- The authors propose a method called PRODEN for partial-label learning that is model-, loss-, and optimizer-agnostic.
- PRODEN introduces a classifier-consistent risk estimator and dynamically updates label weights during training to guide the model towards the true labels.
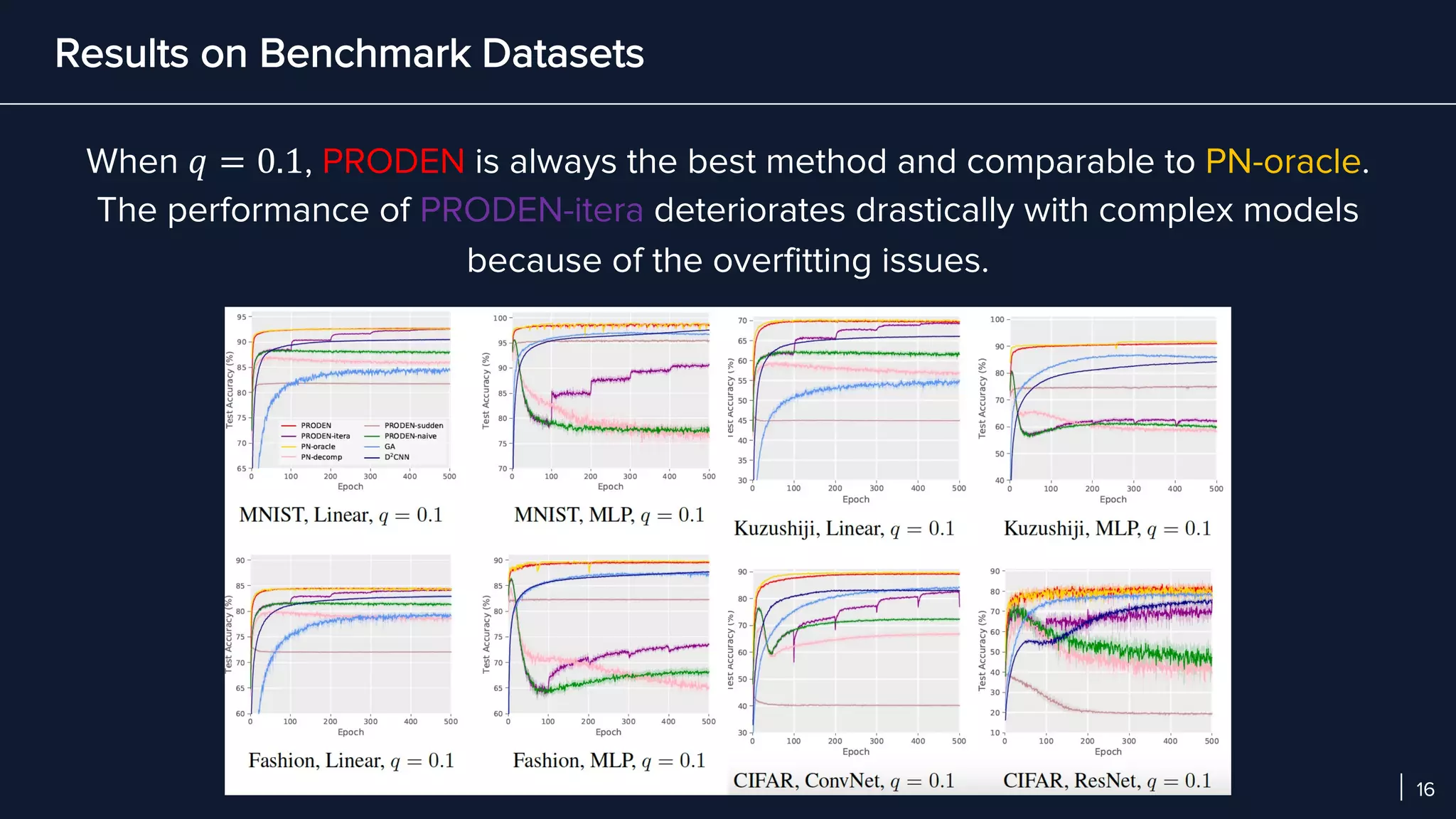
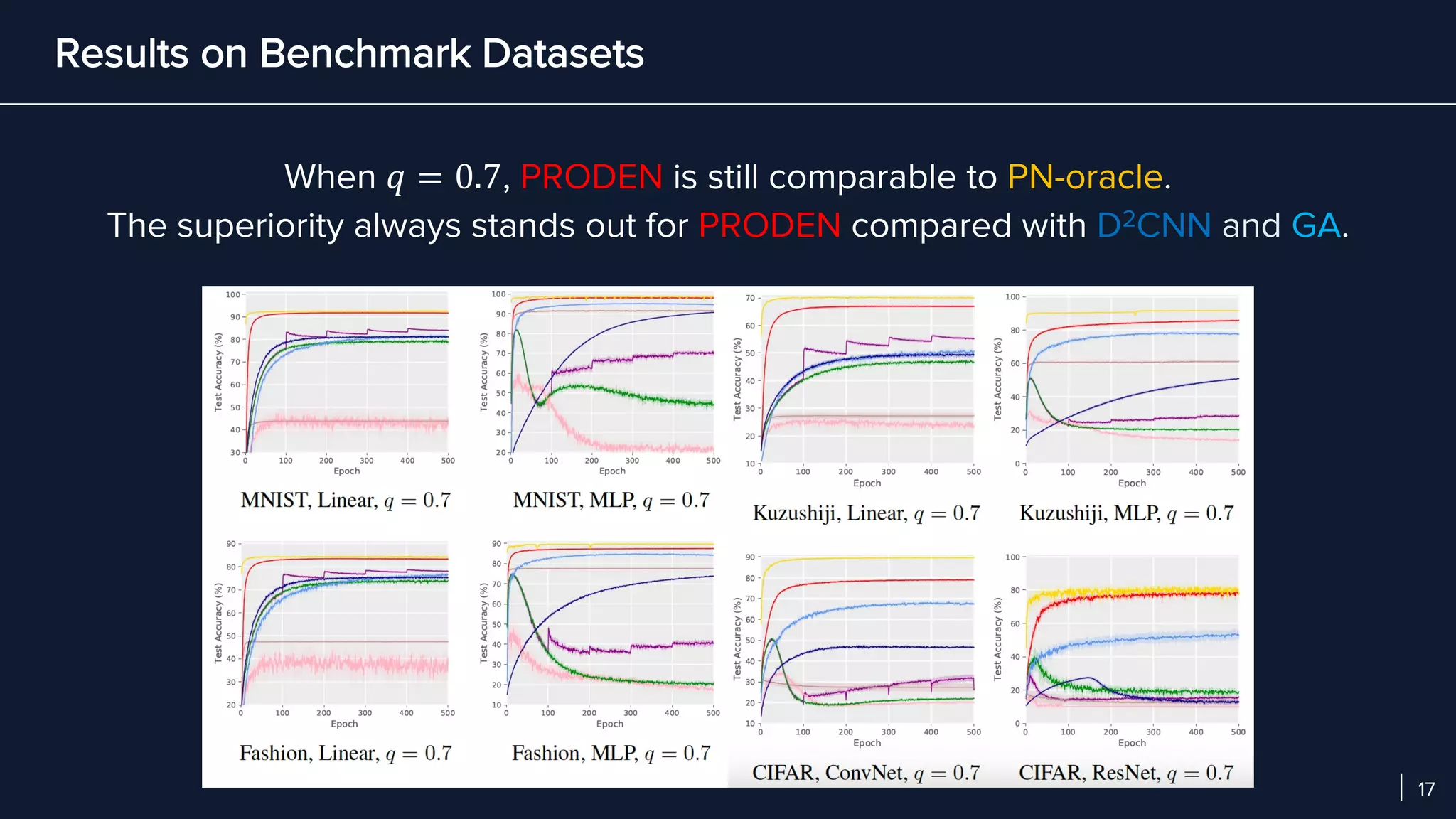
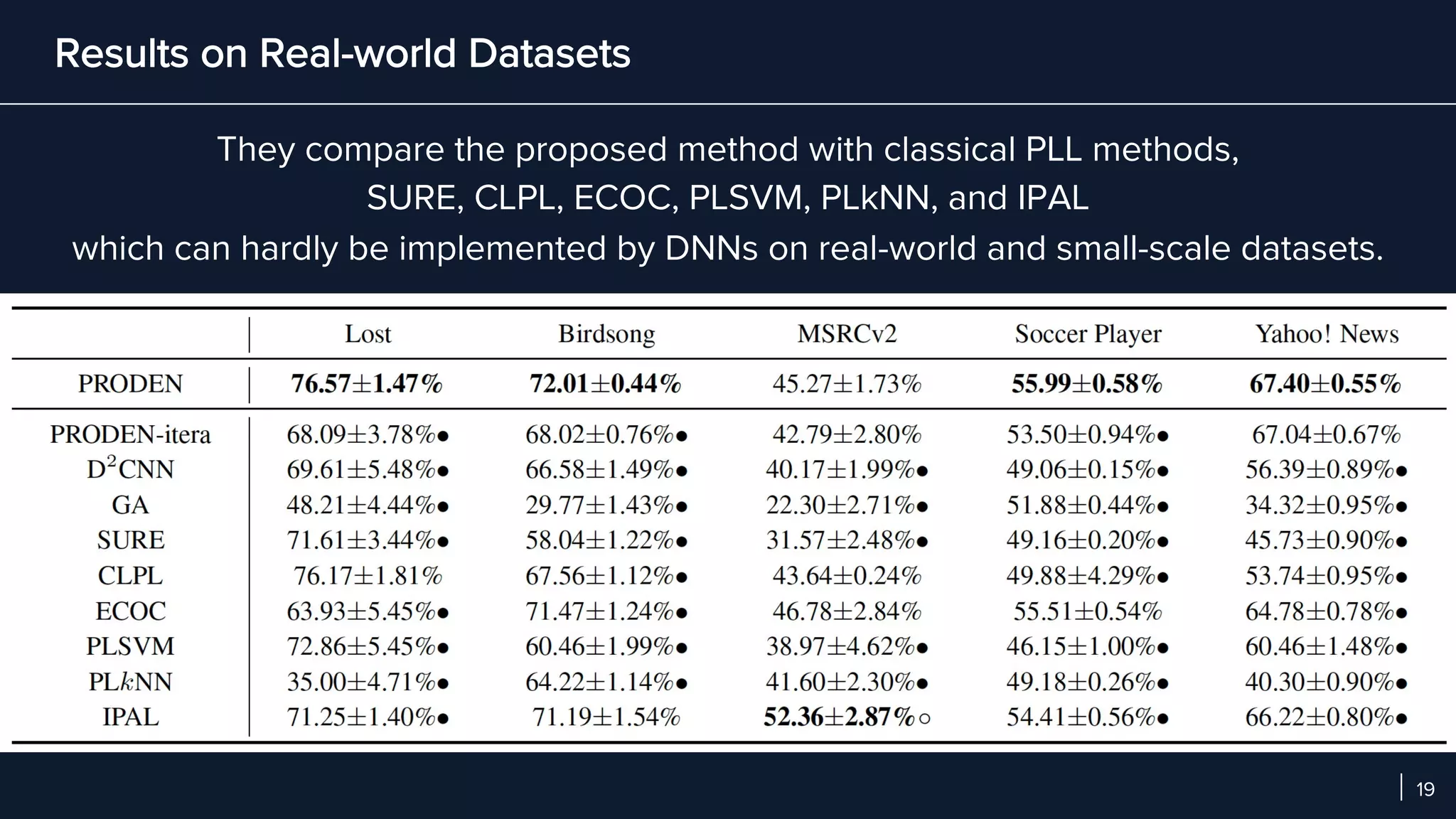
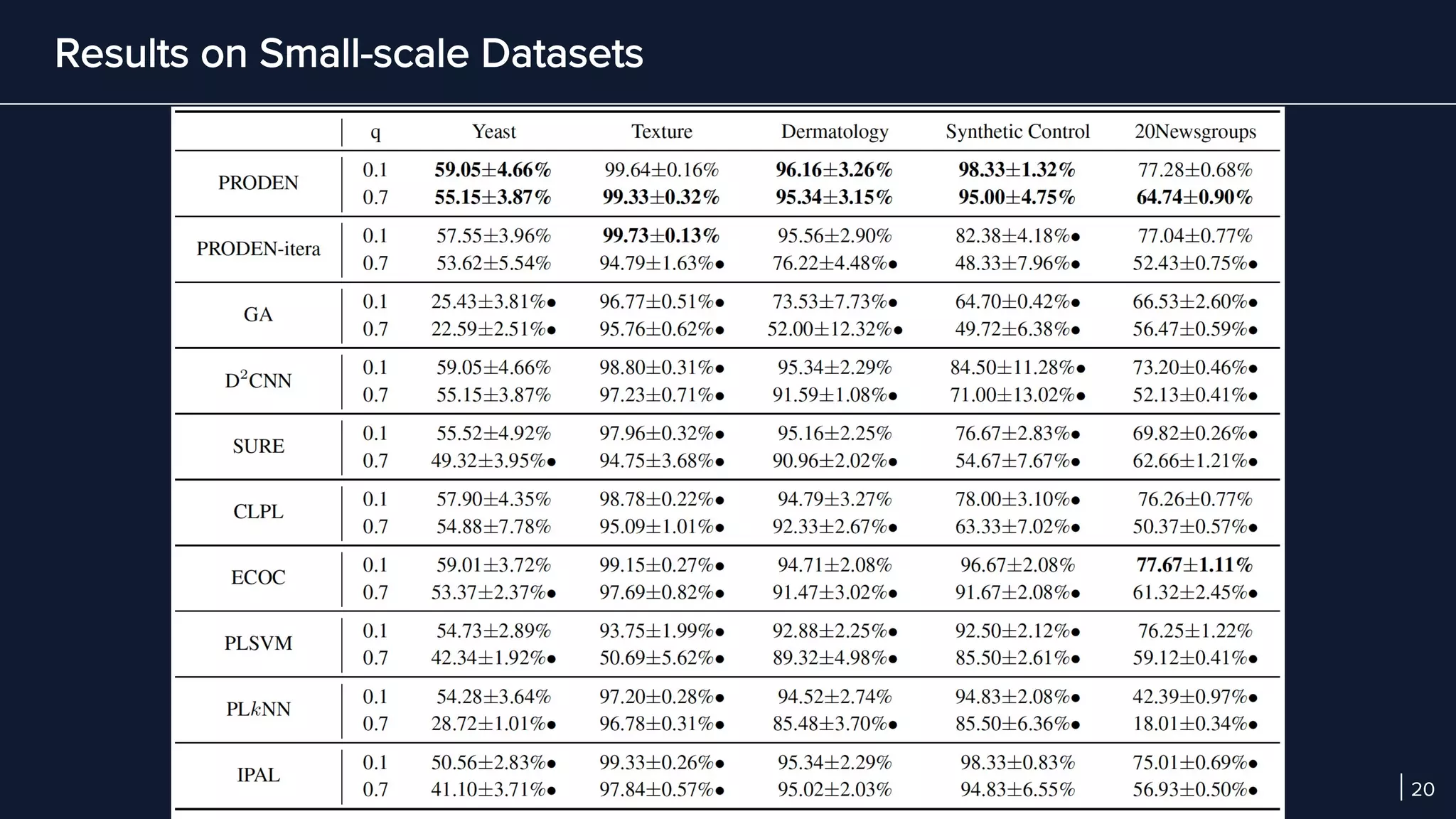
- In experiments on benchmark and real-world datasets, PRODEN achieves performance comparable to oracle labels and outperforms other partial-label learning baselines, demonstrating its effectiveness.



























![[第2版]Python機械学習プログラミング 第7章](https://cdn.slidesharecdn.com/ss_thumbnails/20181001-181029035713-thumbnail.jpg?width=640&height=640&fit=bounds)



































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)