This document presents a novel clustering algorithm called Kernel Fuzzy C-Means (KFCM), which aims to improve upon existing kernel clustering algorithms by retaining interpretability within the original data space. It compares KFCM's performance to other methods such as k-means and global kernel means, highlighting KFCM's effectiveness in handling incomplete data and optimizing clustering processes. The findings suggest that KFCM outperforms conventional algorithms, providing better clustering results on various datasets.





![International Journal of Information Technology, Control and Automation (IJITCA) Vol.4, No.3, July 2014
6
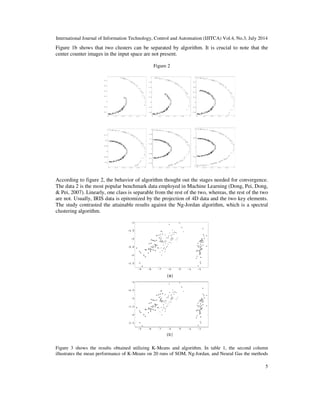
of the study attained with distinct parameter and initialization. The figures displayed show that this
algorithm seemed to function better as compare to the other algorithms.
5. Conclusion
This paper presents a practical approach to the evaluation of clustering algorithms and their
performance on various high-dimensional and sparse data sets; whereas this sets high demands on
the algorithms in terms of computational complexity and assumptions that must be made. The
paper discussed approaches for solving this optimization and multi-stage problem. Distance
matrices and recommender systems have been used to reduce the complexity of the problem and
to calculate missing values. The study focused in the comparison of the different methods in
terms of the similarity of the results, with the aim to find similar behavior. Another focus was on
the flexibility of the algorithms with respect to the records, as well as the sparseness of the data
and the dimensionalities have a major impact on the problem. In conclusion, it has been achieved
with a combination of recommender systems, hierarchical methods, and Affinity Propagation
good results. Kernel-based algorithms were sensitive with respect to changes in the output data
set.
References
[1] Ayvaz, M. T., Karahan, H., & Aral, M. M. (2007). Aquifer parameter and zone structure estimation
using kernel-based fuzzy< i> c</i>-means clustering and genetic algorithm. Journal of Hydrology,
343(3), 240-253.
[2] Dong, G., Pei, J., Dong, G., & Pei, J. (2007), Classification, Clustering, Features and Distances of
Sequence Data. Sequence Data Mining, 47-65.
[3] Filippone, M., Camastra, F., Masulli, F., & Rovetta, S. (2008). A survey of kernel and spectral
methods for clustering. Pattern recognition, 41(1), 176-190.
[4] Graves, D., & Pedrycz, W. (2010). Kernel-based fuzzy clustering and fuzzy clustering: A
comparative experimental study. Fuzzy sets and systems, 161(4), 522-543.
[5] Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters, 31(8),
651-666.
[6] Kulis, B., Basu, S., Dhillon, I., & Mooney, R. (2009). Semi-supervised graph clustering: a kernel
approach. Machine Learning, 74(1), 1-22.
[7] Riesen, K., & Bunke, H. (2010). Graph classification and clustering based on vector space
embedding. World Scientific Publishing Co., Inc.
[8] Tran, T. N., Wehrens, R., & Buydens, L. (2006). KNN-kernel density-based clustering for high-
dimensional multivariate data. Computational Statistics & Data Analysis, 51(2), 513-525.
[9] Wu, X., Kumar, V., Quinlan, J. R., Ghosh, J., Yang, Q., Motoda, H., & Steinberg, D. (2008). Top 10
algorithms in data mining. Knowledge and Information Systems, 14(1), 1-37.
[10] Zhang, H., & Lu, J. (2009). Semi-supervised fuzzy clustering: A kernel-based approach. Knowledge-
based systems, 22(6), 477-481. Data Retrieved from:](https://image.slidesharecdn.com/dataclusteringusingkernelbased-140814004002-phpapp02/85/Data-clustering-using-kernel-based-6-320.jpg)






























































































