Downloaded 16 times


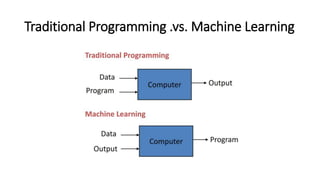


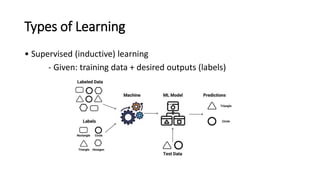
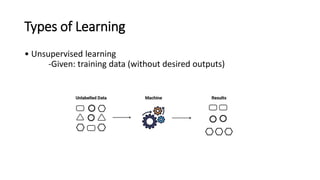
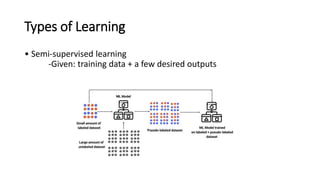
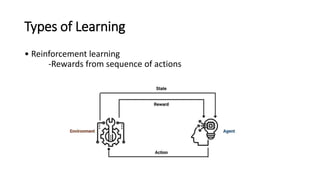



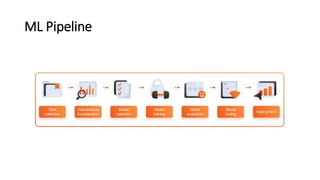
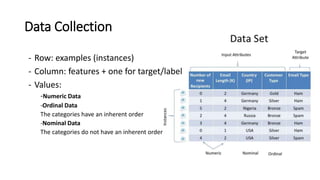
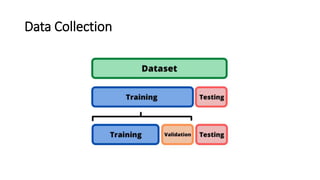












This document provides an overview of machine learning fundamentals and supervised learning with scikit-learn. It defines machine learning and discusses when it is appropriate to use compared to traditional programming. It also describes the different types of learning problems including supervised, unsupervised, semi-supervised and reinforcement learning. For supervised learning, it covers classification and regression problems as well as common applications. It then outlines the typical machine learning pipeline including data collection, preparation, model training, evaluation and addresses issues like overfitting and underfitting.














































































