Downloaded 647 times
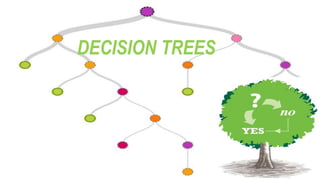
















































Decision trees are a type of supervised learning algorithm used for classification and regression. ID3 and C4.5 are algorithms that generate decision trees by choosing the attribute with the highest information gain at each step. Random forest is an ensemble method that creates multiple decision trees and aggregates their results, improving accuracy. It introduces randomness when building trees to decrease variance.












































































