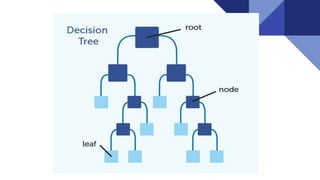
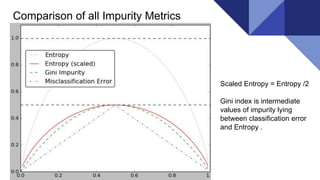
This document provides an overview of decision trees and the CART (Classification and Regression Trees) algorithm, explaining their components such as root nodes, nodes, and leaves, as well as impurity measures like Gini index and entropy. It discusses the advantages and disadvantages of decision trees, including their interpretability and the risk of overfitting, while also highlighting their applications in various fields like business management and healthcare. Additionally, it includes references for further reading and resources for coding with decision trees.














































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)













