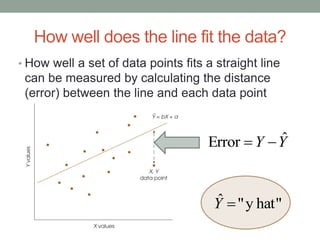
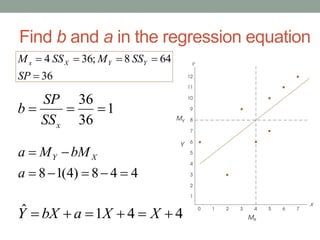
This document provides an overview of regression analysis. It defines regression as a statistical technique for finding the best-fitting straight line for a set of data. Regression allows predictions to be made based on correlations between two variables. The relationship between correlation and regression is examined, noting that correlation determines the relationship between variables while regression is used to make predictions. Various aspects of the linear regression equation are described, including computing predictions, graphing lines, and determining how well data fits the regression line.