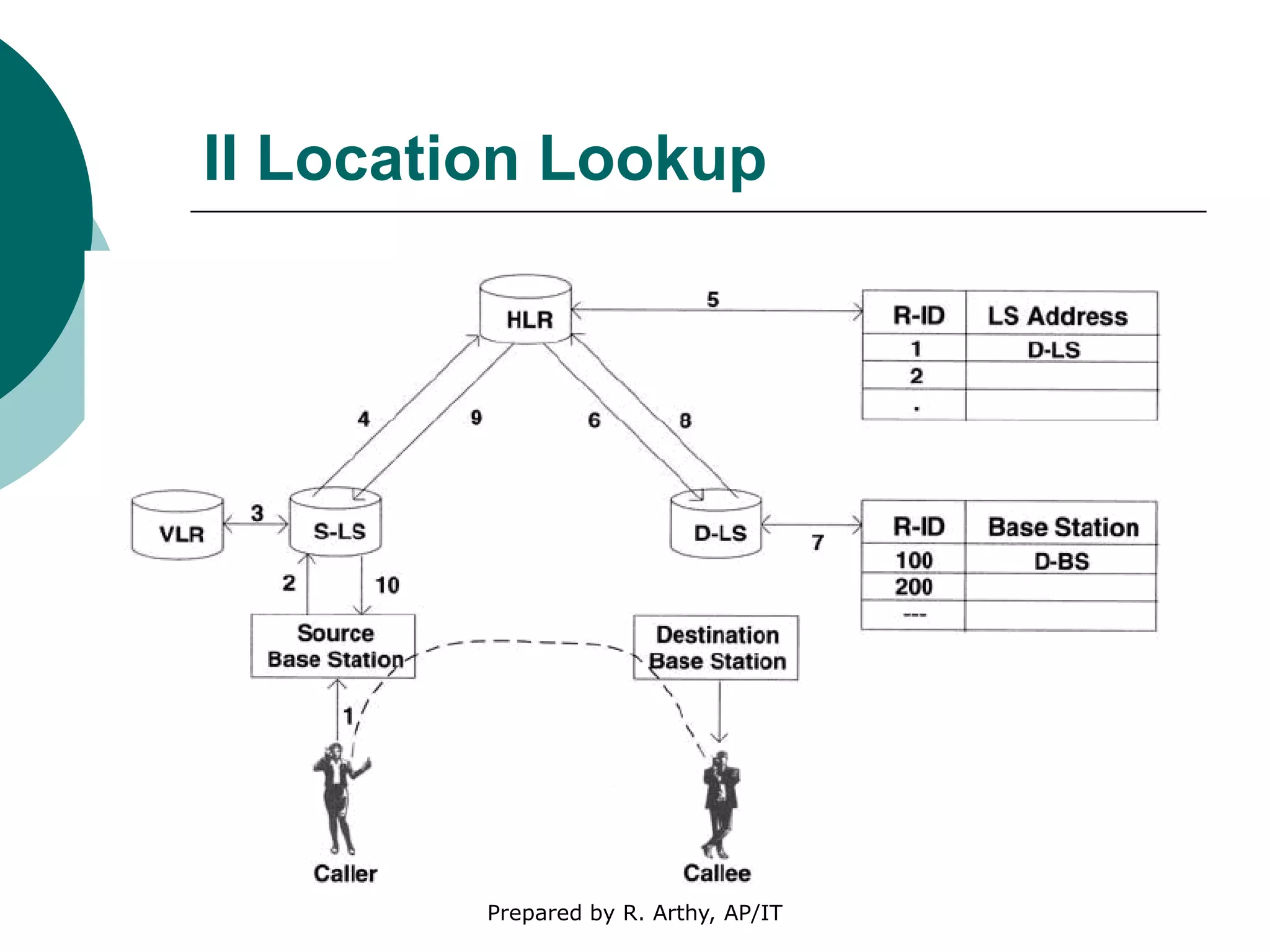
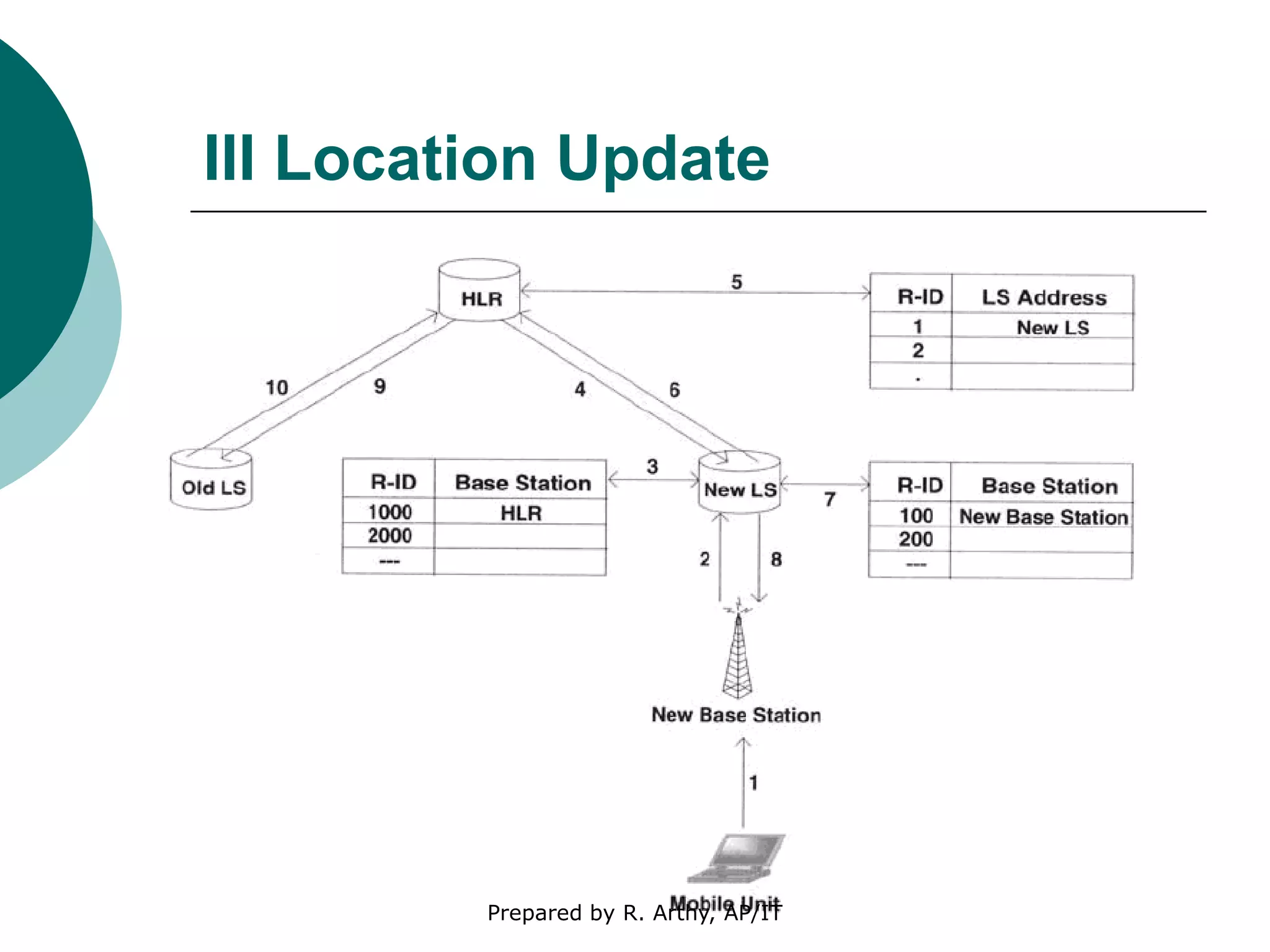
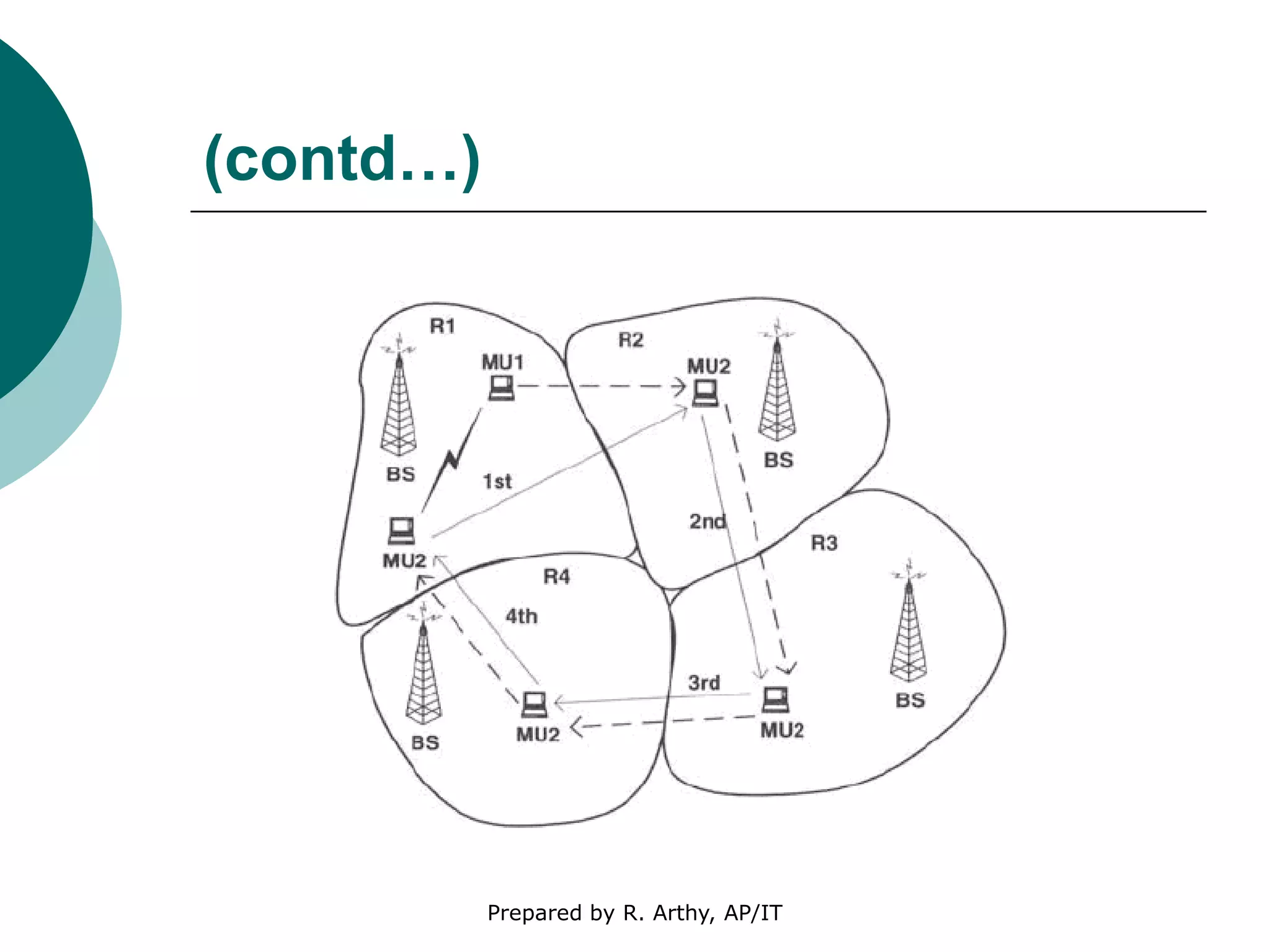
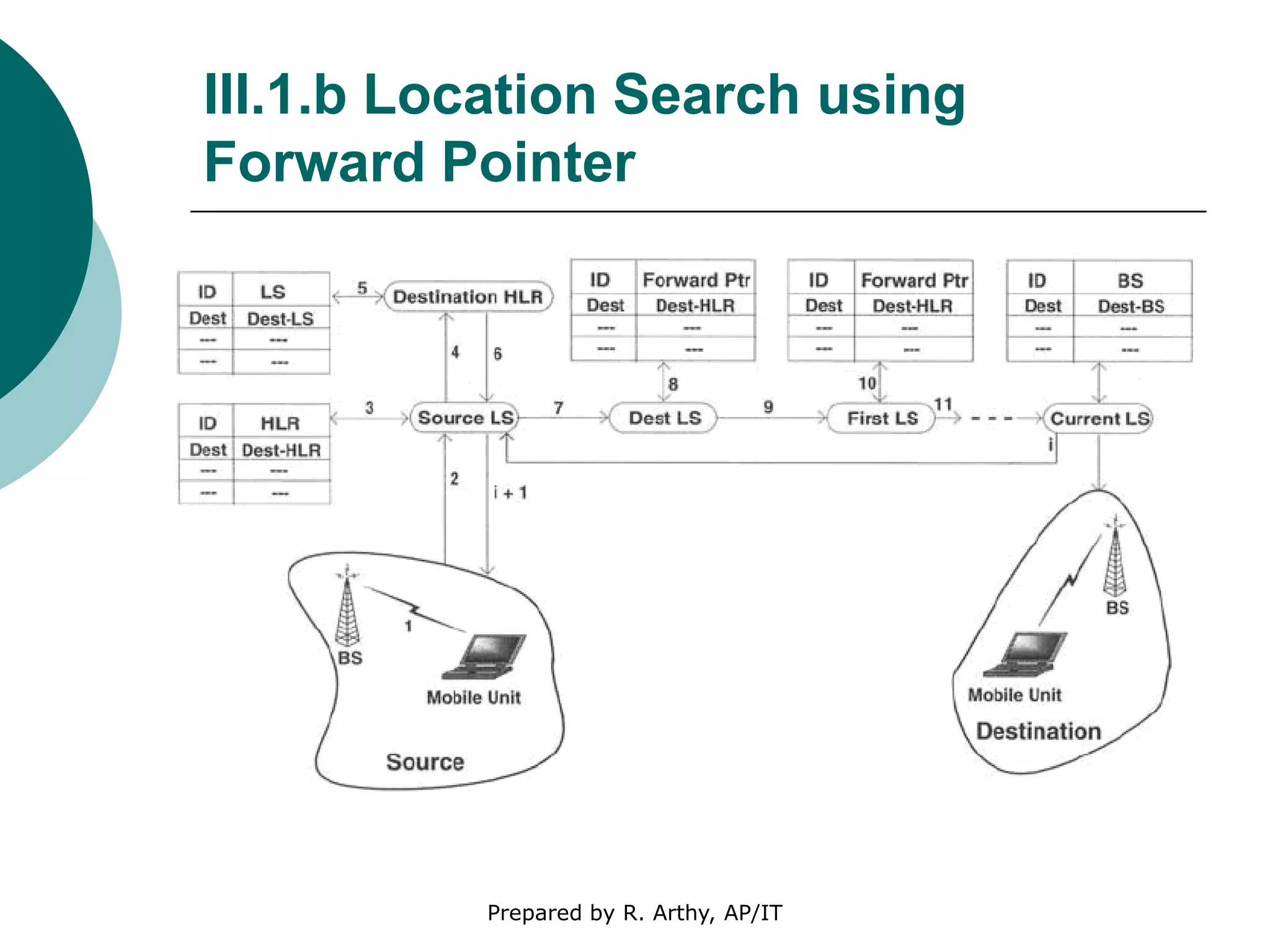
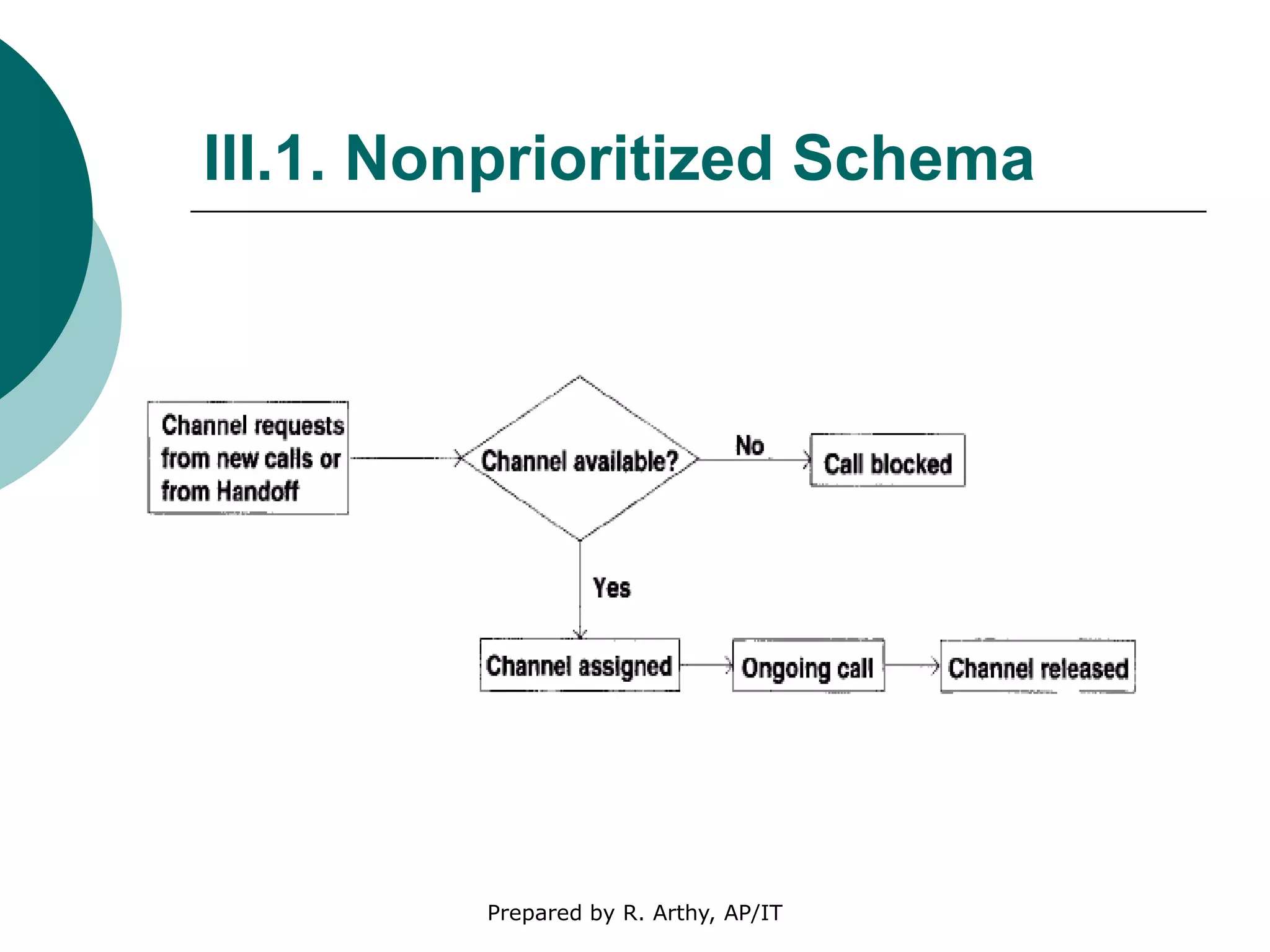
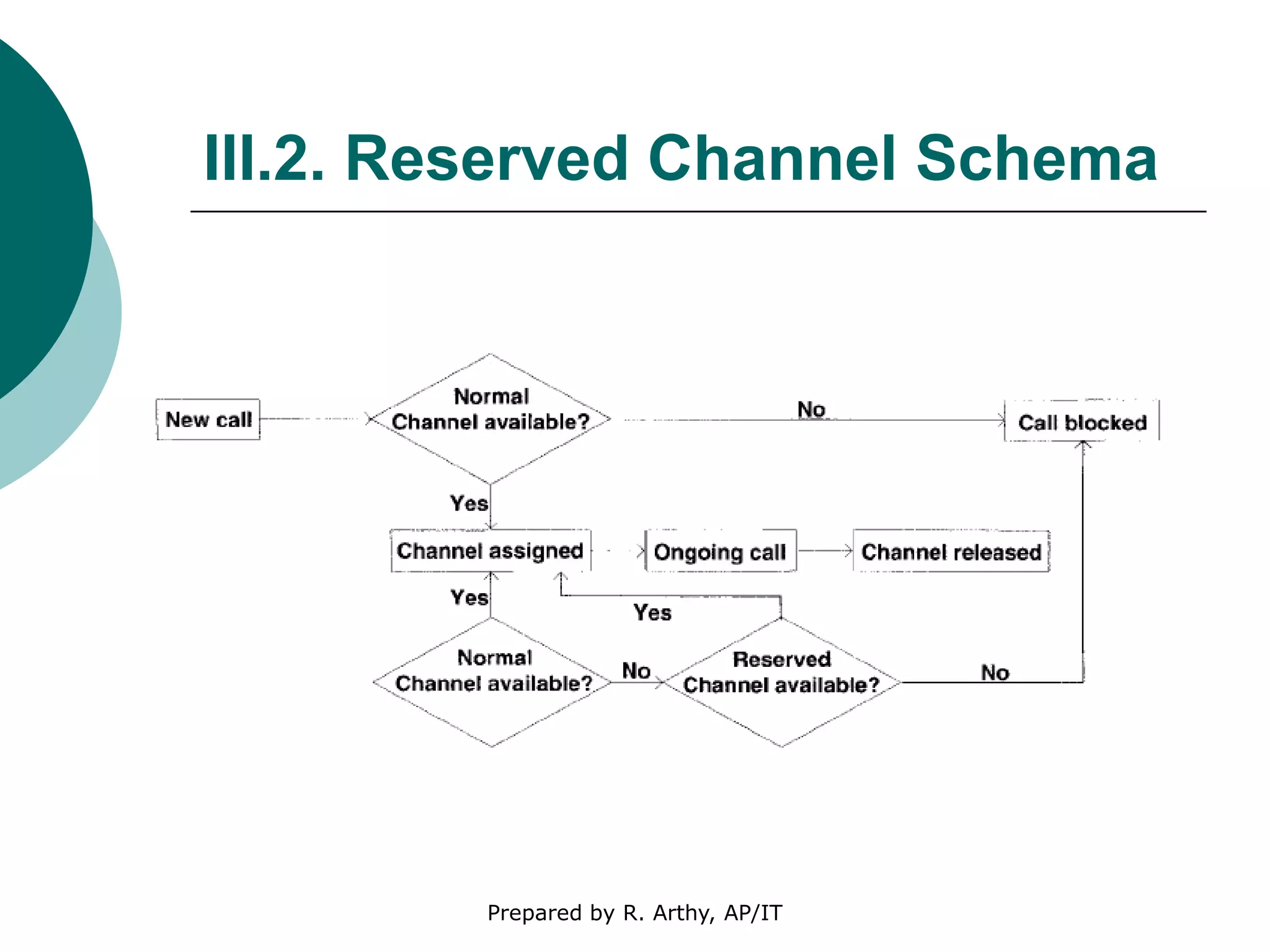
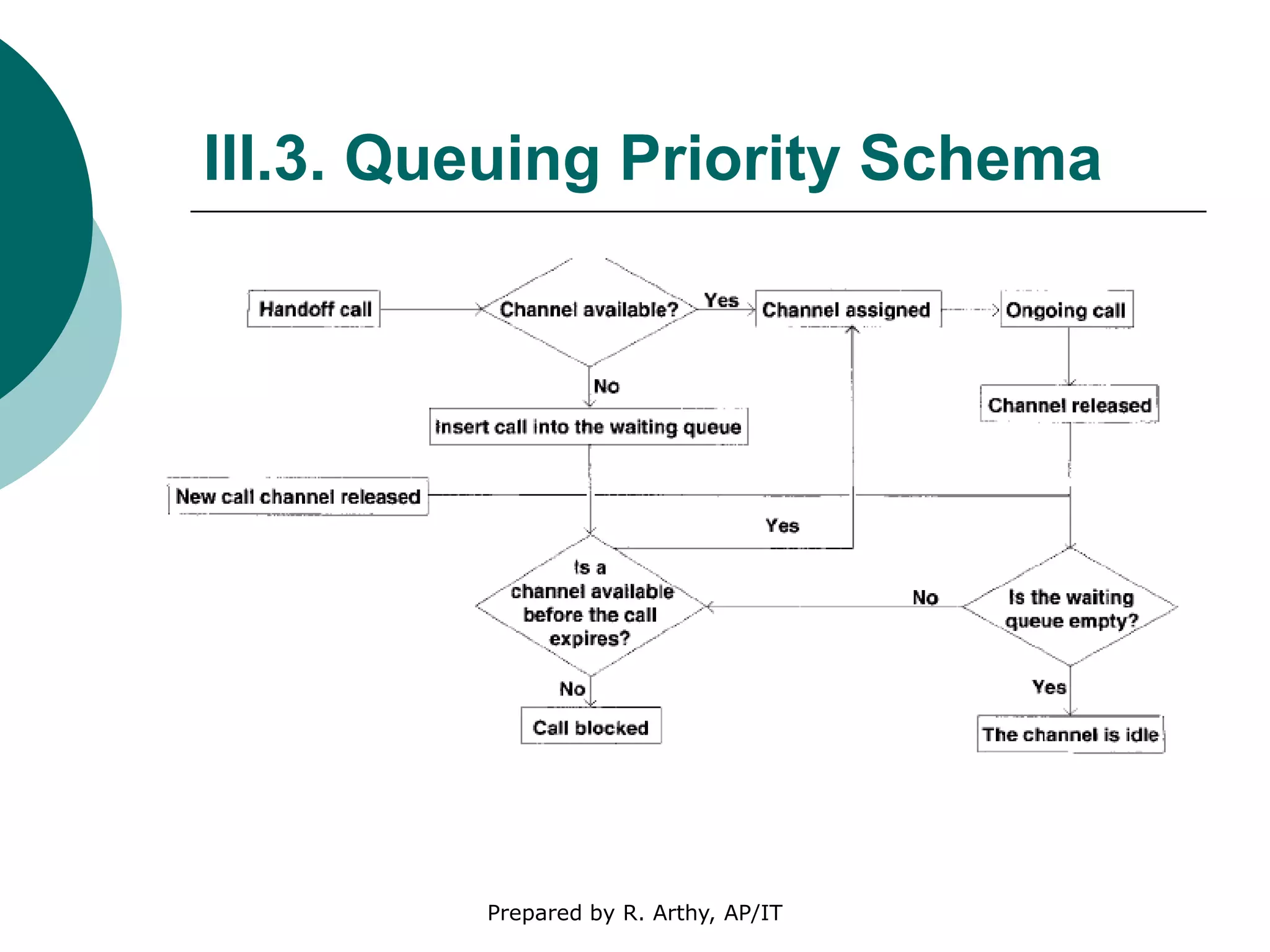
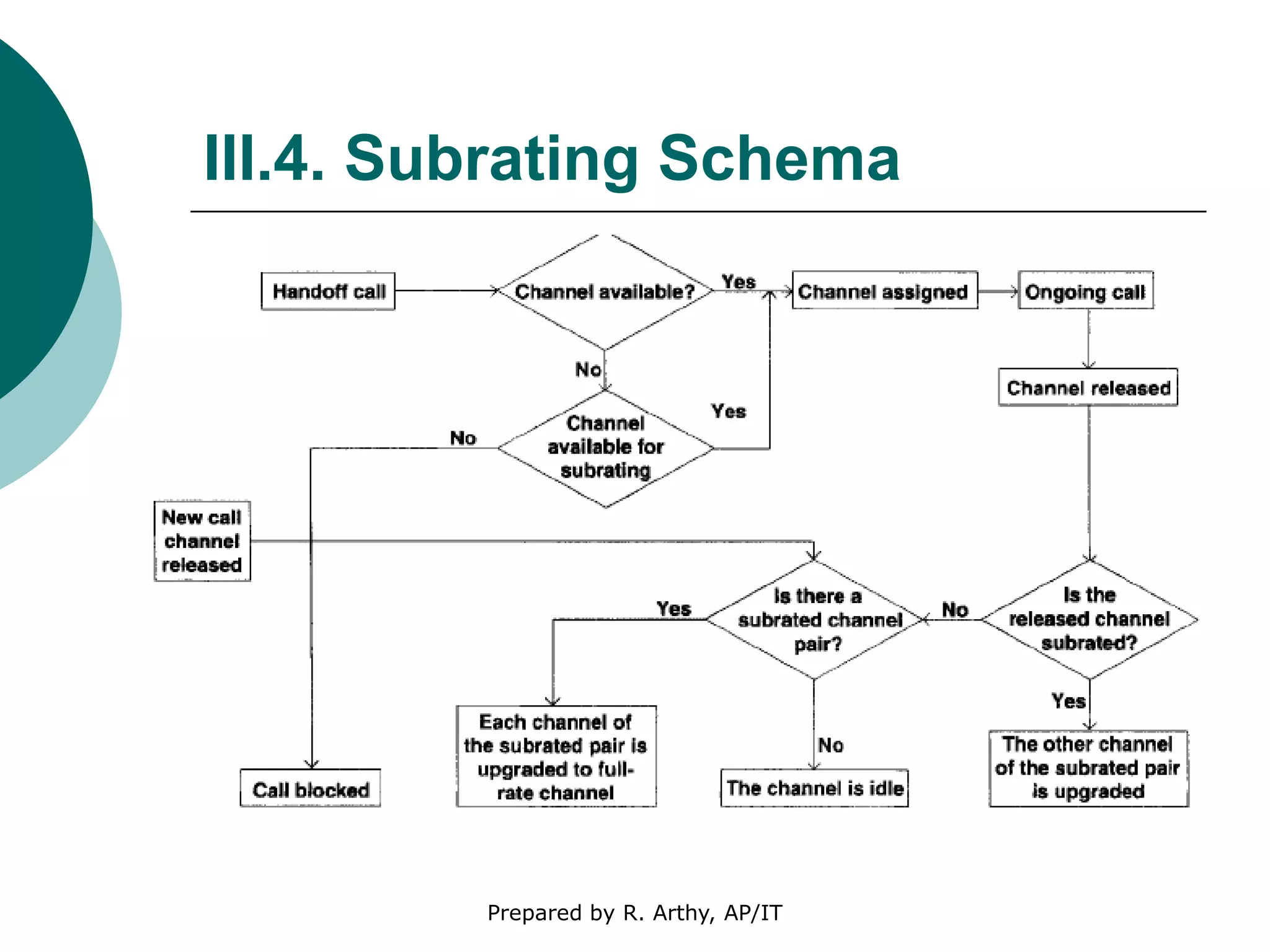
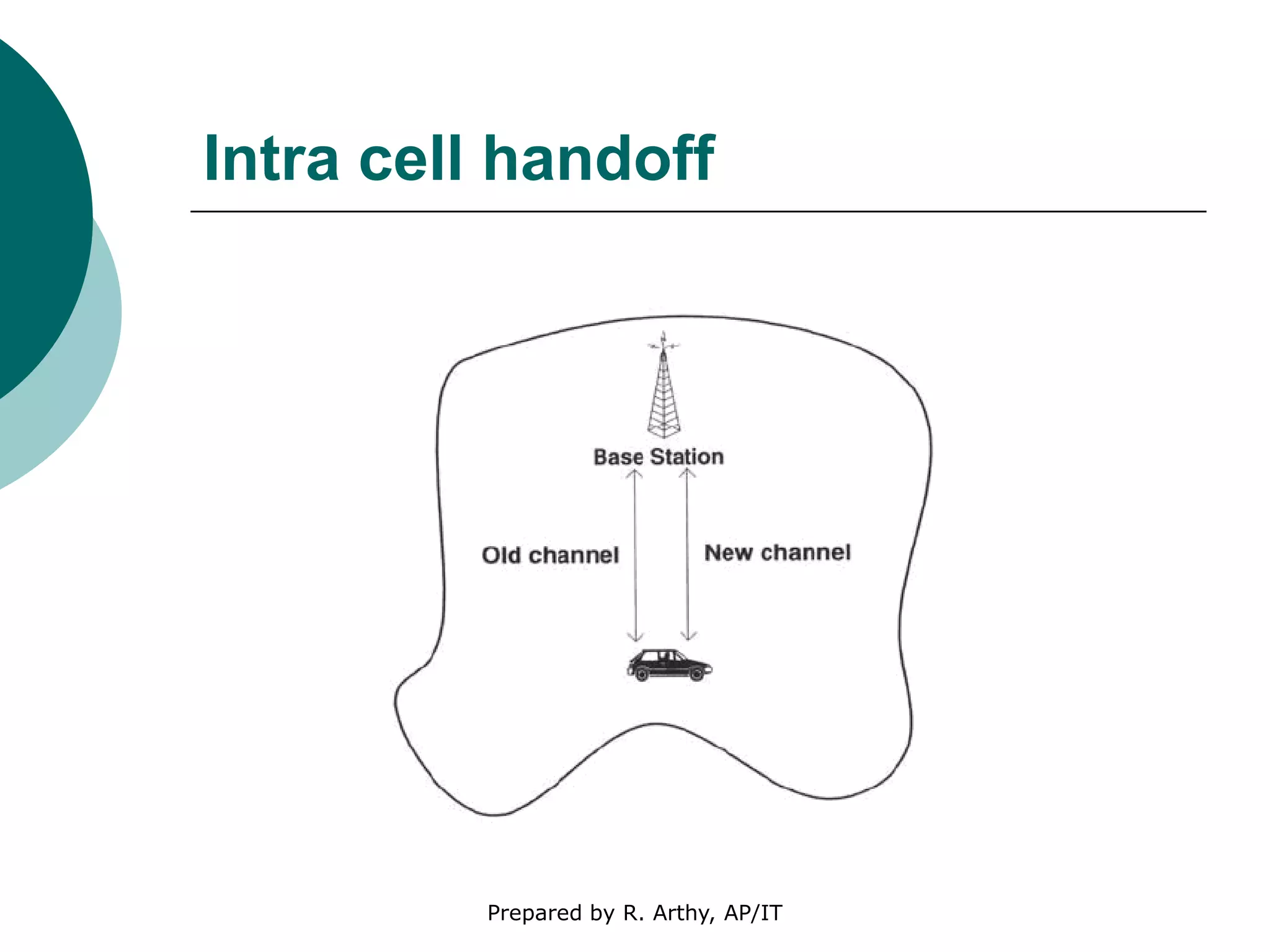
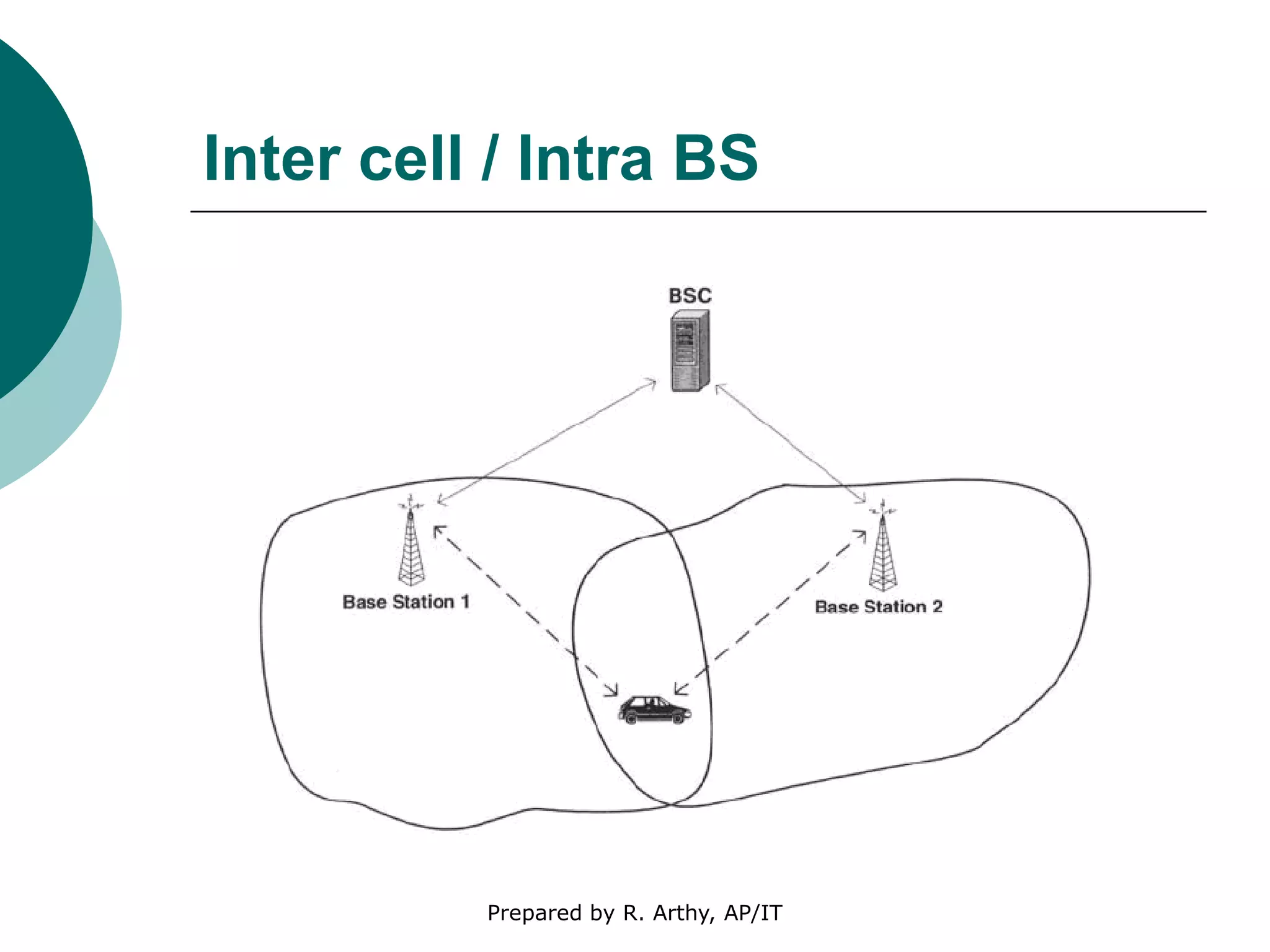
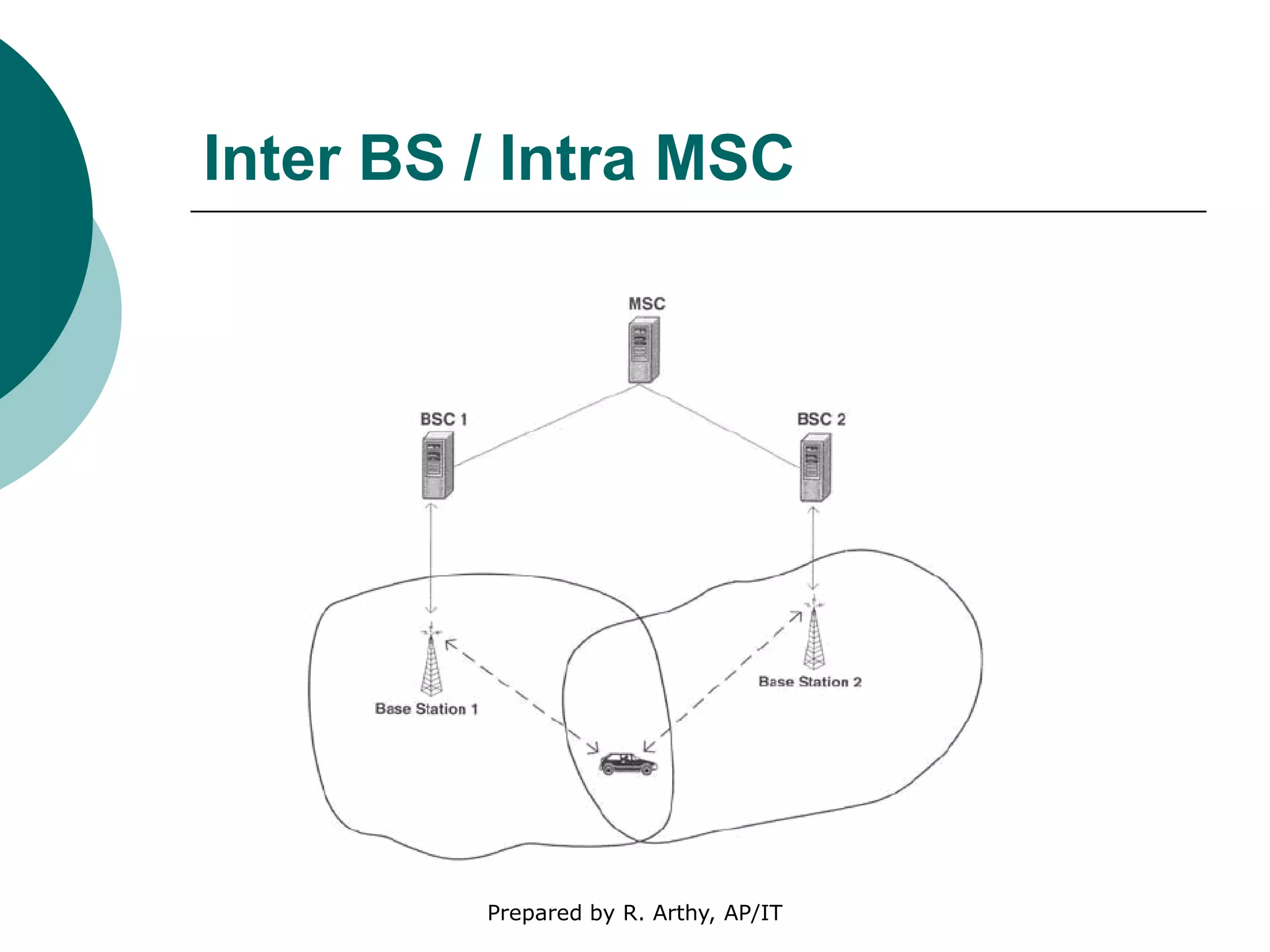
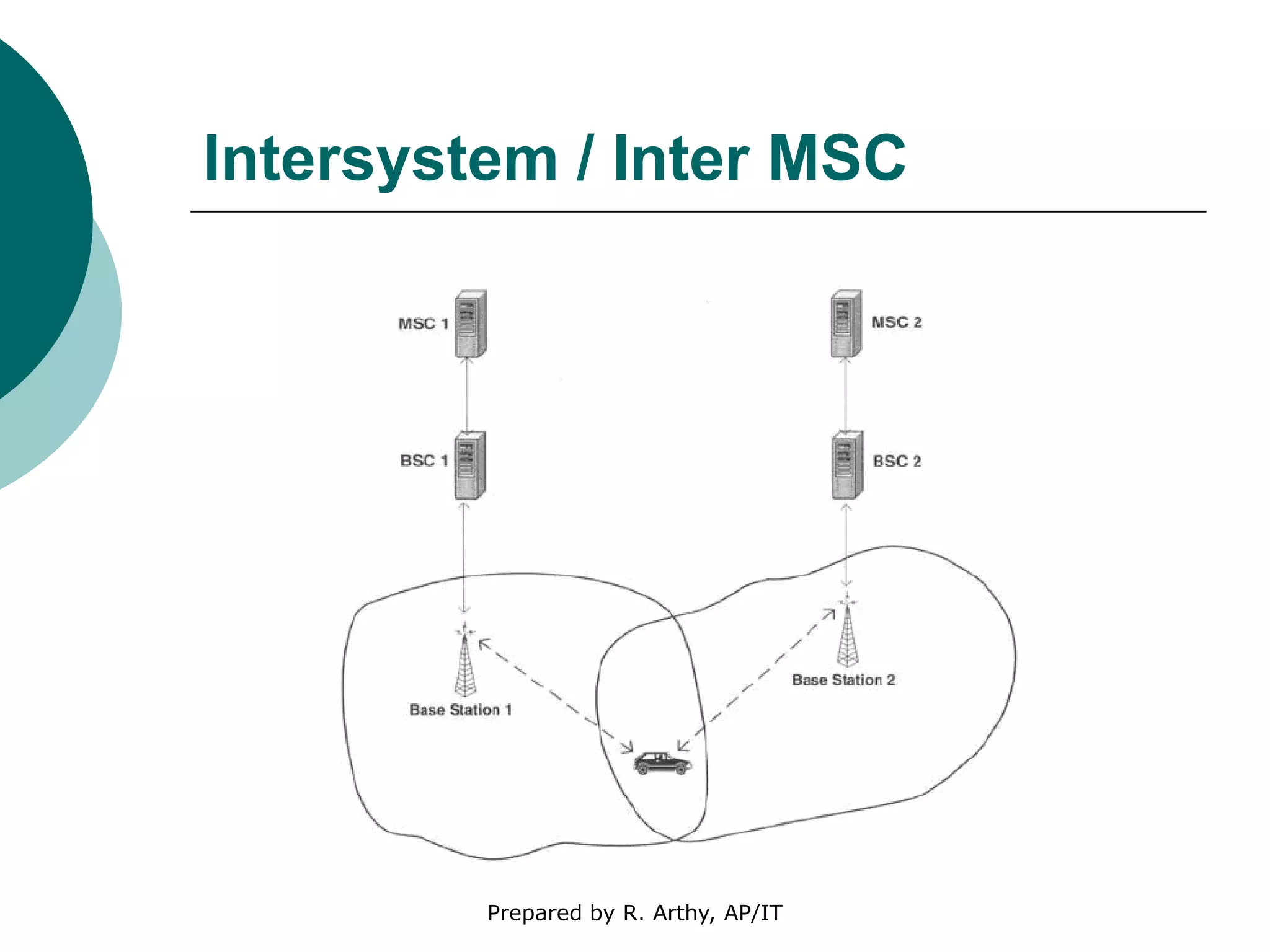
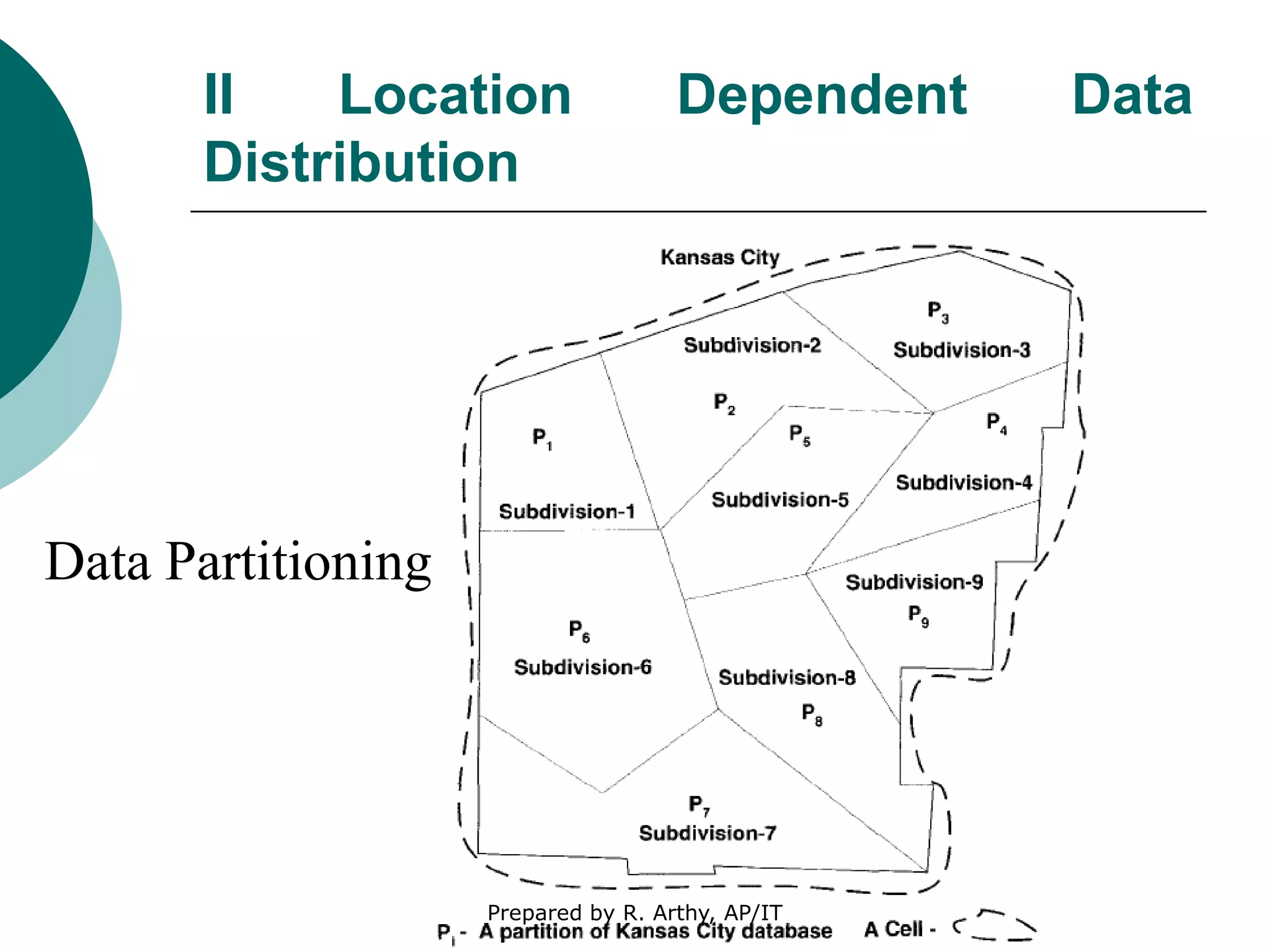
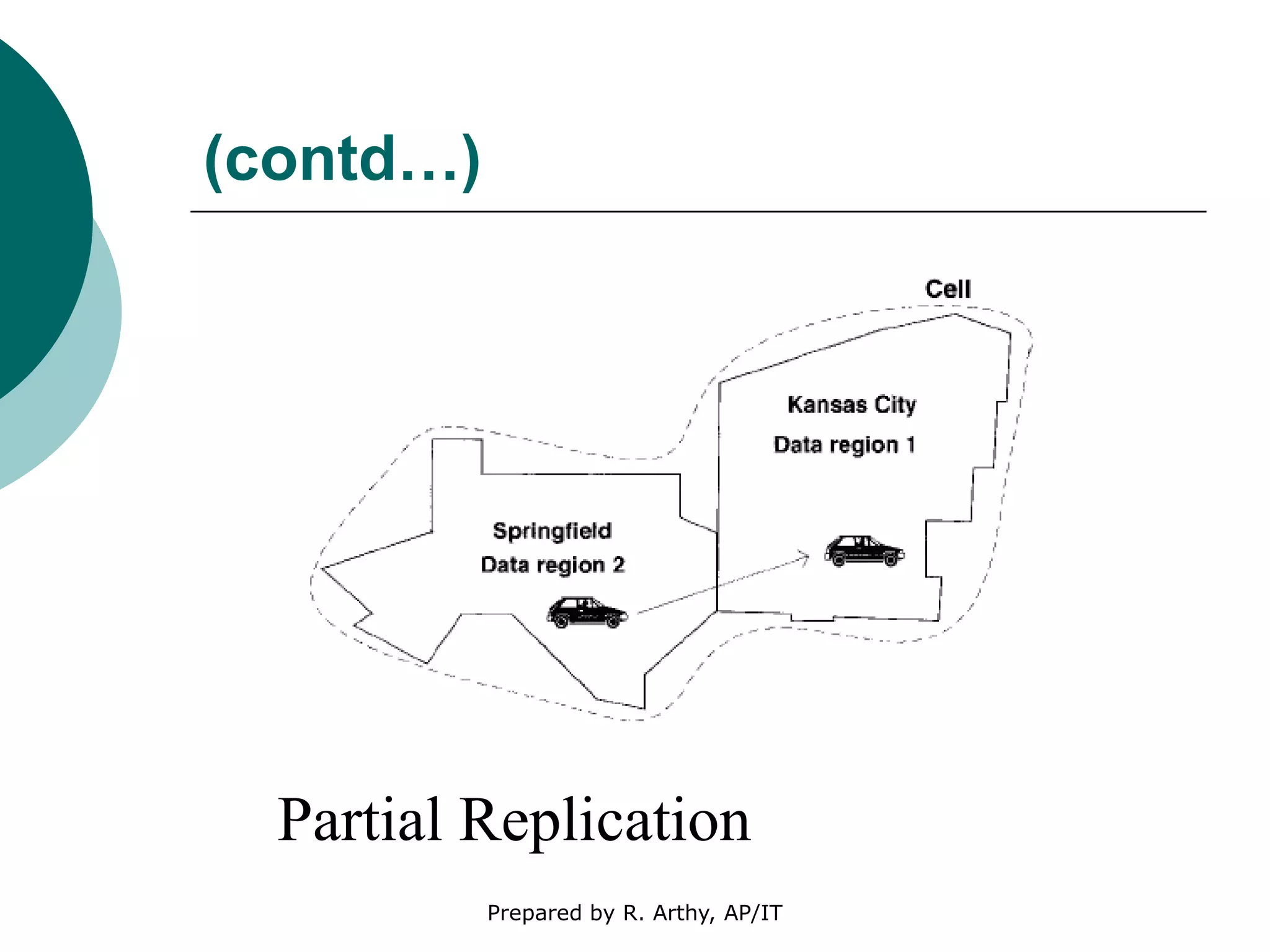
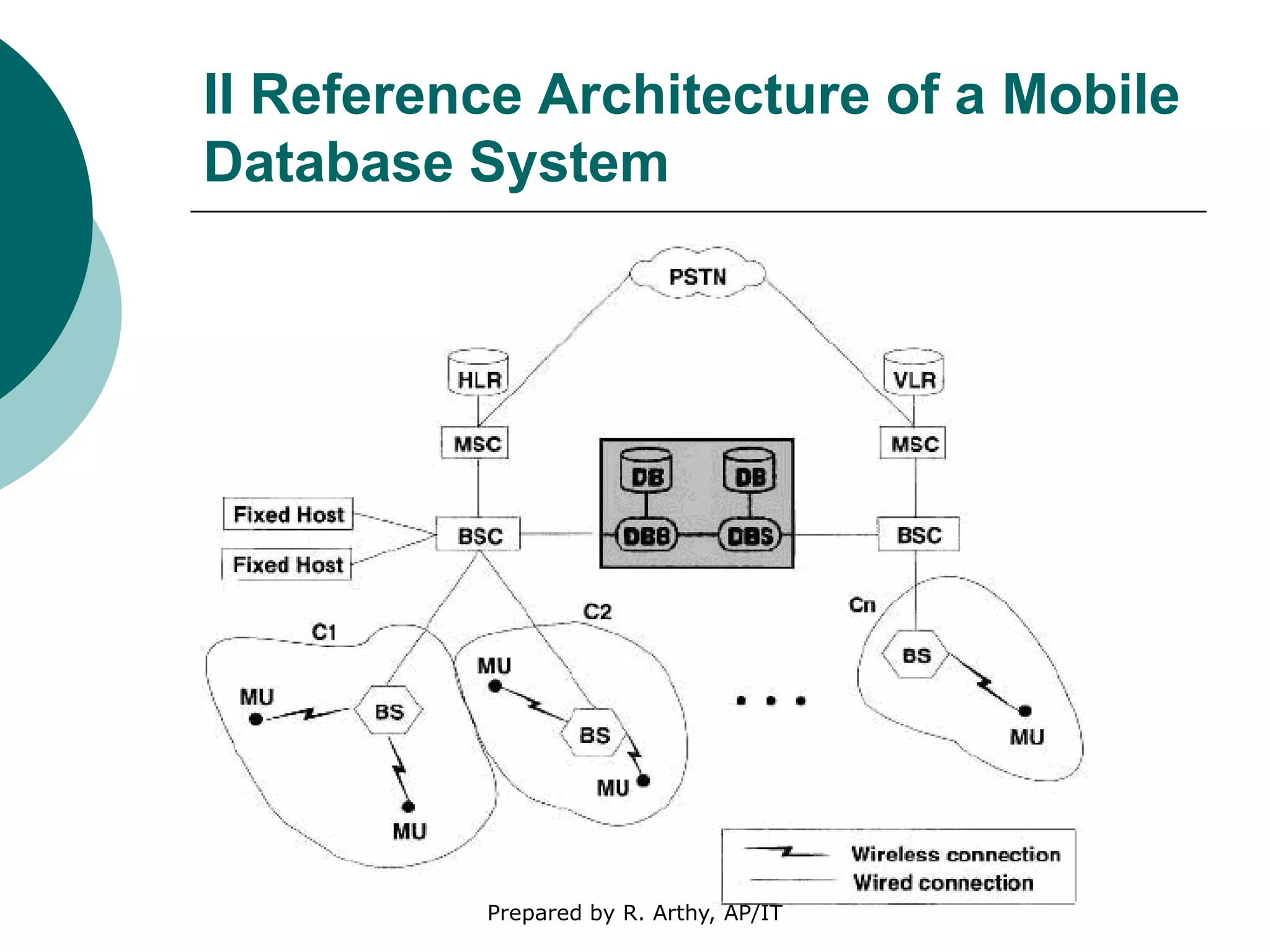
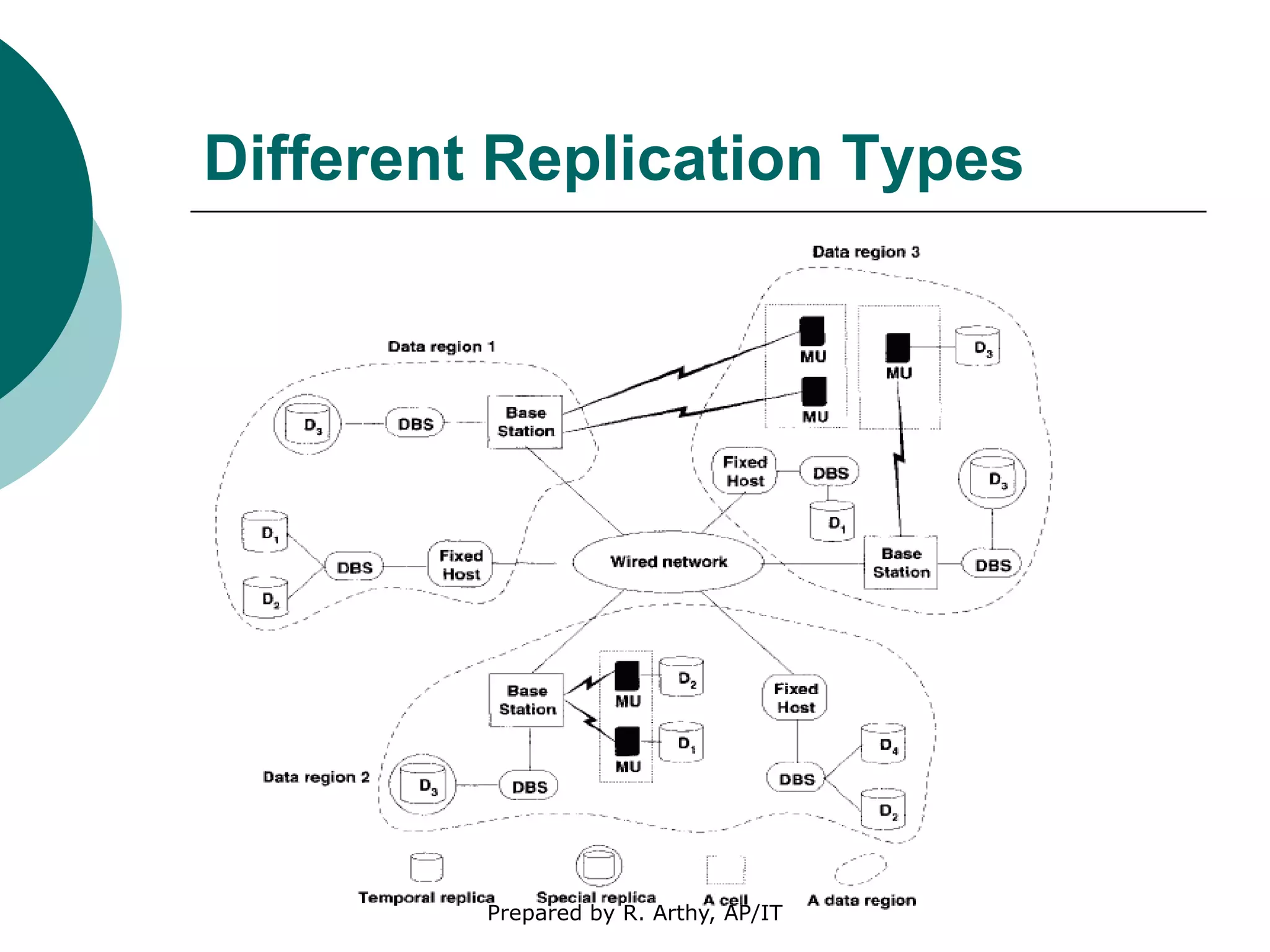
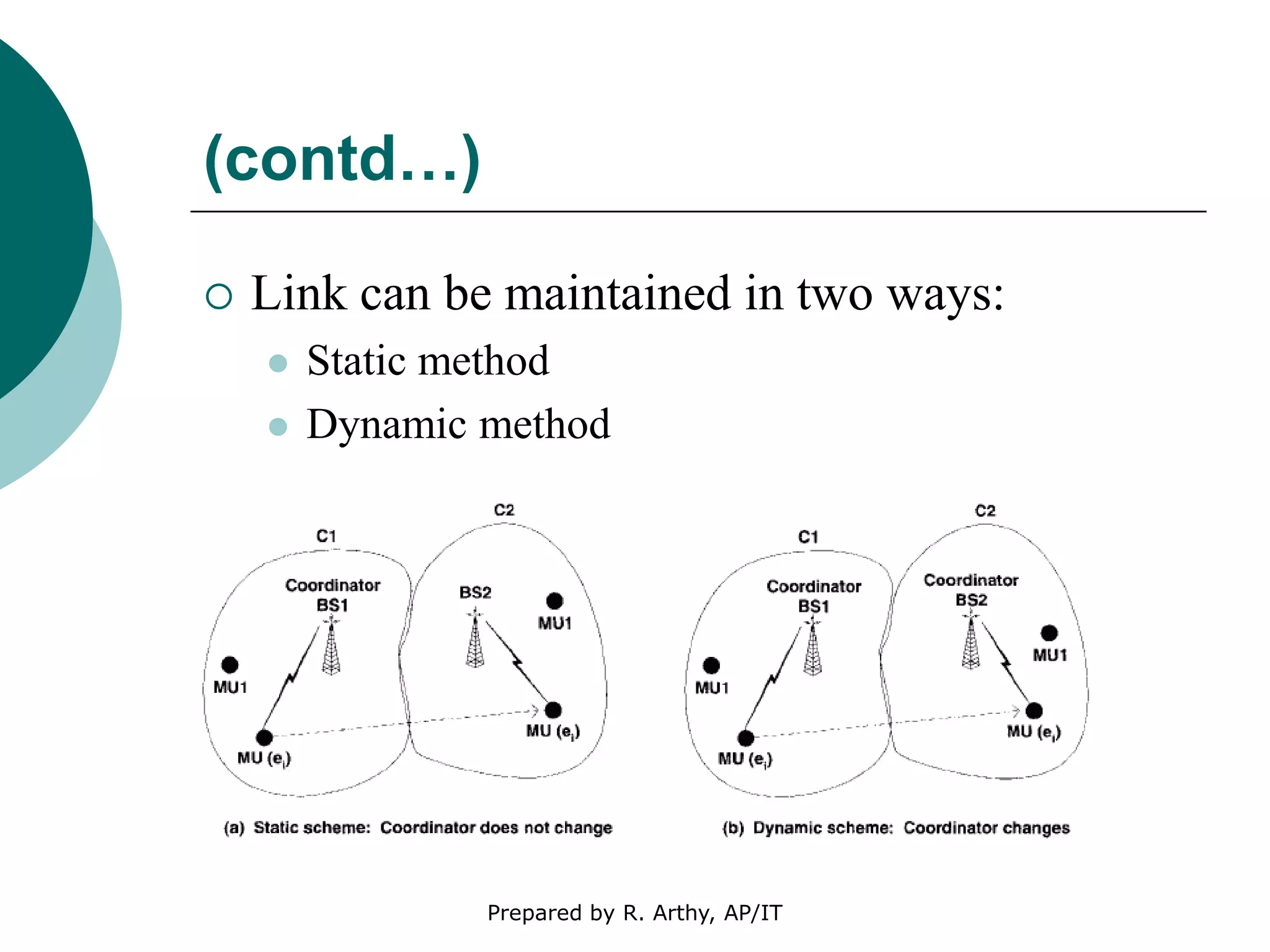
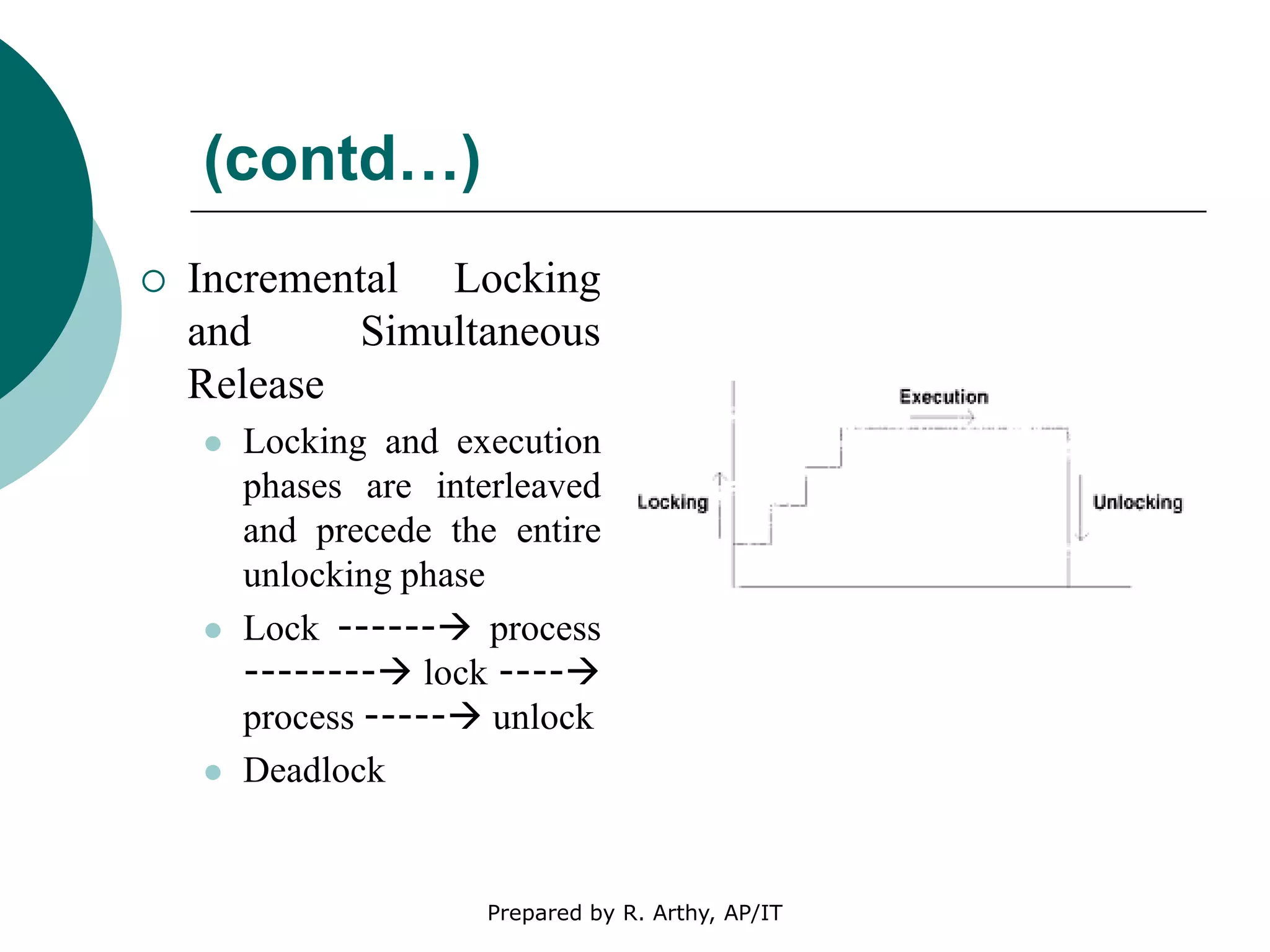
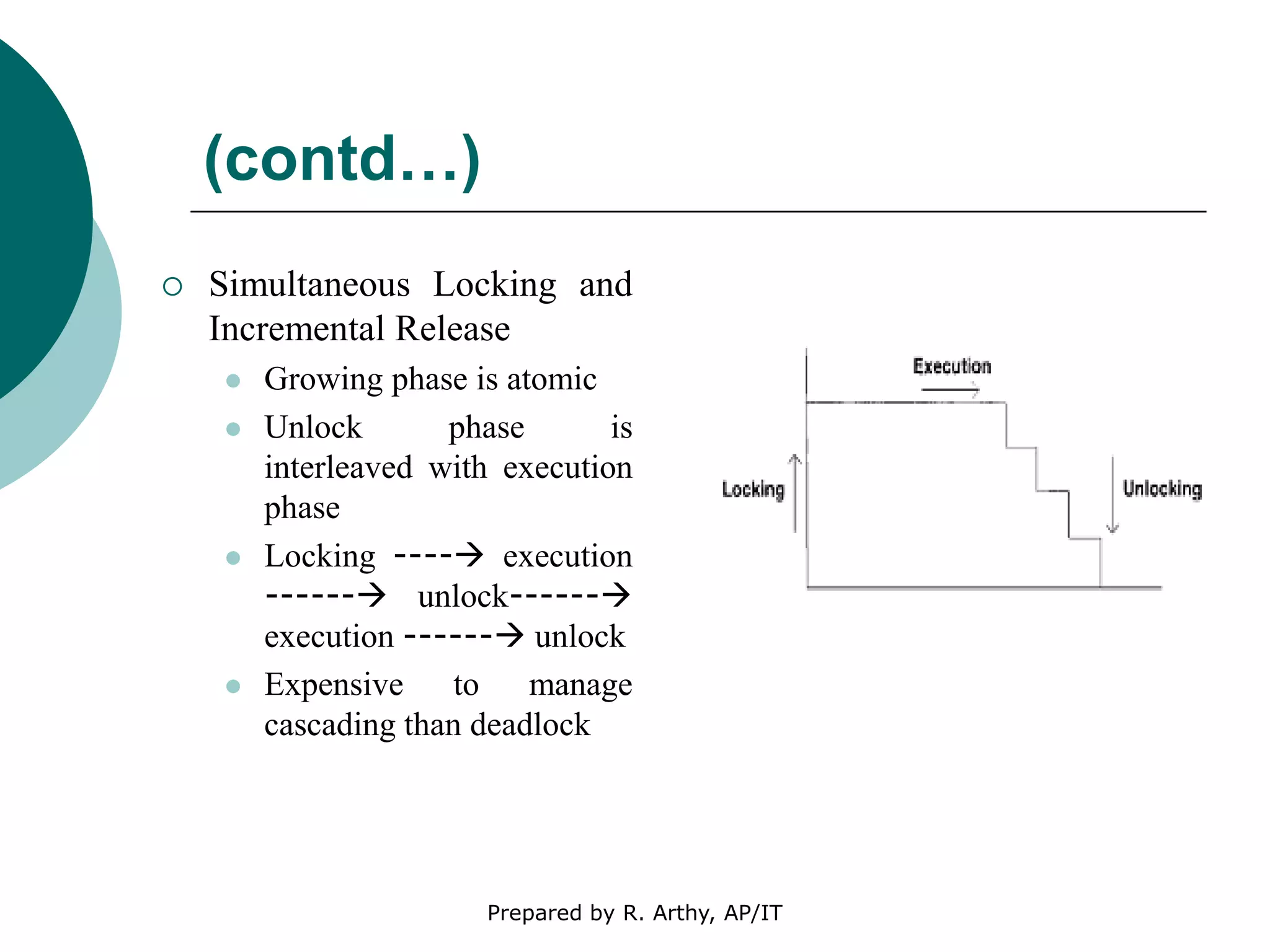
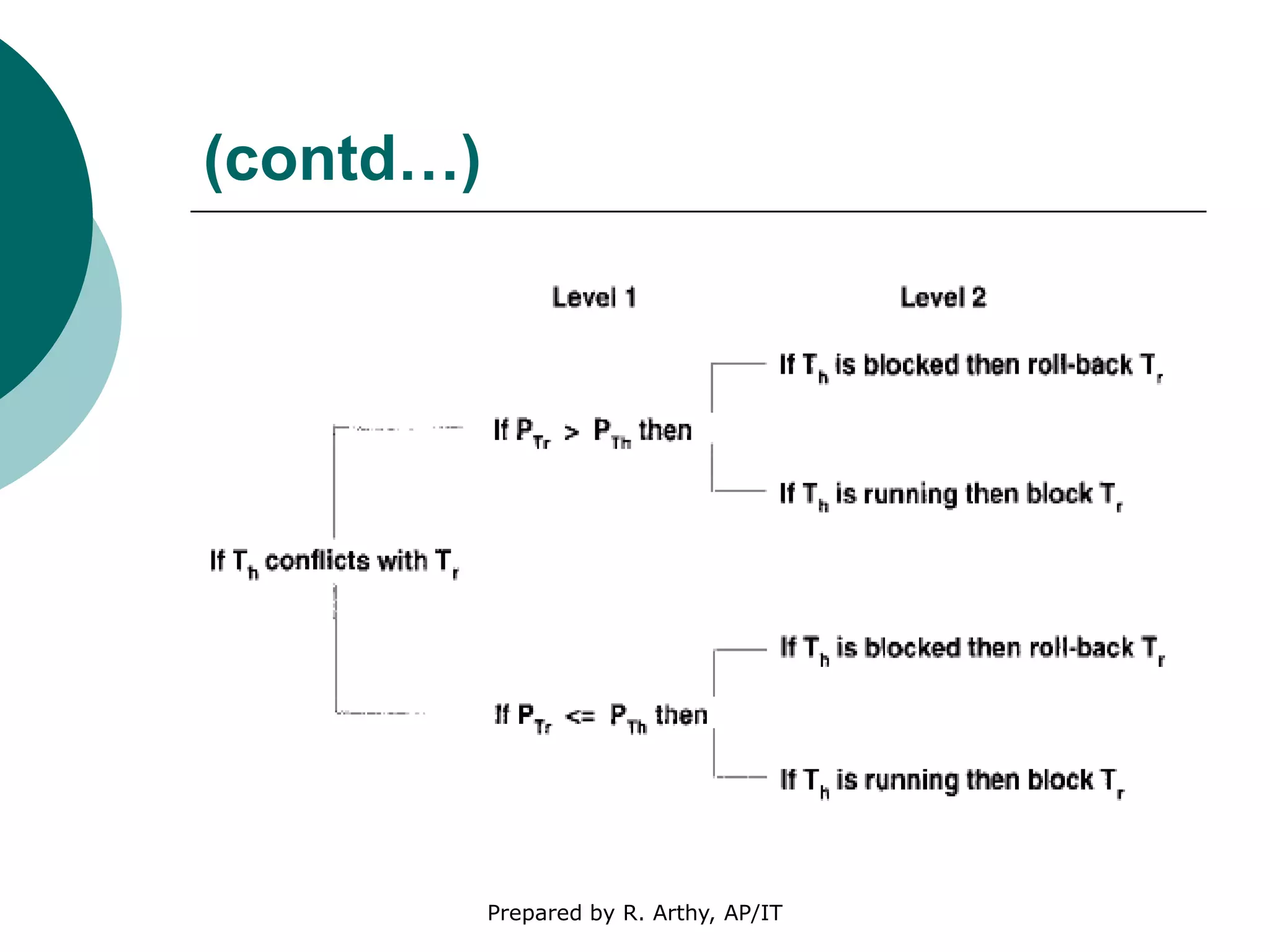
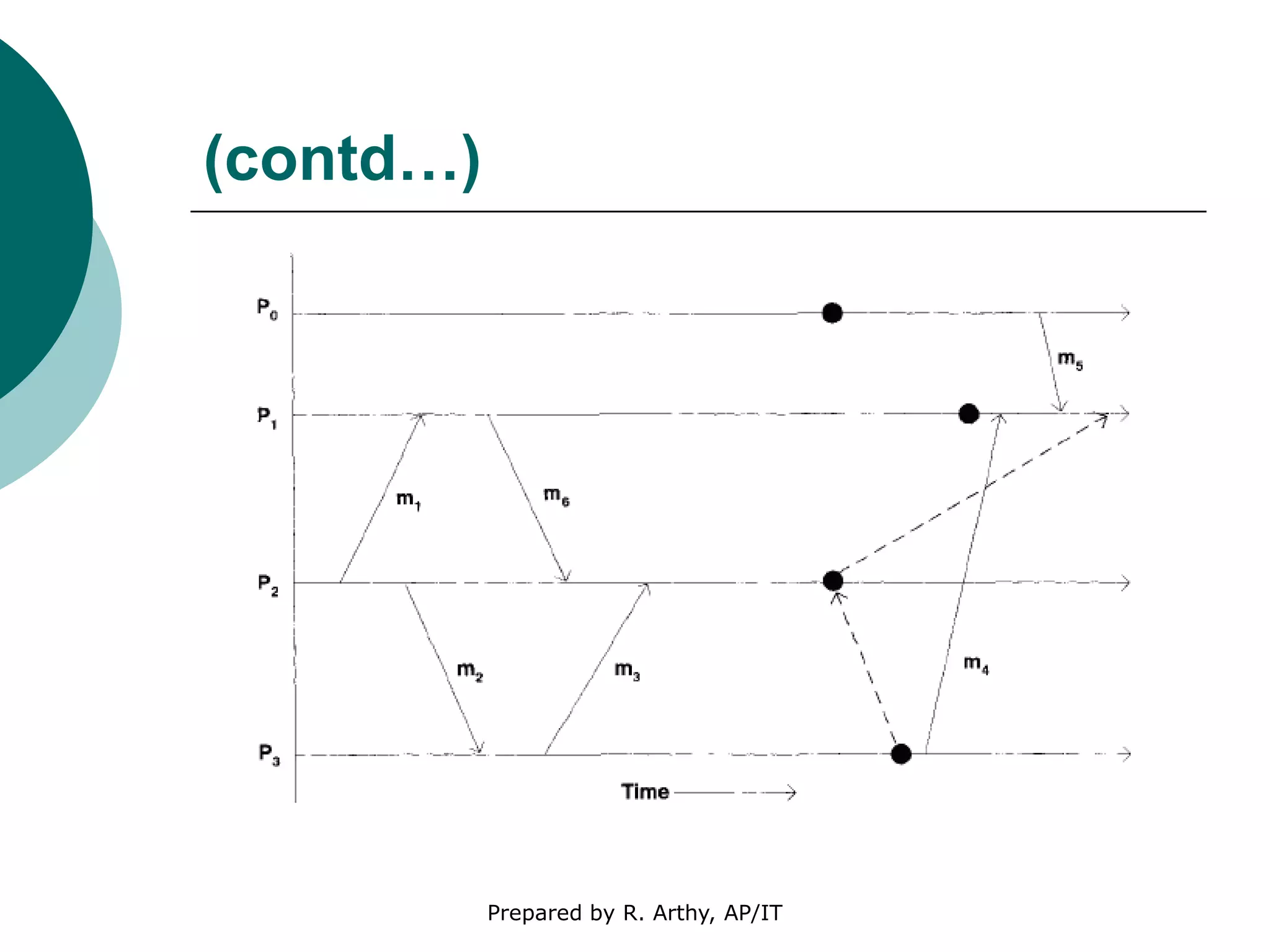
This document discusses location management and handoff management in mobile databases. It covers topics like location lookup, location update, location area, paging area, types of handoff (hard, soft), and challenges of mobility like ensuring atomicity, consistency, isolation and durability of transactions. It also summarizes different mobile transaction models like HiCoMo, Moflex, Kangaroo and Mobilaction that aim to process transactions reliably in a mobile environment with intermittent connectivity.























































































































![Competitive Learning [Deep Learning And Nueral Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/competitivelearning-240211053020-bc9a8437-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































