Downloaded 325 times














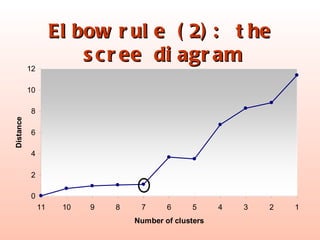




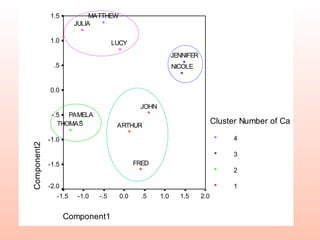








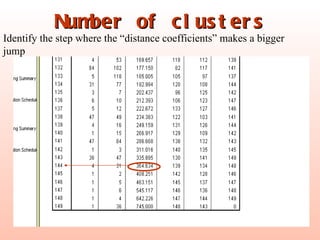



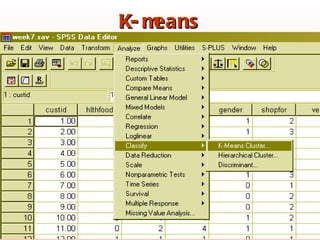










The document discusses cluster analysis, an unsupervised machine learning technique used to group similar cases together. It describes how cluster analysis is used in marketing research for market segmentation, understanding customer behaviors, and identifying new product opportunities. The key steps in cluster analysis involve selecting a distance measure, clustering algorithm, determining the optimal number of clusters, and validating the results.



































































