Download to read offline



![3
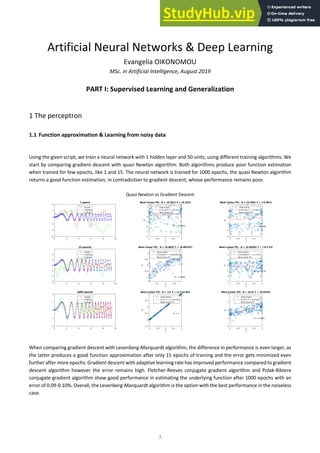
Levenberg-Marquardt vs GD GD with adaptive learning rate vs GD Fletcher-Reeves vs Polak-Ribiere
We proceed by adding noise to the data, training the models using different training algorithms like previously and by
calculating the mean squared error of the estimated outputs compared to the noiseless y values. In this case, the Fletcher-
Reeves, Polak-Ribiere and Levenberg-Marquardt algorithm after only 15 epochs approximate the underlying function
with the smallest training error, despite the noise in the data. Overall, the MSE are higher when there is noise in the data.
Without Noise With Noise 0.1*randn(1,length(y))
MSE Epoch 1 Epochs 15 Epochs 1000 Epoch 1 Epochs 15 Epochs 1000
GD 368.84% 185.40% 32.75% 572.02% 299.55% 21.27%
GD w Adaptive Learning 269.16% 176.25% 11.12% 601.91% 169.35% 11.67%
Fletcher-Reeves 206.56% 23.97% 0.09% 372.37% 19.77% 0.56%
Polak-Ribiere 237.89% 19.13% 0.10% 249.84% 41.75% 0.59%
quasi Newton 156.63% 11.30% 0.03% 314.56% 8.22% 0.70%
Levenberg-Marquardt 11.59% 0.01% 1.90E-09 12.85% 0.59% 0.71%
All the models get trained within a few seconds, with the longest being the training with 1000 epochs which lasts 3sec.
The basic gradient descent algorithm yields low performance, as the direction of the weights while training is not always
the direction of the local minima and the learning rate is an arbitrary fixed value. Those issues are tackled with Newton
method, where we consider the second order Taylor expansion in a point x* where gradient is zero. By analysing the
equations, we get w* = w - H-1
g, therefore the optimal weight vector w* is an update of the current weights w moving
towards a direction of gradient g, using a learning parameters H-1
, the inverse of the Hessian. Levenberg-Marquardt is
based on Newton method and it imposes the extra constraint of the step size ||Δx||2 = 1, therefore we consider the
Lagrangian. From the optimality conditions we obtain Δx = -[H + λΙ]-1
g. The term λΙ is a positive definite matrix that is
added to the Hessian in order to avoid ill-conditioning.
1.2 Personal Regression Example
In order to create the independent samples for the training and evaluation of Neural Networks, we merge all the data
(X1, X2, Tnew) into one matrix p with 3 rows and 13600 columns, in which the rows correspond to the two input variables
and the Target data. Afterwards, using the datasample command, we create 3 subsets out of p, with 3 rows and 1000
columns each. For training the model, we will use the first 2 rows as input variables and the last row as target data. In
order to visualize the training set, we create a 3D scatter plot with dimensions X1, X2 and Tnew.](https://image.slidesharecdn.com/artificialneuralnetworksdeeplearningreport-230806123646-81c19075/85/Artificial-Neural-Networks-Deep-Learning-Report-4-320.jpg)
![7
2 Long Short-Term Memory Networks
2.1 Time Series Prediction
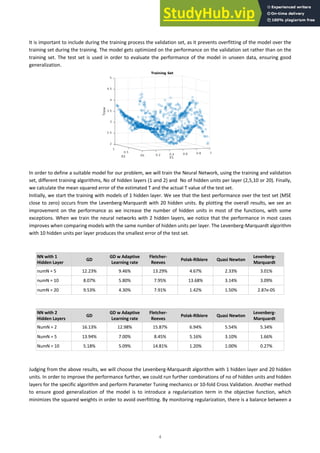
To make a prediction of the next 100 points of the Santa Fe dataset, we start by scaling the train set and the test set by
subtracting the mean of the whole dataset and devising by the standard deviation of the dataset. We use the
getTimeSeriesTrainData command to define the number of lags p, which produces a matrix [p x n] that is used as
training set. The training algorithm that we choose is the Levenberg-Marquardt, as it produced the best results during
the first exercise session. We train the model for several p values (lag) and number of neurons and calculate the MSE for
each combination. The winning pairs are p = 10 and numN = 5 and 10. We visualize the test target and the prediction and
indeed the results are satisfying.
MSE P = 2 P = 5 P = 10 P = 20 P = 50
numN = 2 22.1% 23.9% 2.1% 49.7% 2.6%
numN = 5 9.0% 8.0% 0.8% 2.4% 40.1%
numN = 10 5.6% 5.7% 0.8% 7.6% 27.1%
numN = 20 4.9% 3.1% 0.9% 2.0% 18.1%
numN = 50 6.4% 4.9% 1.5% 30.4% 44.2%
Santa Fe Time-Series prediction, p = 10, numN = 10
2.2 Long short-term memory network
The advantage of using LSTM over Neural Network is that this framework allows us to retain past information in the
training of the model and use it as “memory” in order to make predictions based on current data and relevant learnings
that were obtained in the past. LSTM is able to select on each state which information to delete from the past, which
information to retain and which to further memorise. This structure effectively tackles the challenge of vanishing gradient
that appears in Neural Networks, where the gradient of past moments becomes very small after a number of iterations,
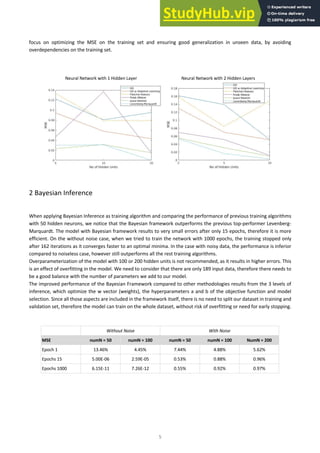
therefore the model is not able to retain the information of the past and inform future predictions. The below diagram
shows the structure of an LSTM model and the operations that take place on a single cell in each iteration.](https://image.slidesharecdn.com/artificialneuralnetworksdeeplearningreport-230806123646-81c19075/85/Artificial-Neural-Networks-Deep-Learning-Report-8-320.jpg)
![8
Figure: The LSTM cell structure
Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
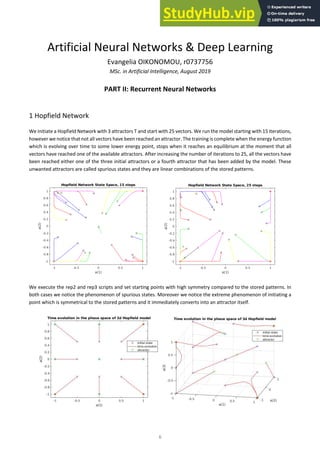
In order to optimize the model, we test different no of neurons, similar to the Neural Network case, and then try different
combinations of Initial Learn rate and Learn Rate Drop Factor. The Learn Rate controls how much the model changes
after each iteration with respect the loss gradient. A very small learning rate might lead to long training process as it
requires many iterations, while a large value for this hyperparameter might change the W vector to fast in the training
process. The below visualizations explain the impact of learning rate on the gradient descent and convergence of training
process.
Gradient descent with small (top) and large (bottom) learning rates. Effect of various learning rates on convergence (Img Credit: cs231n)
Source: Andrew Ng’s Machine Learning course on Coursera
The other 2 hyperparameters that we tune are the Learn Drop Factor and Learn Drop Period. For instance, a drop factor
of 0.2 and Learn drop Period of 125, it means that the learning rate gets reduced with a factor of 0.2 every 125 iterations.
We train the model, using different values of hyperparameters.
numNlist = [5, 10, 20, 50];
LearnRateList = [0.001, 0.005, 0.01, 0.05, 0.1];
DropFactorList = [0.1, 0.2, 0.5];
DropPeriodList = [25, 50, 125];
Below the learnings from training:
- Small Learn Rates perform better compared to larger values, therefore 0.005 would be our best options. Large
values eg. 0.05 or 0.1 result in large errors as the weights are changing too rapidly in each iteration, therefore
they are not considered in practice.
- Having a small drop period, i.e reducing the learning rate after 25 or 50 iterations, leads to fast decreasing of the
learn rate, therefore the error does not change for the largest part of the training. We set the Drop Period to
125.
- A drop factor of 0.1 reduces the learning rate to 10% of the initial one, while a drop factor of 0.5 only halves it.
We notice during training, that a small drop factor of 0.1 or 0.2, especially when initial learning rate is already
small, results to inefficient training as there is only minimal improvement of the training error.](https://image.slidesharecdn.com/artificialneuralnetworksdeeplearningreport-230806123646-81c19075/85/Artificial-Neural-Networks-Deep-Learning-Report-9-320.jpg)




![13
Model 1 2 3 4
Architecture layers = [imageInputLayer([28 28 1])
convolution2dLayer(5,12)
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(5,24)
reluLayer
fullyConnectedLayer(10)
softmaxLayer
classificationLayer()];
layers = [imageInputLayer([28 28 1])
convolution2dLayer(3,12)
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,24)
reluLayer
fullyConnectedLayer(10)
softmaxLayer
classificationLayer()];
layers = [imageInputLayer([28 28 1])
convolution2dLayer(3,16)
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,32)
reluLayer
fullyConnectedLayer(10)
softmaxLayer
classificationLayer()];
layers = [imageInputLayer([28 28 1])
convolution2dLayer(3,16)
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,32)
reluLayer
convolution2dLayer(3,48)
fullyConnectedLayer(10)
softmaxLayer
classificationLayer()];
Training
Accuracy
Training Time 48,15 sec 40,39 sec 44,18 sec 62,54 sec
Accuracy 0,8344 0,9092 0,9488 0,9668
The model increases in accuracy, when the filter size gets smaller in convolution layer, from 5x5 to 3x3. Further
improvements occur by increasing the No of filters and by adding a third Convolutional layer. Applying those changes,
the accuracy increases by 13,3 percentage points, from 83,4% to 96,7%, while the mini batch accuracy in the final epochs
reaches 100%.](https://image.slidesharecdn.com/artificialneuralnetworksdeeplearningreport-230806123646-81c19075/85/Artificial-Neural-Networks-Deep-Learning-Report-14-320.jpg)
![14
Deep Learning & Artificial Neural Networks
Evangelia OIKONOMOU, r0737756
MSc. in Artificial Intelligence, August 2019
PART IV: Generative Models
1 Restricted Boltzmann Machines
For RBMs training, it is not tractable to use Max Likelihood, therefore we solve with Contrastive Divergence (CD) [Hinton,
2002] algorithm. To perform sampling we use Gibbs sampler, with T steps, where T=1 often in practice.
To optimize the model we tune the No of components, No of iterations and Learning Rate. No of components correspond
to No of binary hidden units. The model performs better when increasing the number of hidden units as it learns more
patterns from the training set, however the training time is longer. To avoid long training time, we reduce the no of
iterations. The learning rate controls how much the weights change after each iteration. A large learning rate results in
faster learning, with the downside that it might converge to a sub-optimal set of weights. A small learning rate allows the
model to learn a more optimal or even global-optimal set of weights, however the training takes longer as many iterations
are required. In order to define a combination of hyperparameters for optimal performance, we can either manually try
different combinations or we can perform Parameter Tuning with GridSearchCV.
Below the sampling images generated by the model with No of components = 100, Learning Rate = 0,05, No of Iterations
= 30 and Gibbs steps = 1, compared to the real images. The model produces realistic images which are close to the original
input.
Sampling Images
Real Images
For the reconstruction of unseen images, 1 Gibbs step is not enough to get a good reconstruction, therefore we increase
this hyperparameter to 10 or 15. The reconstructed images are not perfect, on the contrary they are corrupted. The
reconstructions become unreadable after we remove 20 rows.](https://image.slidesharecdn.com/artificialneuralnetworksdeeplearningreport-230806123646-81c19075/85/Artificial-Neural-Networks-Deep-Learning-Report-15-320.jpg)


![17
4 Optimal Transport
The Optimal Transport is a popular mathematical framework used to minimize the distance between two marginal
distributions p and q, where p corresponds to the model distribution pθ, and q corresponds to data distribution. This is
solved by considering the Wasserstein Distance between the two marginal distribution, which equals to minimization of
expected value of the probability distribution π over the distances x and x’. It can be expressed as Linear Optimization
problem with contraints, solved by taking the Lagrangian. It solves a common challenge called the assignment problem,
when a quantity of goods represented by marginal probability distributions has to be transported from one place to
another, by minimizing the cost and taking into account the quantities required by the receiving part. W(p, q) = minπ∈Π(p,q)
Eπd(x, x′), with d(x, x′) a distance metric.
In the given script, OT is used in order to transfer the colors between two images. The chosen images show the same
landscape during different times of the day. By executing the code, the color pallet from the first image is transported to
the second image and vice versa.
Optimal Transport has been applied to GANs, making use of the Wasserstein distance between the distributions of the
Generator and Discriminator. The so-called WGAN is more stable during learning compared regular GANs, as we omit the
sigmoid function in front of the function D, therefore its output is real values instead of probabilities between [0,1]. Due
to the zero-sum game, the sum of the Cost function for the discriminator D and generator G is equal to zero.
W(D)
(D,G) = Ex∼pdata[D(x)] − Ez∼pz[D(G(z))]
W(G)
(D, G) = −W(D)
(D, G)
Below we train a standard GAN and a Wasserstein GAN. Both methods produce bad results due to the simple fully-
connected architecture for training efficiency. The Wasserstein GAN tackles better the noise compared to the standard
GAN.
Standard GAN Wasserstein GAN](https://image.slidesharecdn.com/artificialneuralnetworksdeeplearningreport-230806123646-81c19075/85/Artificial-Neural-Networks-Deep-Learning-Report-18-320.jpg)

The document summarizes the results of an exercise on artificial neural networks and deep learning. It covers topics like supervised learning algorithms, recurrent neural networks, deep feature learning, and generative models. For a regression problem, it finds that a neural network with one hidden layer, 20 hidden units, and trained with the Levenberg-Marquardt algorithm achieves the best performance on a test set, with a mean squared error close to zero. Further improvements could involve additional hyperparameter tuning, cross-validation, or adding regularization to improve generalization.



































































