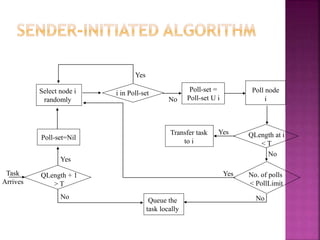
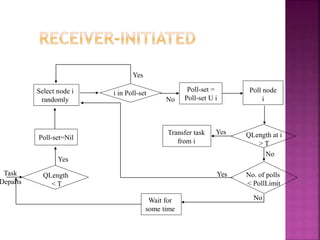
The document discusses various load distribution strategies in computing systems, highlighting the concepts of load balancing, load sharing, and task transfers. It outlines policies for task transfer selection, location, and information collection that help manage system load effectively while avoiding instability. The differences between static, dynamic, and adaptive algorithms are explained, alongside their implications for performance, response times, and system stability.