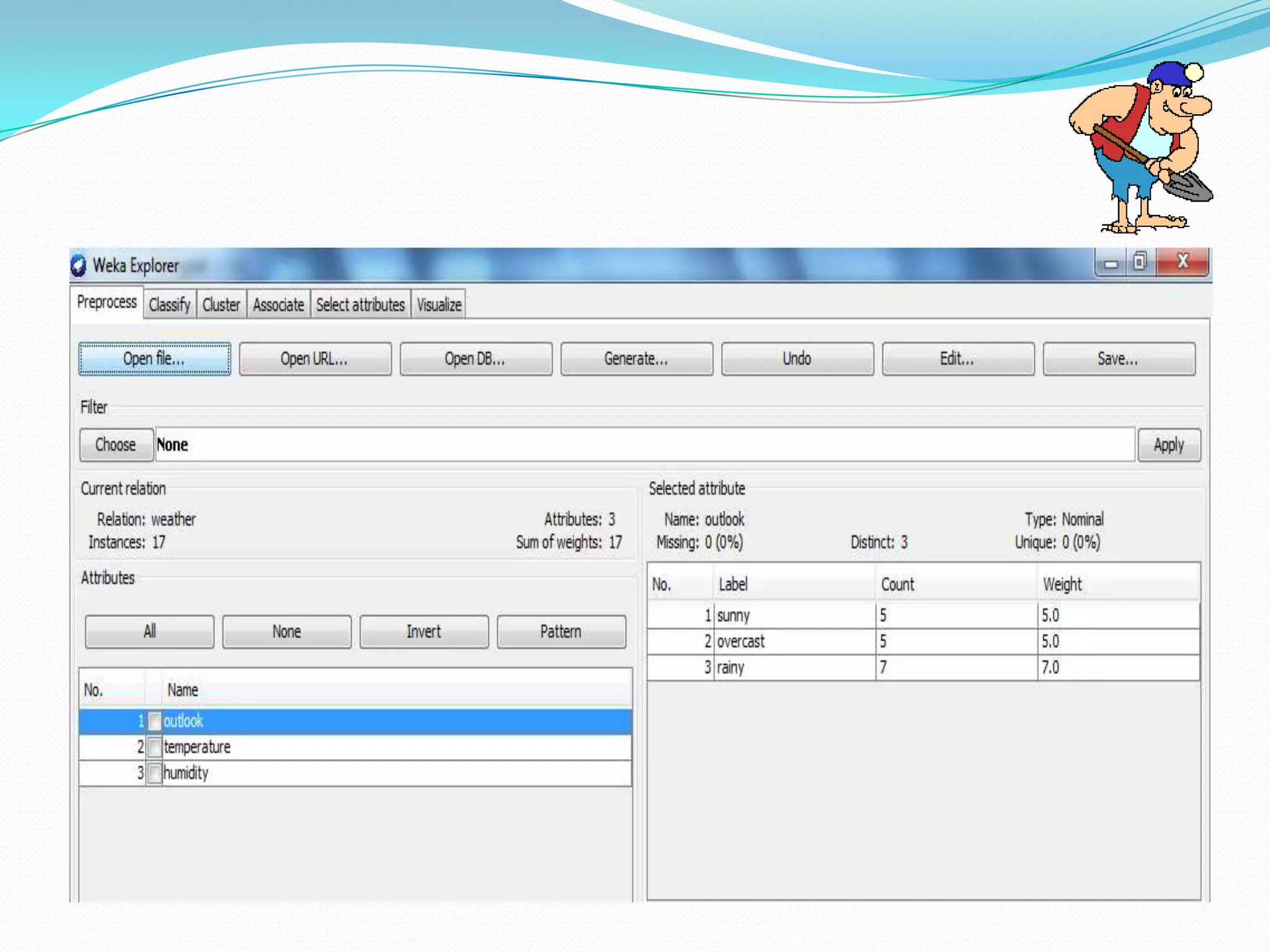
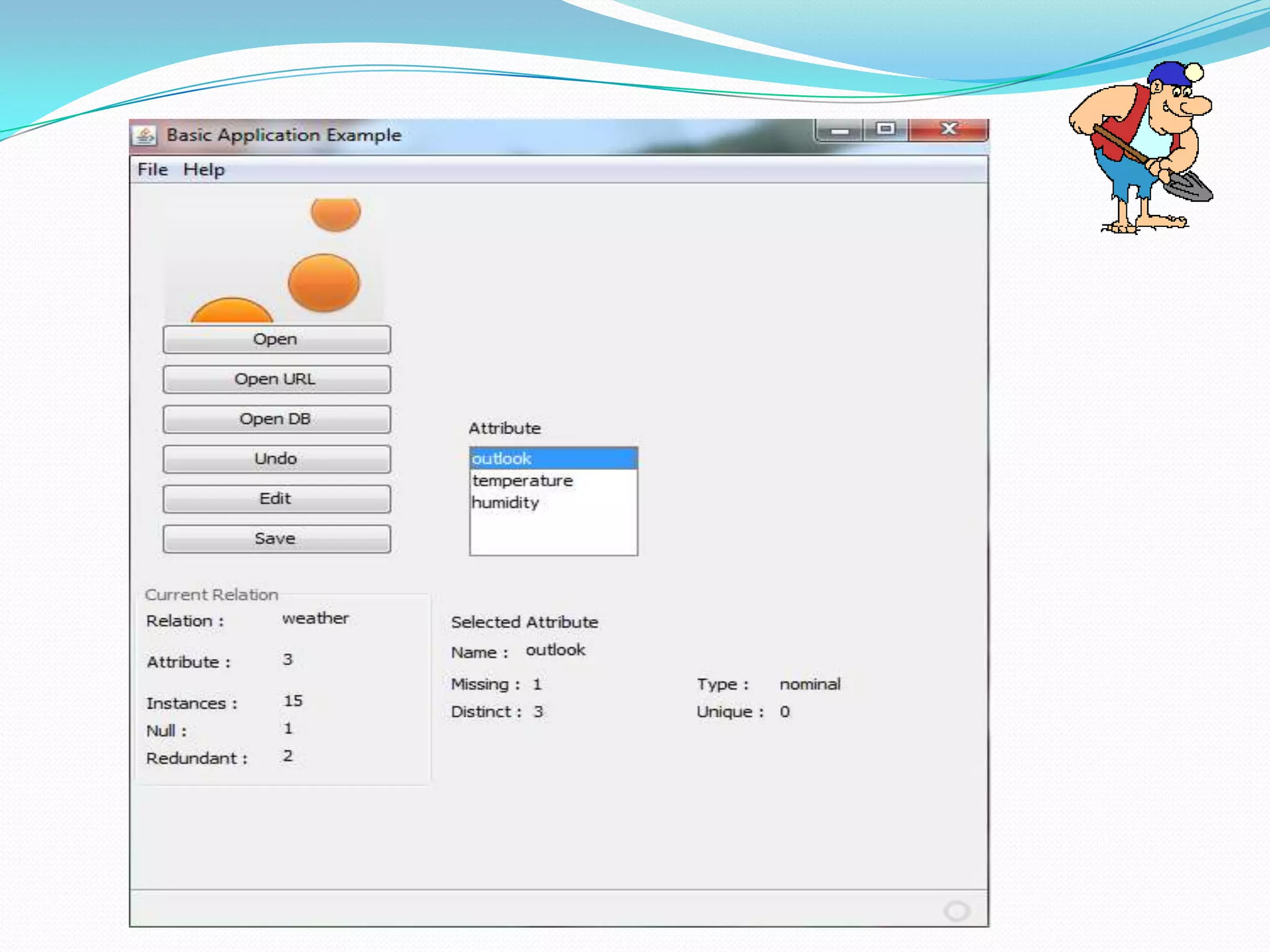
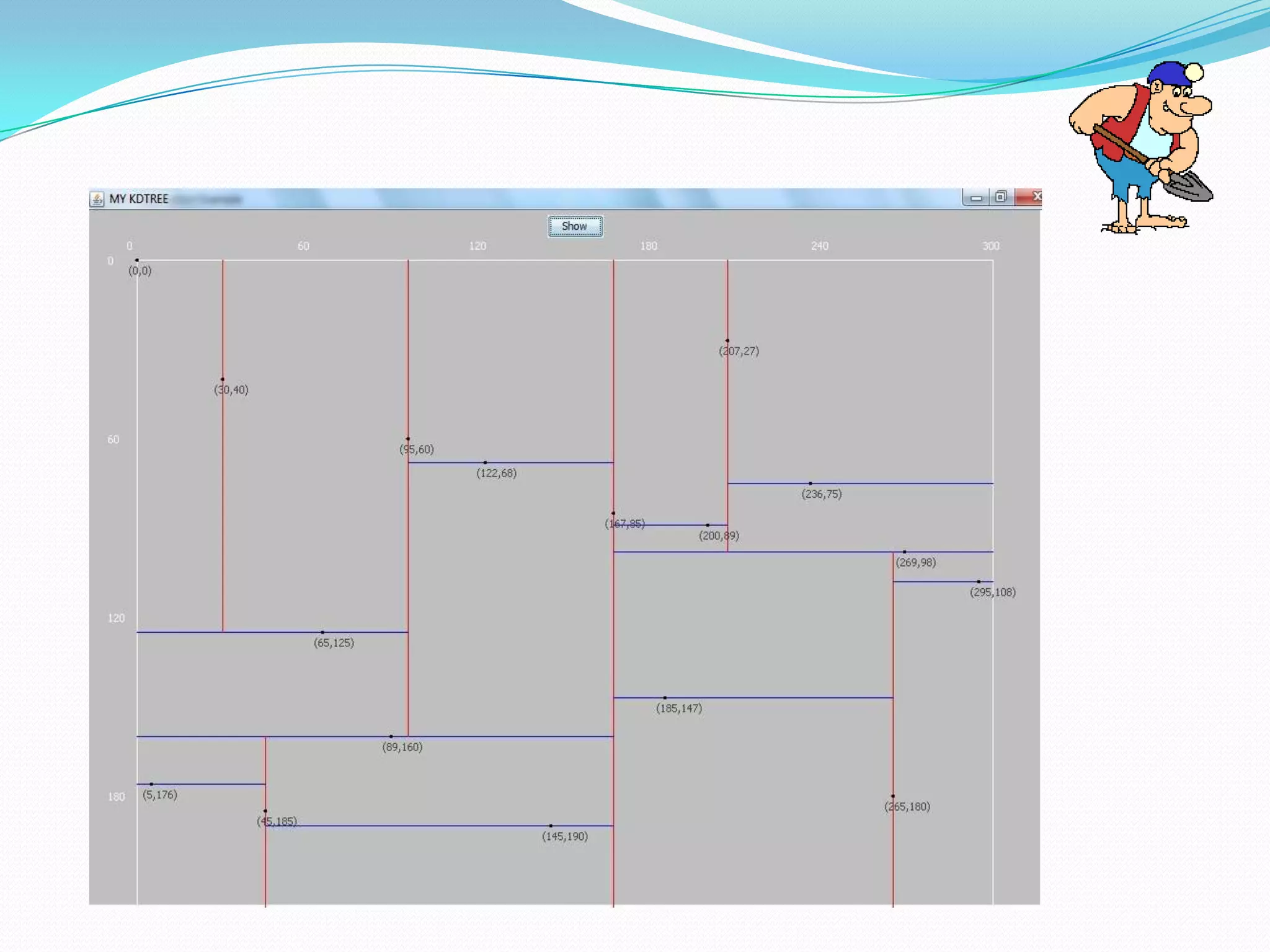
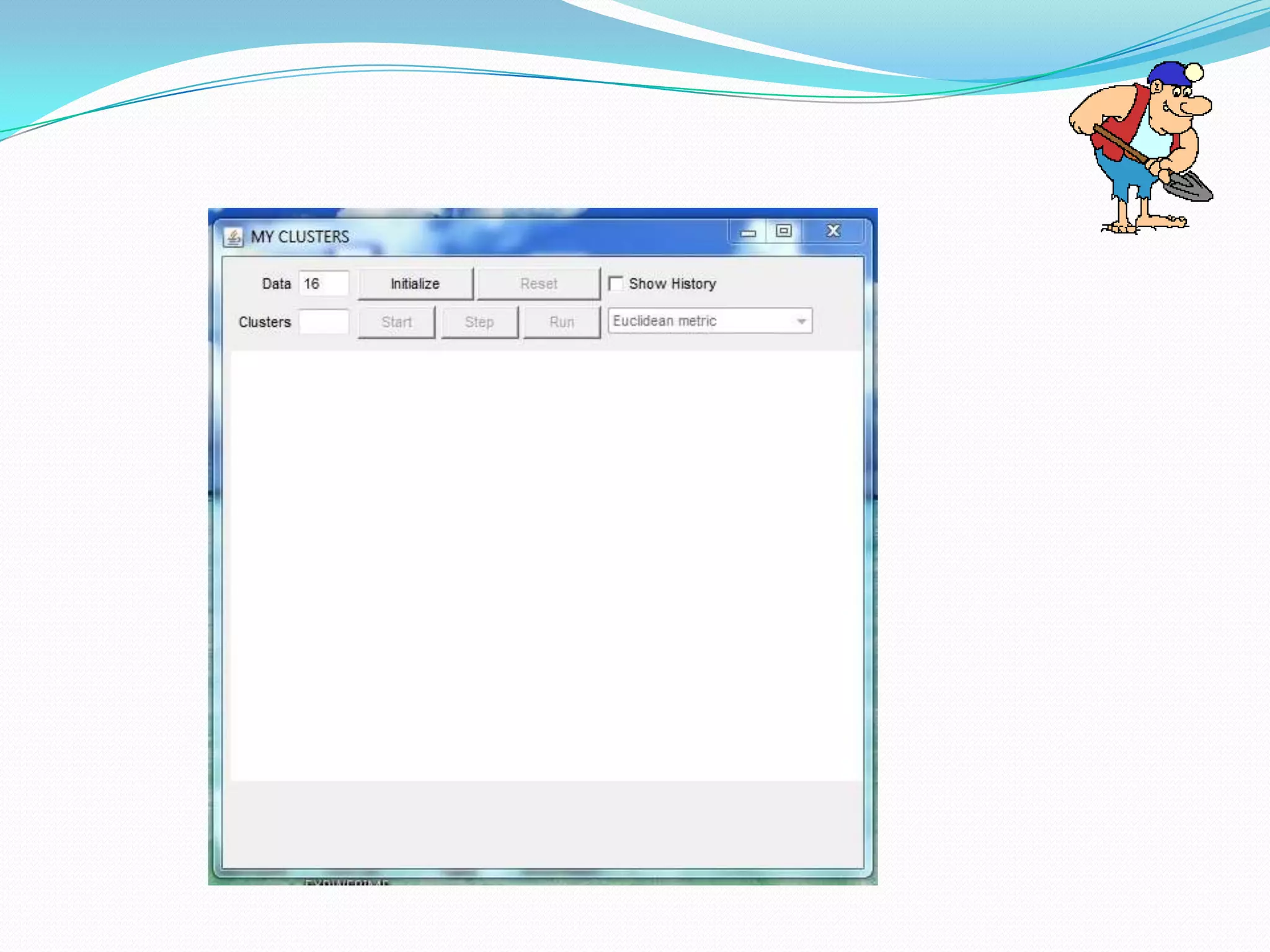
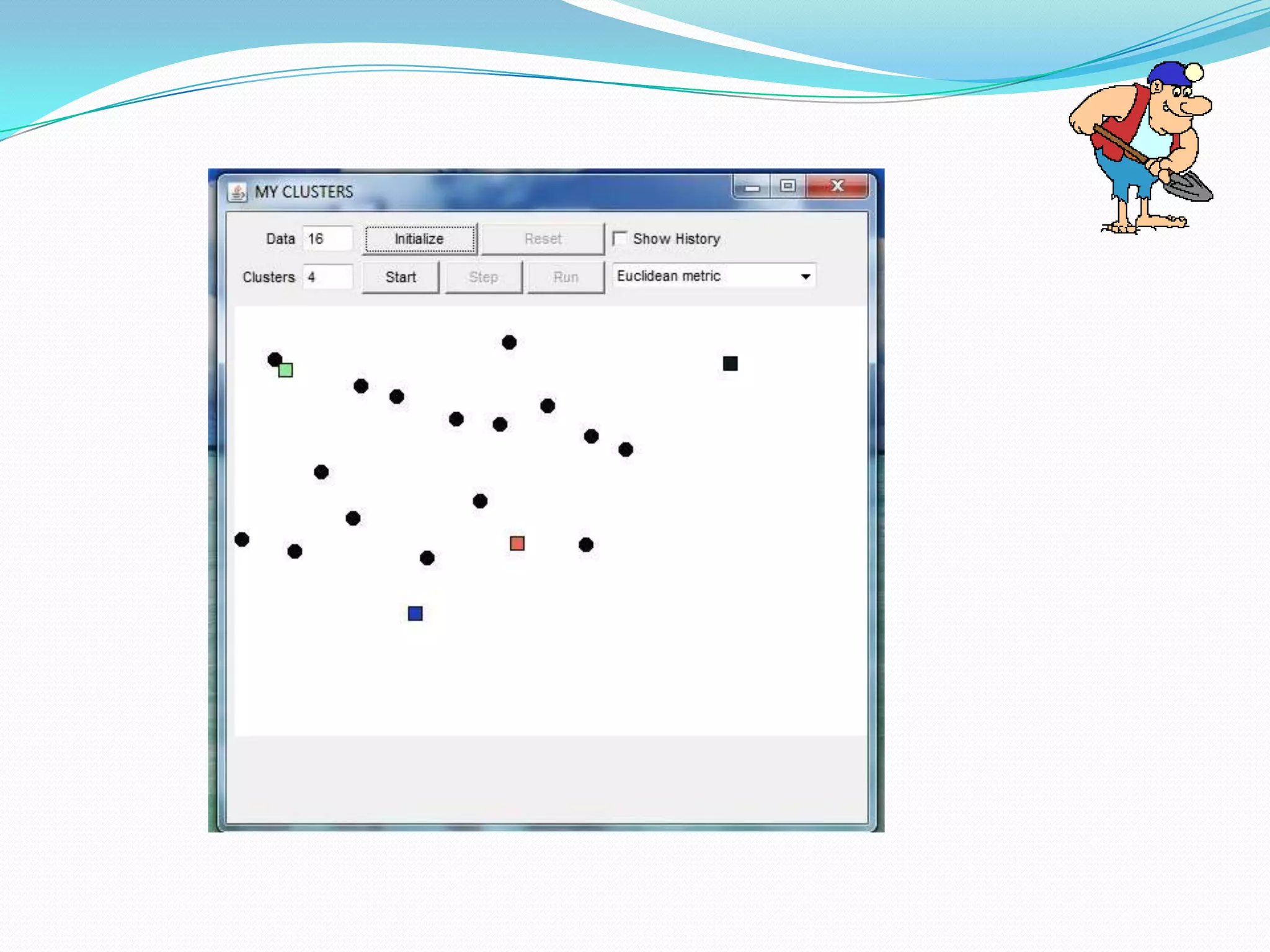
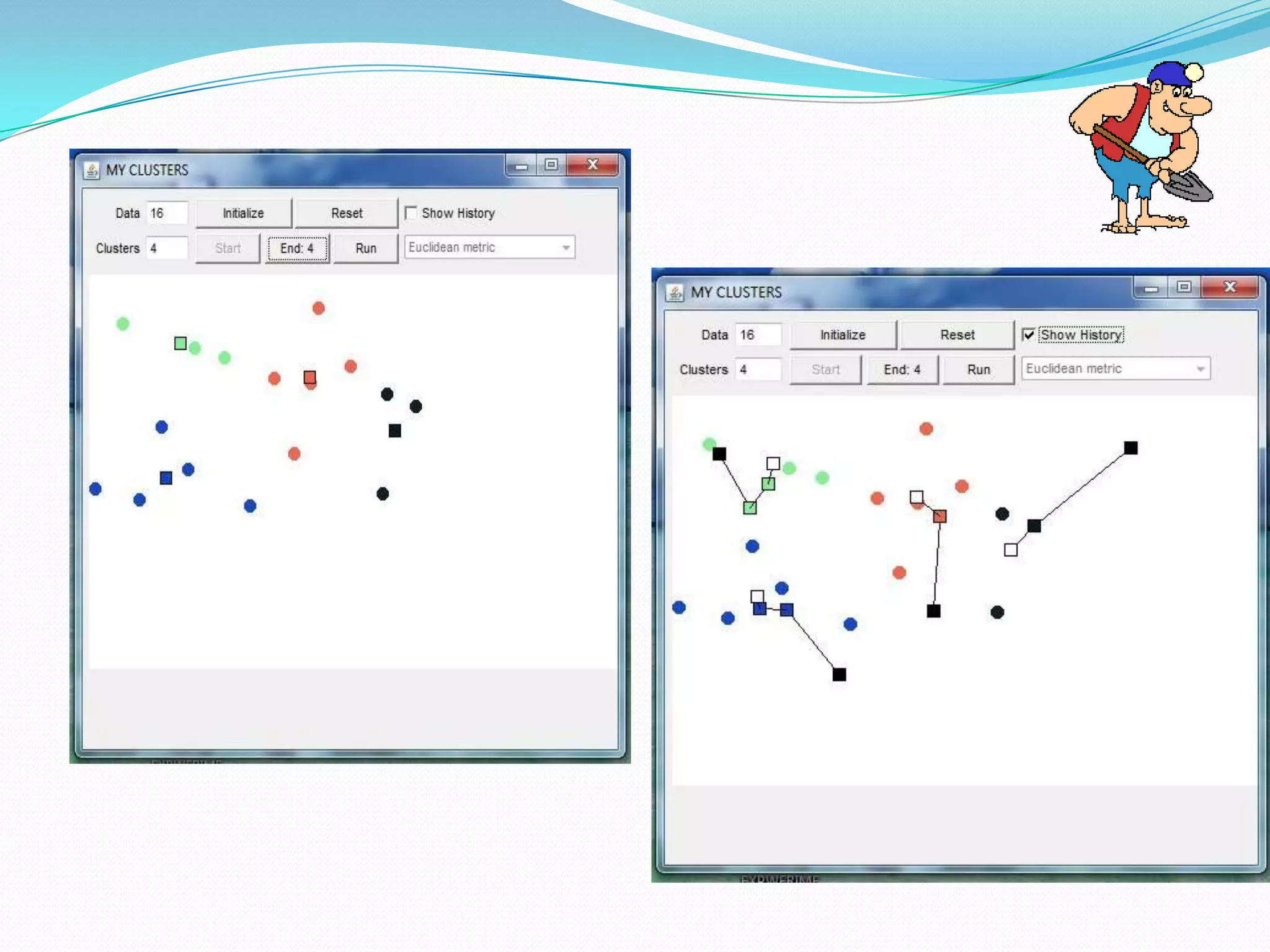
This document describes a new clustering tool for data mining called RAPID MINER. It discusses the need for clustering in applications like customer segmentation. The project aims to develop a new clustering algorithm using preprocessing techniques like removing null values and redundant data. It will implement clustering to distribute data into groups so that association is strong within clusters and weak between clusters. The document compares the new tool to Weka, discusses how it uses KD trees to improve efficiency over K-means clustering, and concludes that the new algorithm chooses better starting clusters and filters data faster using KD trees.
















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



