Download as PDF, PPTX










![www.scling.com
● Expressive
● Custom types
● IDE support
● Avro for data lake storage
Schema definition choice
37
● RDBMS: Table metadata
● Avro: JSON/DSL definition
○ Definition is bundled with avro data files
● Parquet
● pyschema / dataclass
● Scala case classes
● JSON-schema
● JSON: Each record
○ One record insufficient to deduce schema
case class User(id: String, name: String, age: Int,
phone: Option[String] = None)
val users = Seq( User("1", "Alice", 32),
User("2", "Bob", 43, Some("08-123456")))](https://image.slidesharecdn.com/end-to-endpipelineagility-240611150223-5b254fd4/75/End-to-end-pipeline-agility-Berlin-Buzzwords-2024-37-2048.jpg)
![www.scling.com
Scalameta: schema → syntax tree
39
Defn.Class(
List(Mod.Annot(Init(Type.Name("PrivacyShielded"), , List())), case),
Type.Name("SaleTransaction"),
List(),
Ctor.Primary(
List(),
,
List(
List(
Term.Param(
List(Mod.Annot(Init(Type.Name("PersonalId"), , List()))),
Term.Name("customerClubId"),
Some(Type.Apply(Type.Name("Option"), List(Type.Name("String")))),
None
),
Term.Param(
List(Mod.Annot(Init(Type.Name("PersonalData"), , List()))),
Term.Name("storeId"),
Some(Type.Apply(Type.Name("Option"), List(Type.Name("String")))),
None
),
Term.Param(
List(),
Term.Name("item"),
Some(Type.Apply(Type.Name("Option"), List(Type.Name("String")))),
None
),
Term.Param(List(), Term.Name("timestamp"), Some(Type.Name("String")), None)
)
)
),
Template(List(), List(), Self(, None), List()))
@PrivacyShielded
case class SaleTransaction(
@PersonalId customerClubId: Option[String],
@PersonalData storeId: Option[String],
item: Option[String],
timestamp: String
)](https://image.slidesharecdn.com/end-to-endpipelineagility-240611150223-5b254fd4/75/End-to-end-pipeline-agility-Berlin-Buzzwords-2024-39-2048.jpg)


![www.scling.com
case class User(
age: Int,
@AvroProp ("sqlType", "varchar(1012)")
phone: Option[String] = None)
Python + RDBMS
42
case classes
Avro
definitions
Avro type
annotations
MySQL
schemas
Python
{
"name": "User",
{ "name": "age", "type": "int" }
{ "name": "phone",
"type": [ "null", "string" ],
"sqlType": "varchar(1012)",
}
}
class UserEgressJob(CopyToTable):
columns = [
( "age", "int"),
( "name", "varchar(1012)"),
]
...](https://image.slidesharecdn.com/end-to-endpipelineagility-240611150223-5b254fd4/75/End-to-end-pipeline-agility-Berlin-Buzzwords-2024-42-2048.jpg)



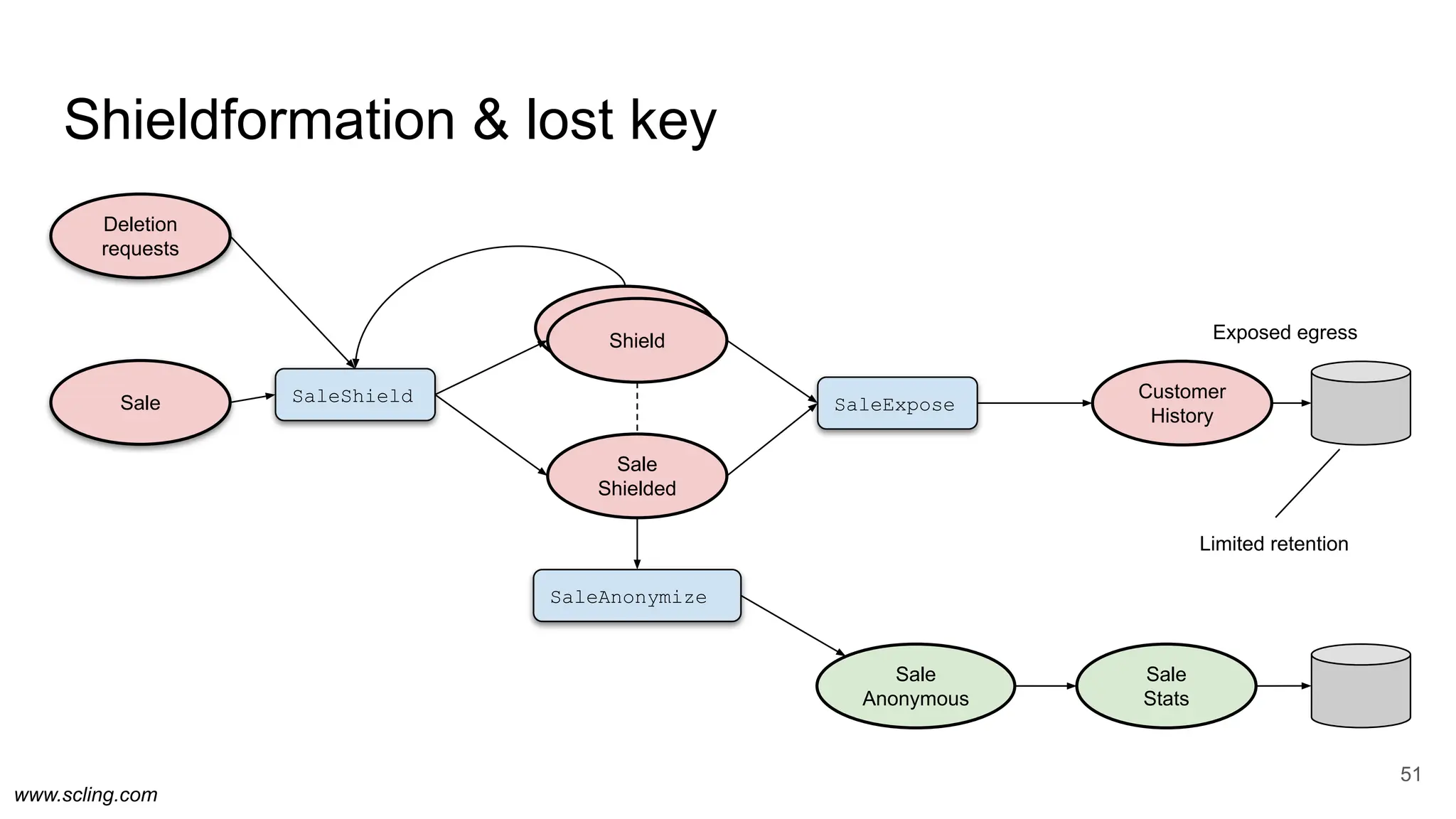
![www.scling.com
Shieldformation
50
@PrivacyShielded
case class Sale(
@PersonalId customerClubId: Option[String],
@PersonalData storeId: Option[String],
item: Option[String],
timestamp: String
)
case class SaleShielded(
shieldId: Option[String],
customerClubIdEncrypted: Option[String],
storeIdEncrypted: Option[String],
item: Option[String],
timestamp: String
)
case class SaleAnonymous(
item: Option[String],
timestamp: String
)
object SaleAnonymize extends SparkJob {
...
}
ShieldForm
object SaleExpose extends SparkJob {
...
}
object SaleShield extends SparkJob {
...
}
case class Shield(
shieldId: String,
personId: Option[String],
keyStr: Option[String],
encounterDate: String
)](https://image.slidesharecdn.com/end-to-endpipelineagility-240611150223-5b254fd4/75/End-to-end-pipeline-agility-Berlin-Buzzwords-2024-50-2048.jpg)



The document discusses the evolution and efficiency of data processing pipelines, highlighting the disparity in capabilities among organizations and the impact of data agility on innovation. It emphasizes the importance of data quality, pipeline management, testing strategies, and the integration of machine learning for business value. Additionally, it covers various frameworks and methodologies for deploying and managing data workflows effectively.

















































![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
