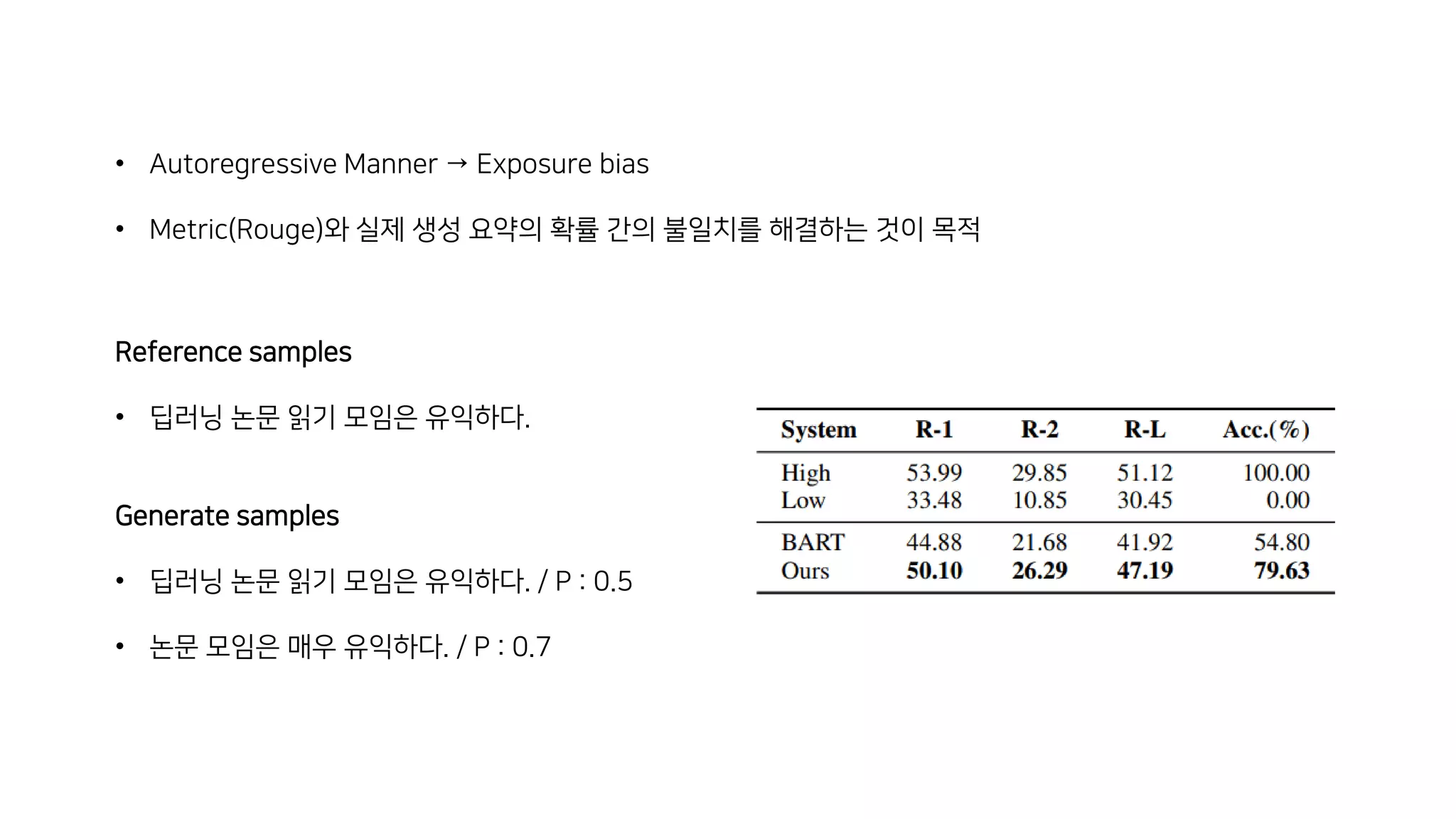
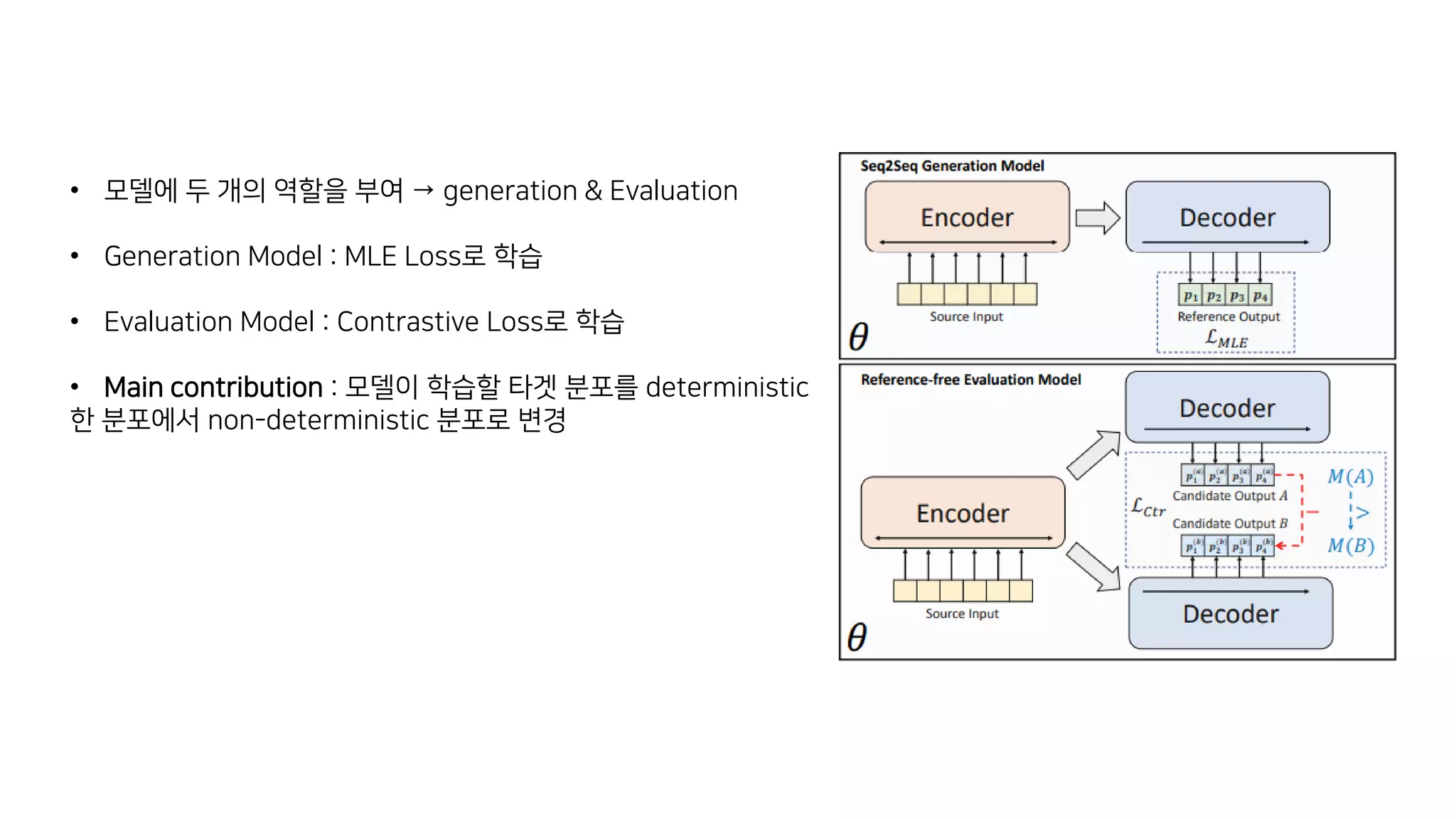
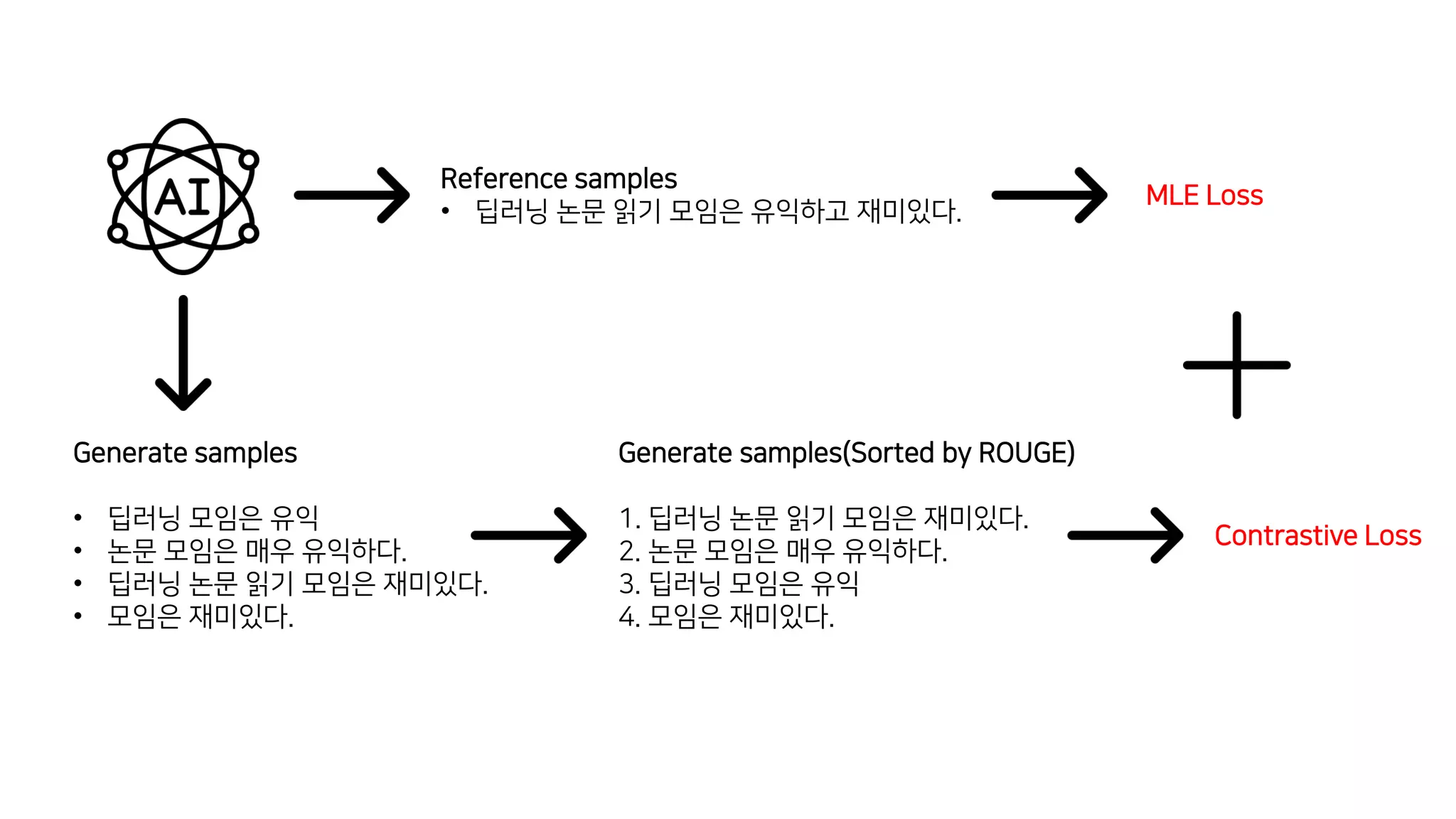
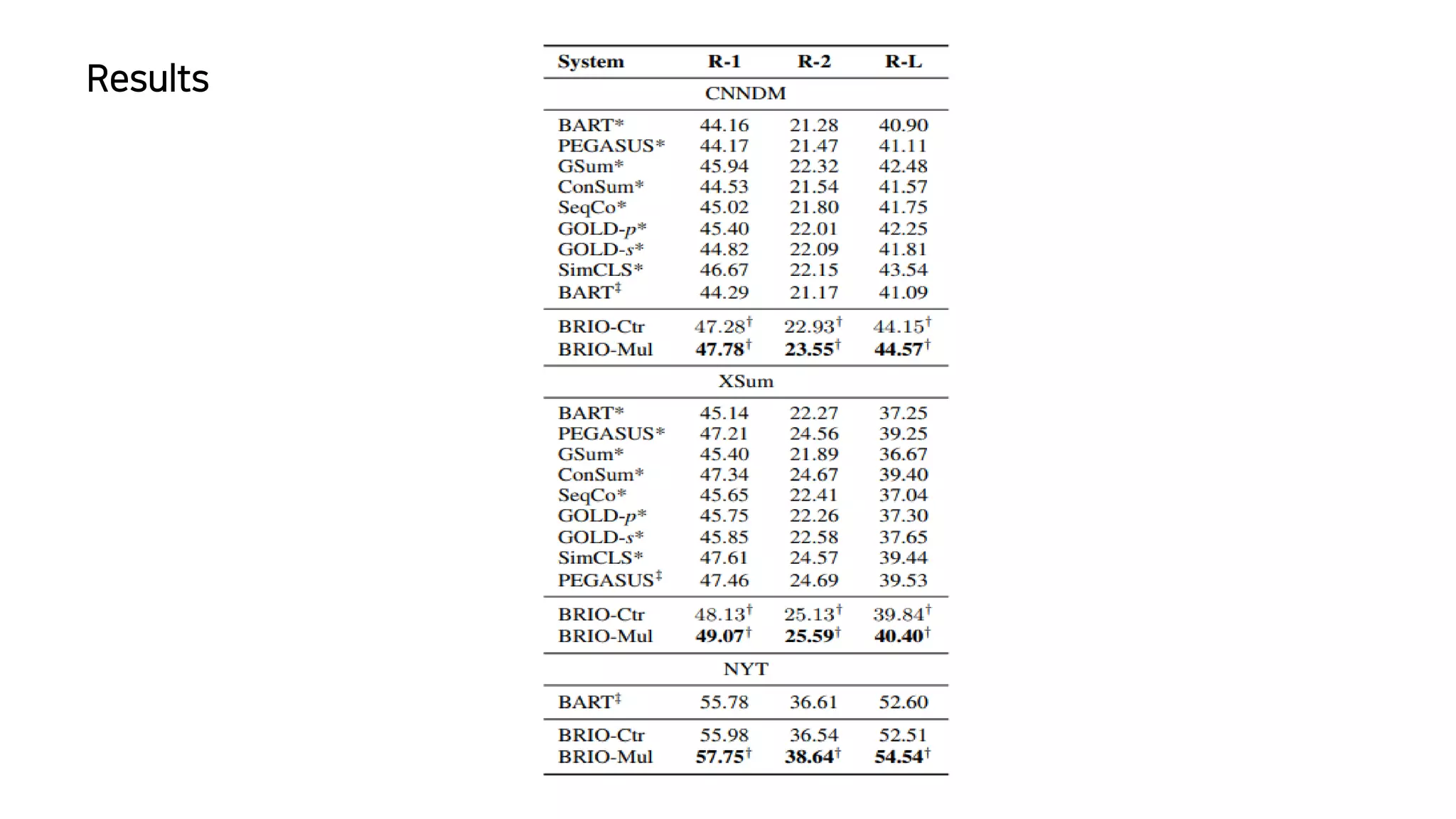
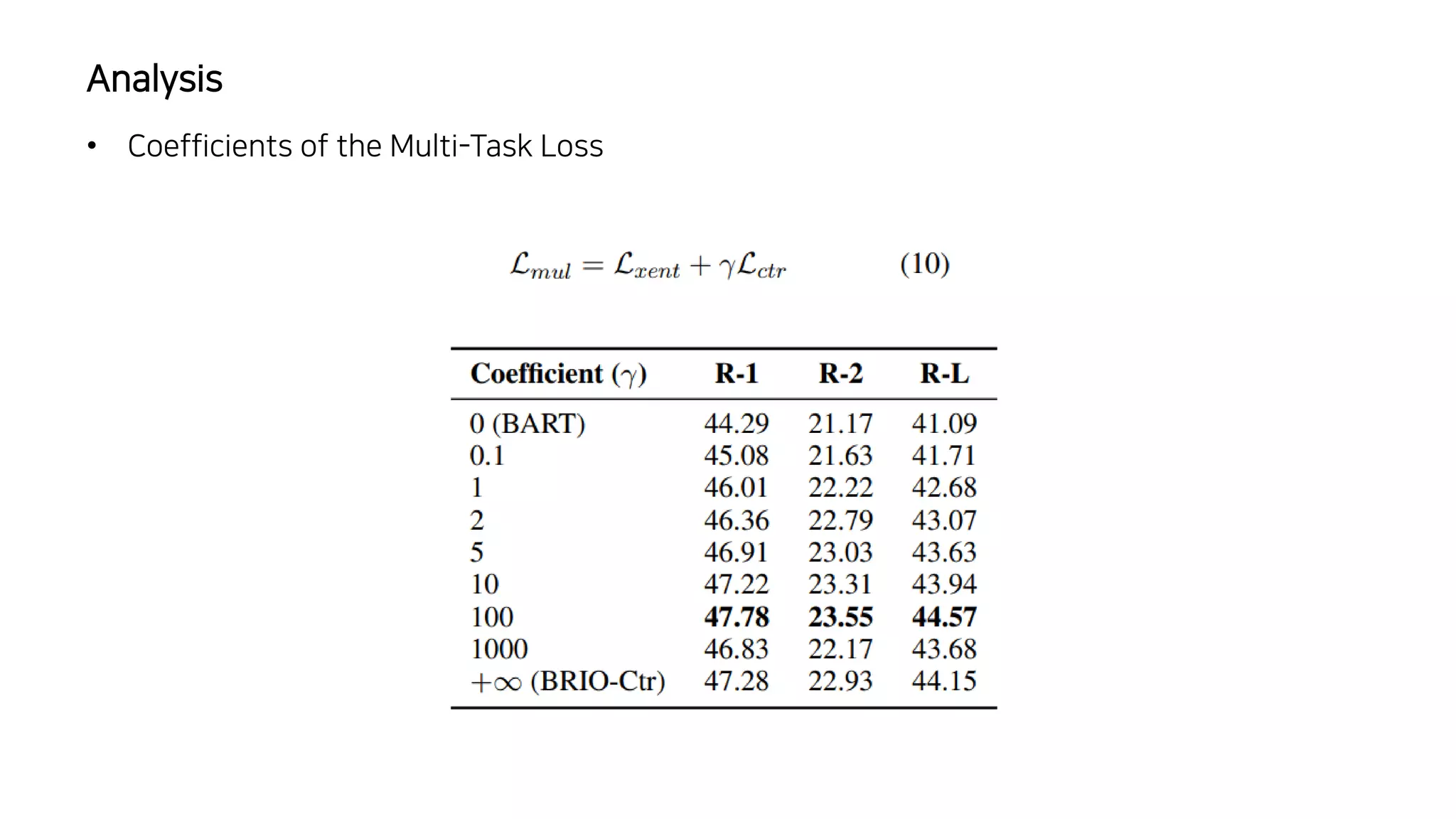
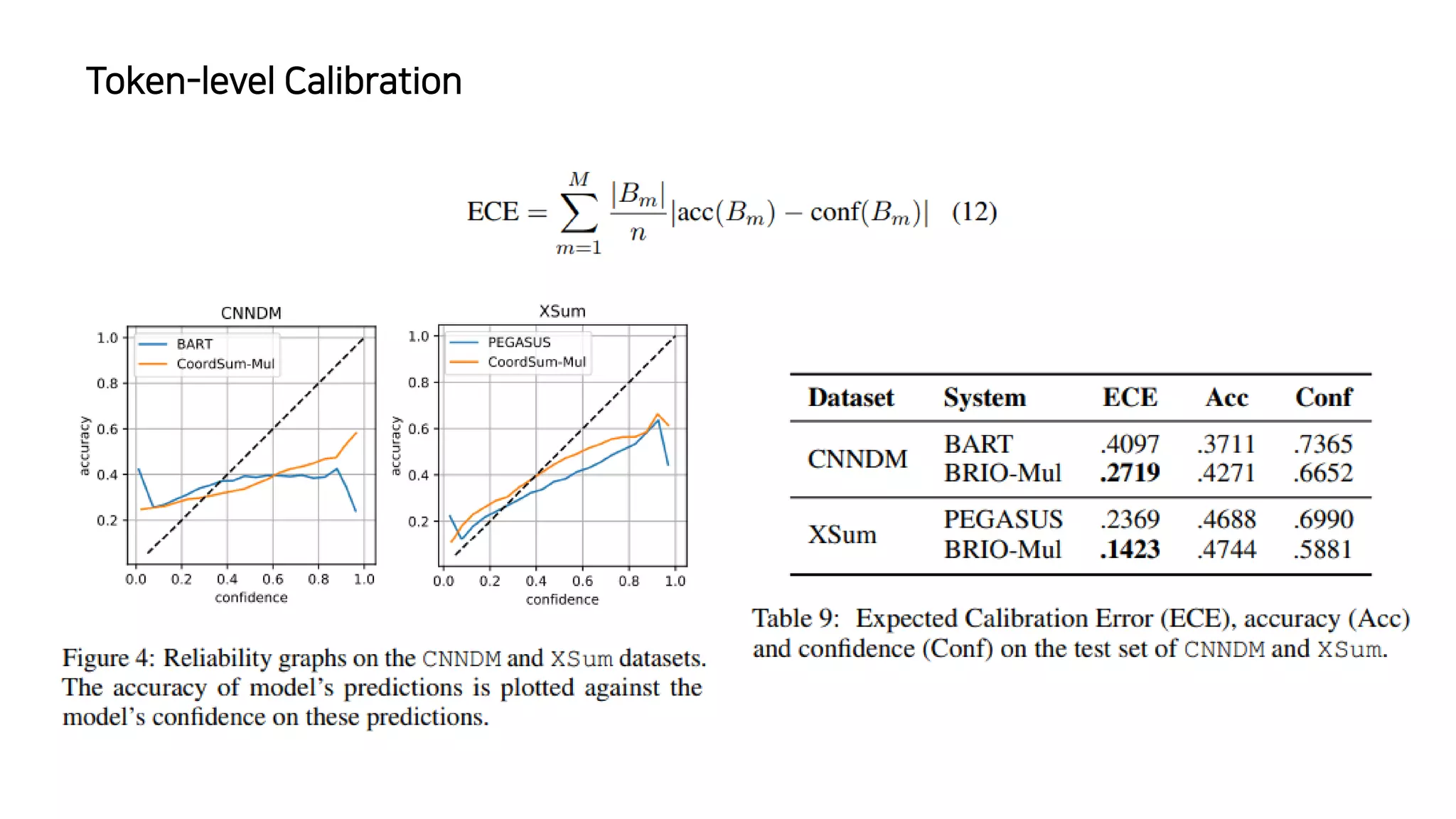
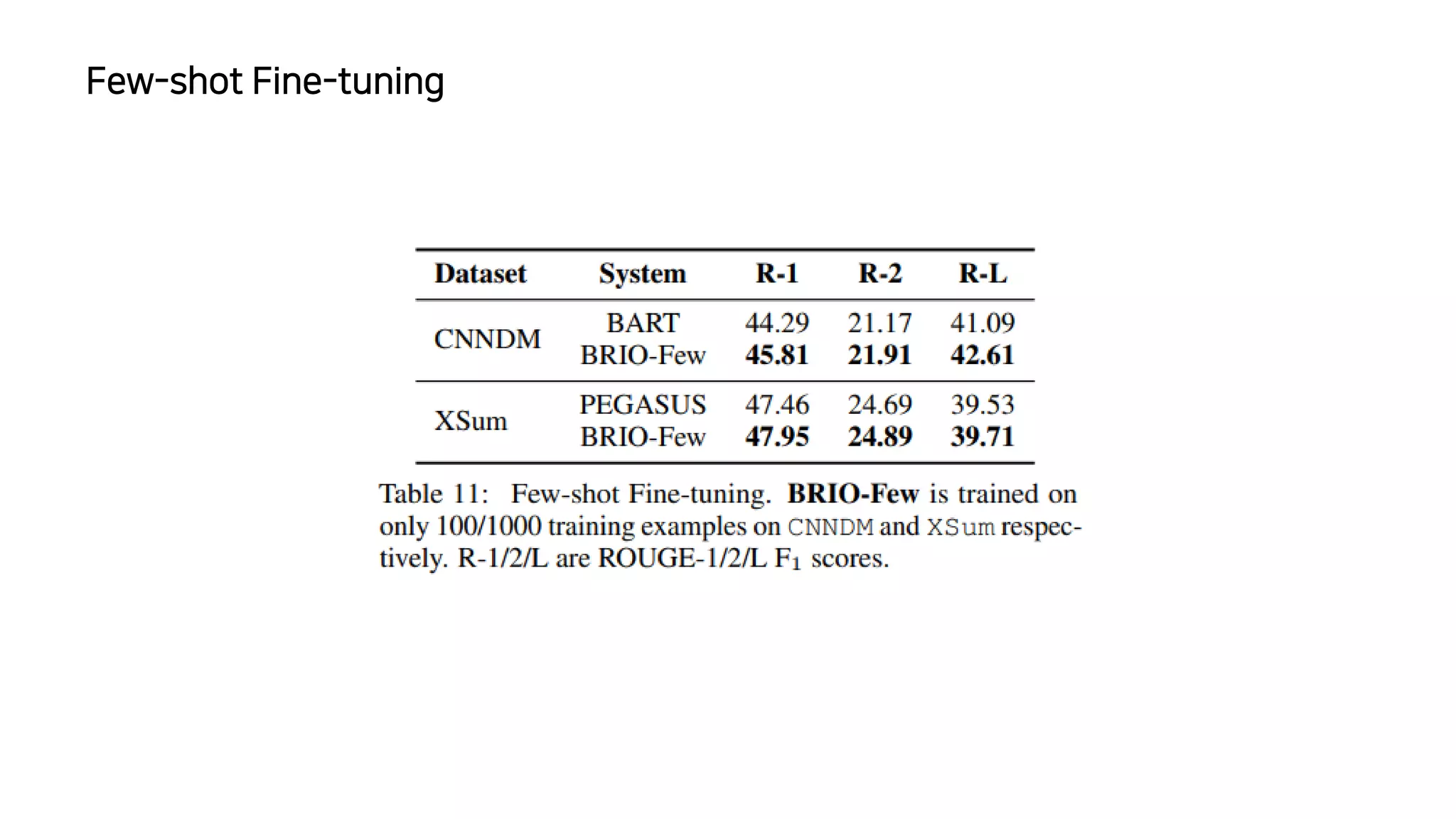
이 논문에서는 추상적 요약 모델의 훈련 방식에 대해 논의하고 있습니다. 일반적으로 이러한 모델은 최대 가능도 추정을 사용하여 훈련되는데, 이는 이상적인 모델이 모든 확률 질량을 참조 요약에 할당할 것이라고 가정하는 결정론적인 목표 분포를 가정합니다. 이런 가정은 추론 과정에서 성능 저하를 초래할 수 있는데, 모델이 참조 요약에서 벗어난 여러 후보 요약을 비교해야 하기 때문입니다. 이 문제를 해결하기 위해, 저자들은 서로 다른 후보 요약들이 그들의 품질에 따라 확률 질량을 할당받는 비결정론적 분포를 가정하는 새로운 훈련 패러다임을 제안합니다. 이 방법은 CNN/DailyMail (47.78 ROUGE-1) 및 XSum (49.07 ROUGE-1) 데이터셋에서 새로운 최고 성능을 달성했습니다.





























![[MINDsLab]maum.ai platform_Introduction_20230220.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/maum-230219111620-8332bb81-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[Paper Review] What have we achieved on text summarization?](https://cdn.slidesharecdn.com/ss_thumbnails/whathaveweachievedontextsummarizationhangil-210127184856-thumbnail.jpg?width=640&height=640&fit=bounds)



























