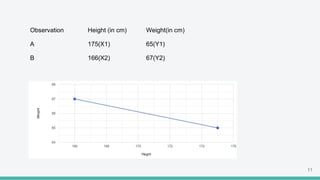
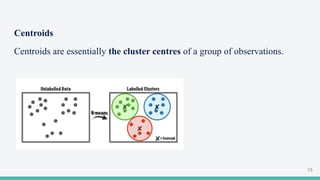
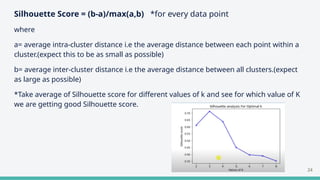
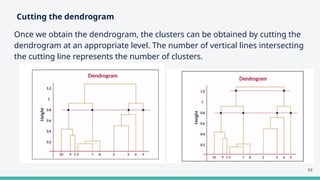
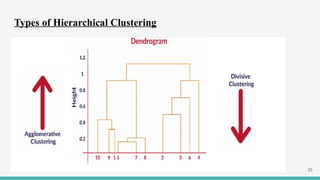
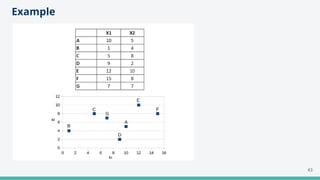
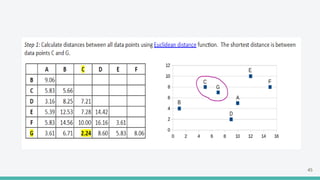
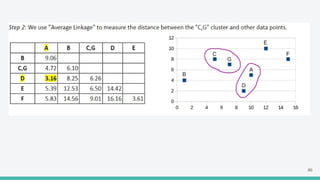
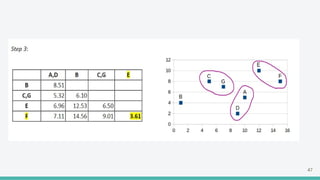
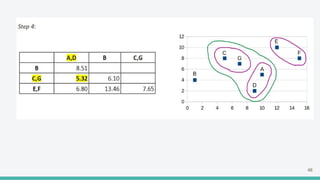
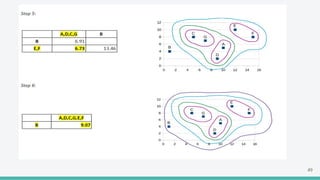
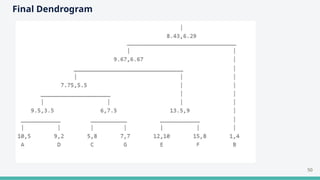
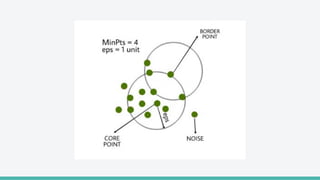
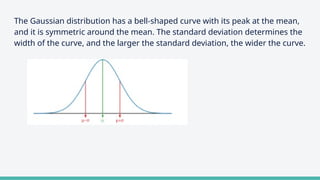
The document provides an overview of clustering in machine learning, focusing on unsupervised learning techniques that analyze unlabeled data to discover patterns, particularly through clustering algorithms like k-means and hierarchical clustering. It covers the applications of clustering in various fields such as retail, marketing, and medicine, while also discussing methods to determine the optimal number of clusters and practical considerations during implementation. Additionally, it addresses alternative clustering methods like k-medoids and DBSCAN, highlighting their strengths and characteristics.