Download to read offline










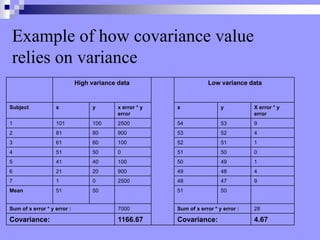


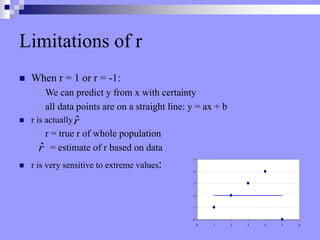

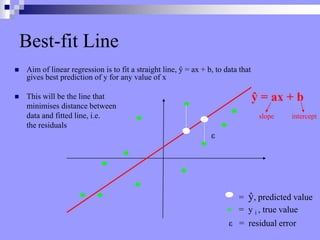

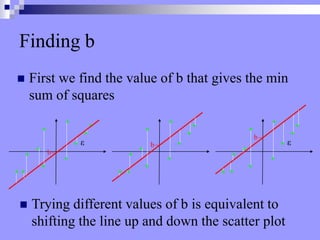
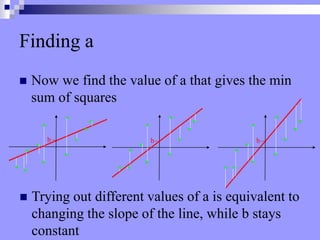
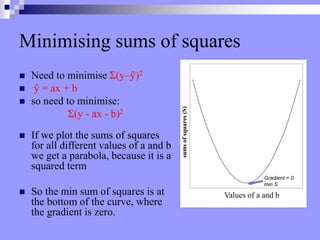












This document discusses correlation, regression, and the general linear model. It defines correlation as assessing the relationship between two variables, while regression describes how well one variable can predict another. Pearson's r standardizes the covariance between variables. Linear regression finds the best-fitting line that minimizes the residuals through the least squares method. The coefficient of determination, r-squared, indicates how much variance in the dependent variable is explained by the independent variable. Multiple regression extends this to include multiple independent variables. The general linear model encompasses both simple and multiple regression.


































































