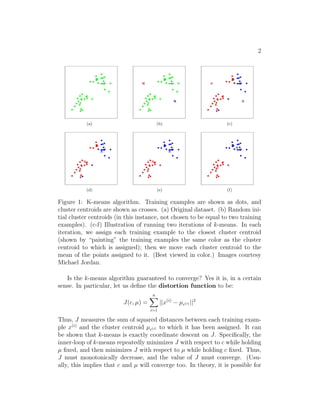
The k-means clustering algorithm aims to group data points into k clusters based on their distances from initial cluster centroid points. It works by alternating between assigning each point to its nearest centroid, and updating the centroid locations to be the mean of their assigned points. This process monotonically decreases the distortion score measuring distances from points to centroids, and is guaranteed to converge, though possibly to local optima rather than the global minimum. Running it multiple times can help avoid bad initial results.