概要
• “Study models though the lens of their training data”
◦ モデルがどうなっているか-> なぜモデルがそうなったのか
◦ 学習サンプルに着目
◦ もしこのサンプルを学習に使わなかったらどうなるのか
• 特定の学習サンプルがモデルパラメータに与える影響を定量的に解析
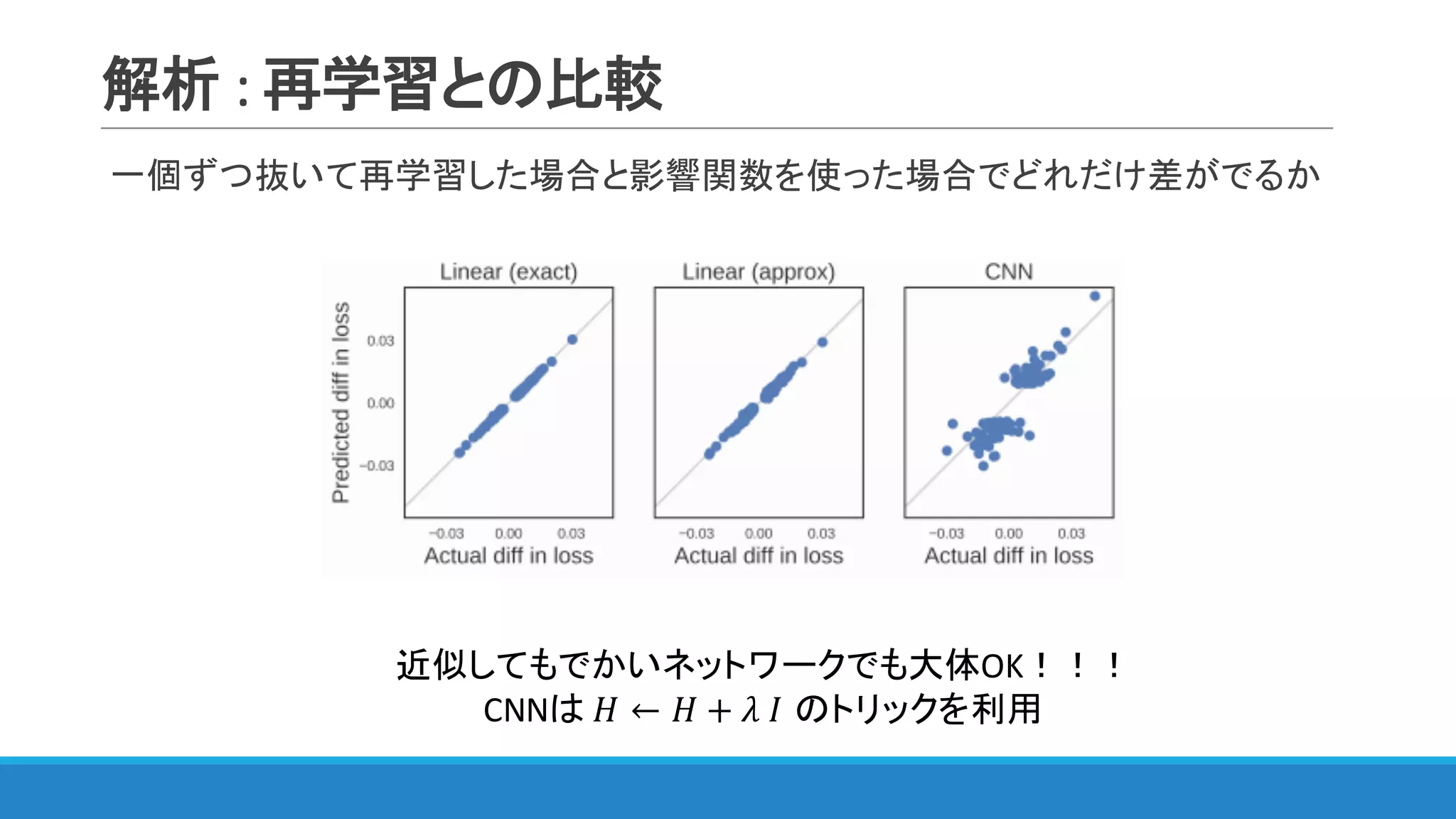
◦ 一つずつ抜いて再学習すればいい話ではあるが時間がかかりすぎる
◦ 統計で古くから利用されていた影響関数(influence function)を利用
◦ Generalized linear modelsではすでに解析例があるが、比較的小さいモデルだった
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Understanding Black-box Predictions
via Influence Functions
Fukuta Keisuke Harada&Ushiku Lab.](https://image.slidesharecdn.com/dlhacksinffunc-170822055634/75/DL-Understanding-Black-box-Predictions-via-Influence-Functions-1-2048.jpg)

![関連研究
• あるdata点周りのみを考慮してよりsimpleなmodelでfittingさせて解析
[Ribeiro, 2016]
• Data点にノイズを加えて予測がどう変化するか
[Simyonyanet al., 2013], [Adler et al., 2016]
これらの研究は与えられたモデルがどう予測を変化させるかを解析したもの
本研究は、”なぜこのモデルに至ったのか”について考察するアプローチ](https://image.slidesharecdn.com/dlhacksinffunc-170822055634/75/DL-Understanding-Black-box-Predictions-via-Influence-Functions-4-2048.jpg)














![影響関数の効率的な計算
𝐼IJ,WXNN 𝑧, 𝑧YZNY = −𝛻< 𝐿 𝑧YZNY, 𝜃= [
𝐻<S
@"
𝛻< 𝐿 𝑧, 𝜃=
Idea
• 𝑠YZNY ≡ 𝐻<S
@"
𝛻< 𝐿 𝑧YZNY, 𝜃4
[
を予め計算しておけば全訓練データに対する計算は楽になる
(二次形式は順番変えて大丈夫)
• 正定値行列𝐴の逆行列とあるベクトルの積 𝐴@" 𝑣は、 𝐴𝑣が計算可能ならば共役勾配法によって
𝐴@"を陽に計算することなく計算可能
• また、ヘッシアンとベクトルの積は、HVP (Hessian Vector Product)と呼ばれ𝑂(𝑝)でヘッシアンを陽
に計算することなく計算可能 (CG法)
• 共役勾配法は毎回全サンプルを利用してH𝑣を計算する必要があって若干遅いので、
[Agarwal et al]らの近似手法でも𝑠YZNYを計算してみた。CG法よりも高速に動いた。](https://image.slidesharecdn.com/dlhacksinffunc-170822055634/75/DL-Understanding-Black-box-Predictions-via-Influence-Functions-20-2048.jpg)













![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Conditional Neural Processes](https://cdn.slidesharecdn.com/ss_thumbnails/conditionalneuralprocesses-180727001730-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Opening the Black Box of Deep Neural Networks via Information](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks10161-171027055615-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Direct Reinforcement Learning for Financial Signal Representation...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks171113miyazaki-171114063842-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)



















