Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Naoki Watanabe
PPTX, PDF
543 views
Deep learning basics described
Introducing basic of deep neural network and convolution layer.
Engineering
◦
Related topics:
Neural Networks
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 100
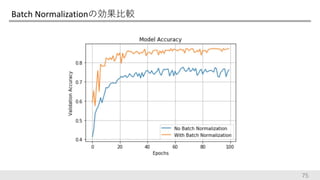
2
/ 100
3
/ 100
4
/ 100
5
/ 100
6
/ 100
7
/ 100
8
/ 100
9
/ 100
10
/ 100
11
/ 100
12
/ 100
13
/ 100
14
/ 100
15
/ 100
16
/ 100
17
/ 100
18
/ 100
19
/ 100
20
/ 100
21
/ 100
22
/ 100
23
/ 100
24
/ 100
25
/ 100
26
/ 100
27
/ 100
28
/ 100
29
/ 100
30
/ 100
31
/ 100
32
/ 100
33
/ 100
34
/ 100
35
/ 100
36
/ 100
37
/ 100
38
/ 100
39
/ 100
40
/ 100
41
/ 100
42
/ 100
43
/ 100
44
/ 100
45
/ 100
46
/ 100
47
/ 100
48
/ 100
49
/ 100
50
/ 100
51
/ 100
52
/ 100
53
/ 100
54
/ 100
55
/ 100
56
/ 100
57
/ 100
58
/ 100
59
/ 100
60
/ 100
61
/ 100
62
/ 100
63
/ 100
64
/ 100
65
/ 100
66
/ 100
67
/ 100
68
/ 100
69
/ 100
70
/ 100
71
/ 100
72
/ 100
73
/ 100
74
/ 100
75
/ 100
76
/ 100
77
/ 100
78
/ 100
79
/ 100
80
/ 100
81
/ 100
82
/ 100
83
/ 100
84
/ 100
85
/ 100
86
/ 100
87
/ 100
88
/ 100
89
/ 100
90
/ 100
91
/ 100
92
/ 100
93
/ 100
94
/ 100
95
/ 100
96
/ 100
97
/ 100
98
/ 100
99
/ 100
100
/ 100
More Related Content
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
PDF
正則化つき線形モデル(「入門機械学習第6章」より)
by
Eric Sartre
PDF
L0TV: a new method for image restoration in the presence of impulse noise
by
Fujimoto Keisuke
PDF
ディジタル信号処理 課題解説(その3) 2014年度版
by
dsp_kyoto_2014
PDF
卒論プレゼンテーション -DRAFT-
by
Tomoshige Nakamura
PDF
Sparse estimation tutorial 2014
by
Taiji Suzuki
PDF
ディジタル信号処理 課題解説(その1) 2014年度版
by
dsp_kyoto_2014
PDF
双対性
by
Yoichi Iwata
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
正則化つき線形モデル(「入門機械学習第6章」より)
by
Eric Sartre
L0TV: a new method for image restoration in the presence of impulse noise
by
Fujimoto Keisuke
ディジタル信号処理 課題解説(その3) 2014年度版
by
dsp_kyoto_2014
卒論プレゼンテーション -DRAFT-
by
Tomoshige Nakamura
Sparse estimation tutorial 2014
by
Taiji Suzuki
ディジタル信号処理 課題解説(その1) 2014年度版
by
dsp_kyoto_2014
双対性
by
Yoichi Iwata
What's hot
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
ディジタル信号処理の課題解説 その3
by
noname409
PDF
ディジタル信号処理の課題解説
by
noname409
PDF
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PDF
指数時間アルゴリズムの最先端
by
Yoichi Iwata
PDF
様々な全域木問題
by
tmaehara
PDF
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011
by
Preferred Networks
PDF
2014年5月14日_水曜セミナー発表内容_FINAL
by
Tomoshige Nakamura
PPTX
手描き感を再現する ペイントシミュレータの最新研究紹介
by
Silicon Studio Corporation
PDF
Sparse models
by
Daisuke Yoneoka
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PDF
Rで学ぶ回帰分析と単位根検定
by
Nagi Teramo
PPTX
End challenge part2
by
hisa2
PDF
2値分類・多クラス分類
by
t dev
PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
PDF
サンプリング定理
by
Toshihisa Tanaka
PDF
TokyoNLP#7 きれいなジャイアンのカカカカ☆カーネル法入門-C++
by
sleepy_yoshi
PDF
ディジタル信号処理 課題解説 その4
by
noname409
PDF
文字列カーネルによる辞書なしツイート分類 〜文字列カーネル入門〜
by
Takeshi Arabiki
PDF
Rで学ぶ逆変換(逆関数)法
by
Nagi Teramo
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
ディジタル信号処理の課題解説 その3
by
noname409
ディジタル信号処理の課題解説
by
noname409
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
指数時間アルゴリズムの最先端
by
Yoichi Iwata
様々な全域木問題
by
tmaehara
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011
by
Preferred Networks
2014年5月14日_水曜セミナー発表内容_FINAL
by
Tomoshige Nakamura
手描き感を再現する ペイントシミュレータの最新研究紹介
by
Silicon Studio Corporation
Sparse models
by
Daisuke Yoneoka
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
Rで学ぶ回帰分析と単位根検定
by
Nagi Teramo
End challenge part2
by
hisa2
2値分類・多クラス分類
by
t dev
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
サンプリング定理
by
Toshihisa Tanaka
TokyoNLP#7 きれいなジャイアンのカカカカ☆カーネル法入門-C++
by
sleepy_yoshi
ディジタル信号処理 課題解説 その4
by
noname409
文字列カーネルによる辞書なしツイート分類 〜文字列カーネル入門〜
by
Takeshi Arabiki
Rで学ぶ逆変換(逆関数)法
by
Nagi Teramo
Similar to Deep learning basics described
PDF
ディープラーニングのすごさを共有したい.pdf
by
Yusuke Hayashi
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PDF
Report2
by
YoshikazuHayashi3
PDF
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
PRML_from5.1to5.3.1
by
禎晃 山崎
PDF
社内機械学習勉強会 #5
by
shingo suzuki
PPTX
Deep Learning Chap. 6: Deep Feedforward Networks
by
Shion Honda
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PPTX
深層学習①
by
ssuser60e2a31
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PDF
NN, CNN, and Image Analysis
by
Yuki Shimada
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PPTX
深層学習入門 スライド
by
swamp Sawa
PDF
20160329.dnn講演
by
Hayaru SHOUNO
PDF
Deep learning入門
by
magoroku Yamamoto
PDF
Deep learning Libs @twm
by
Yuta Kashino
PDF
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
PPTX
PRML Chapter 5
by
Masahito Ohue
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
ディープラーニングのすごさを共有したい.pdf
by
Yusuke Hayashi
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
Report2
by
YoshikazuHayashi3
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
深層学習の数理
by
Taiji Suzuki
PRML_from5.1to5.3.1
by
禎晃 山崎
社内機械学習勉強会 #5
by
shingo suzuki
Deep Learning Chap. 6: Deep Feedforward Networks
by
Shion Honda
Deep learning実装の基礎と実践
by
Seiya Tokui
深層学習①
by
ssuser60e2a31
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
NN, CNN, and Image Analysis
by
Yuki Shimada
20170422 数学カフェ Part1
by
Kenta Oono
深層学習入門 スライド
by
swamp Sawa
20160329.dnn講演
by
Hayaru SHOUNO
Deep learning入門
by
magoroku Yamamoto
Deep learning Libs @twm
by
Yuta Kashino
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
PRML Chapter 5
by
Masahito Ohue
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
More from Naoki Watanabe
PPTX
shuumai deep learning
by
Naoki Watanabe
PPTX
アントレプレナーシップ論講座の卒業生による話(2019/04/20)
by
Naoki Watanabe
PPTX
Basic explanation of Generative adversarial networks on MNIST
by
Naoki Watanabe
PPTX
Create line bot with Google Apps Script
by
Naoki Watanabe
PDF
LINE bot with Google Apps Script to manage reservation
by
Naoki Watanabe
PPTX
Lecuture on Deep Learning API
by
Naoki Watanabe
PPTX
tinder automation
by
Naoki Watanabe
PPTX
Programming Lecture 2nd - Flask and Heroku in Python -
by
Naoki Watanabe
PPTX
Programming Lecture 1st
by
Naoki Watanabe
PPTX
Lecture for Bootstrap and flask in Python
by
Naoki Watanabe
PPTX
Mcluhan’s medium
by
Naoki Watanabe
PPTX
Bitcoin4beginners
by
Naoki Watanabe
PPTX
物理はどこで発見されるか
by
Naoki Watanabe
PDF
ちょうかんたんワインこうざ
by
Naoki Watanabe
shuumai deep learning
by
Naoki Watanabe
アントレプレナーシップ論講座の卒業生による話(2019/04/20)
by
Naoki Watanabe
Basic explanation of Generative adversarial networks on MNIST
by
Naoki Watanabe
Create line bot with Google Apps Script
by
Naoki Watanabe
LINE bot with Google Apps Script to manage reservation
by
Naoki Watanabe
Lecuture on Deep Learning API
by
Naoki Watanabe
tinder automation
by
Naoki Watanabe
Programming Lecture 2nd - Flask and Heroku in Python -
by
Naoki Watanabe
Programming Lecture 1st
by
Naoki Watanabe
Lecture for Bootstrap and flask in Python
by
Naoki Watanabe
Mcluhan’s medium
by
Naoki Watanabe
Bitcoin4beginners
by
Naoki Watanabe
物理はどこで発見されるか
by
Naoki Watanabe
ちょうかんたんワインこうざ
by
Naoki Watanabe
Deep learning basics described
1.
初心者向けのディープラーニング講座 【サポーターズCoLab勉強会】 https://supporterzcolab.com/event/1023/ 渡邊直樹 1
2.
2 ニューラルネットワーク
3.
まず最初に言葉の説明: 最適化 ある条件で関数fを最小化(もしくは最大化)すること
たとえば、 − 1 ≤ 3𝑥0 + 2𝑥1 − 2 ≤ 𝑥0 + 5𝑥1 の条件のもとで下記式の最小化 2𝑥0 + 3𝑥1 なので、たとえば「スマホの最適化」などの使われ方と意味が異なる 3
4.
4 線形と非線形 たびたび出てくる言葉とその概念について説明 6序文
5.
線形と非線形 𝑓が線形 (線型, linear)
とは次の二つの性質が成り立つことである 加法性: 𝑓 𝑥 + 𝑦 = 𝑓 𝑥 + 𝑓 𝑦 𝑓𝑜𝑟 𝑎𝑙𝑙 𝑥, 𝑦 斉次性: 𝑓 𝑘𝑥 = 𝑘𝑓 𝑥 𝑓𝑜𝑟 𝑎𝑙𝑙 𝑘, 𝑥 たとえば、 𝑓 𝑥 = 2𝑥のとき, 𝑓 1 + 2 = 𝑓 1 + 𝑓 2 𝑓 6 = 3𝑓 2 行列を掛ける変換は線型変換(右図) 5
6.
線形と非線形の例 線形なもの 非線形なもの 6 ax
+ b 1 2 x +1 ax + by ax2 + bx + c ax3 + bx2 + cx + d ex sin(x) 1 x ax2 + 2bxy + cy2
7.
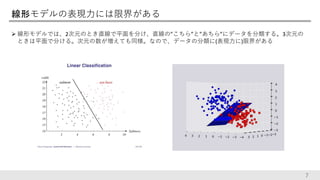
線形モデルの表現力には限界がある 線形モデルでは、2次元のとき直線で平面を分け、直線の”こちら”と”あちら”にデータを分類する。3次元の ときは平面で分ける。次元の数が増えても同様。なので、データの分類に(表現力に)限界がある 7
8.
8 ディープラーニング概論 手短に
9.
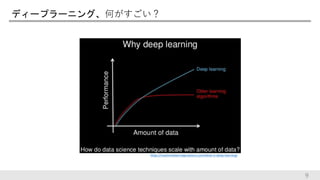
ディープラーニング、何がすごい? 9 https://machinelearningmastery.com/what-is-deep-learning/
10.
Neurons and the
brain 10
11.
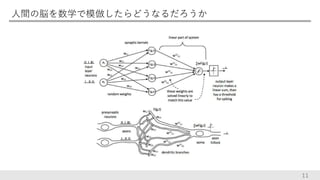
人間の脳を数学で模倣したらどうなるだろうか 11
12.
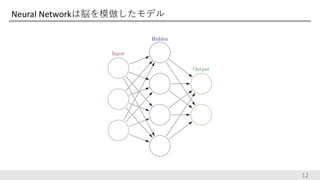
Neural Networkは脳を模倣したモデル 12
13.
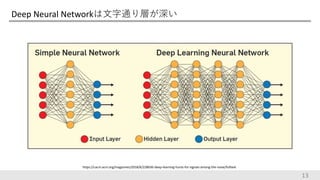
Deep Neural Networkは文字通り層が深い 13 https://cacm.acm.org/magazines/2018/6/228030-deep-learning-hunts-for-signals-among-the-noise/fulltext
14.
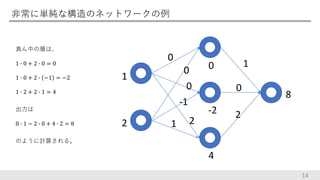
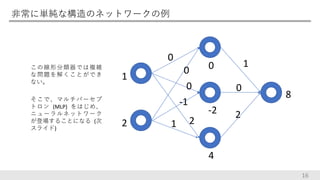
非常に単純な構造のネットワークの例 14 真ん中の層は、 1 ∙ 0
+ 2 ∙ 0 = 0 1 ∙ 0 + 2 ∙ −1 = −2 1 ∙ 2 + 2 ∙ 1 = 4 出力は 0 ∙ 1 − 2 ∙ 0 + 4 ∙ 2 = 8 のように計算される。 1 2 0 0 0 2 -1 1 0 -2 4 1 0 2 8
15.
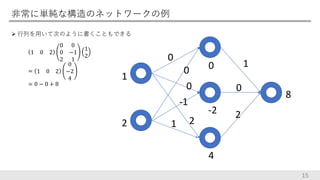
非常に単純な構造のネットワークの例 行列を用いて次のように書くこともできる 15 1 0
2 0 0 0 −1 2 1 1 2 = 1 0 2 0 −2 4 = 0 − 0 + 8 1 2 0 0 0 2 -1 1 0 -2 4 1 0 2 8
16.
非常に単純な構造のネットワークの例 16 この線形分類器では複雑 な問題を解くことができ ない。 そこで、マルチパーセプ トロン (MLP) をはじめ、 ニューラルネットワーク が登場することになる
(次 スライド) 1 2 0 0 0 2 -1 1 0 -2 4 1 0 2 8
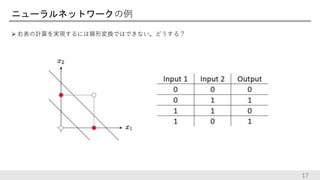
17.
ニューラルネットワークの例 右表の計算を実現するには線形変換ではできない。どうする? 17
18.
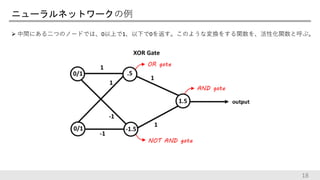
ニューラルネットワークの例 中間にある二つのノードでは、0以上で1、以下で0を返す。このような変換をする関数を、活性化関数と呼ぶ。 18
19.
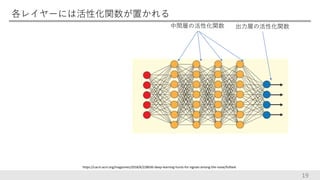
各レイヤーには活性化関数が置かれる 19 https://cacm.acm.org/magazines/2018/6/228030-deep-learning-hunts-for-signals-among-the-noise/fulltext 中間層の活性化関数 出力層の活性化関数
20.
入力に対して、線形変換Wと活性化関数Σの層を繰り返していく 𝑦 =
𝜎 𝑜𝑢𝑡𝑝𝑢𝑡 𝑊𝑛 𝜎𝑊𝑛−1 … 𝜎𝑊𝑥 20
21.
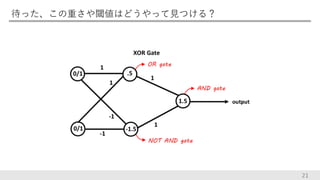
待った、この重さや閾値はどうやって見つける? 21
22.
22 損失関数 基本の最小二乗法 6.2.1
23.
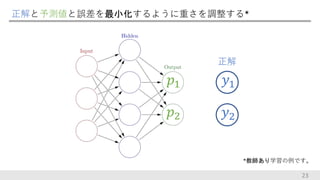
正解と予測値と誤差を最小化するように重さを調整する* 23 *教師あり学習の例です。 𝑝2 𝑝1 正解 𝑦2 𝑦1
24.
たとえば、差を最小化。 24 𝐿 = |𝑦1
− 𝑝1| + |𝑦2 − 𝑝2|
25.
もしくは、差の二乗和を最小化 25 𝐿 = (𝑦1
− 𝑝1)2 + (𝑦2 − 𝑝2)2
26.
さて、どうやって最小化する? ニューラルネットワークの重さwを変化させて予測値を正解に近づけたい 一次関数や二次関数と違って、解析的に解を求められない
最適なwをどうやって見つければよいのか? 26
27.
27 最急降下法
28.
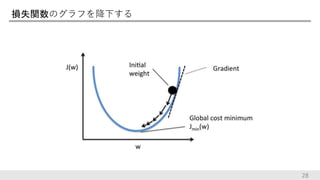
損失関数のグラフを降下する 28
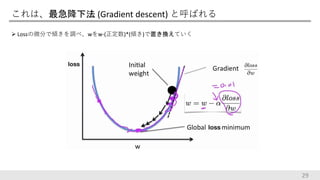
29.
これは、最急降下法 (Gradient descent)
と呼ばれる Lossの微分で傾きを調べ、wをw-(正定数)*(傾き)で置き換えていく 29
30.
30 出力層の活性化関数 6.2.2
31.
体重や年齢や住宅価格などの数字予測 − そのまま出力
写真や動画や文章の分類 − 出力層の値zに対して次のように正規化 (softmax関数)することで、各値を各クラスに属する確率とみなす。 31 p(y = k | x) µ e zk , p(y = k | x) = e zk ezi i å
32.
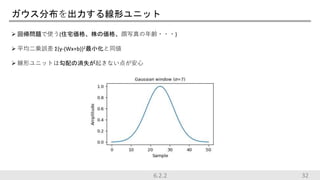
ガウス分布を出力する線形ユニット 回帰問題で使う(住宅価格、株の価格、顔写真の年齢・・・) 平均二乗誤差
Σ{y-(Wx+b)}2最小化と同値 線形ユニットは勾配の消失が起きない点が安心 6.2.2 32
33.
33 隠れ層(中間層) 6.3
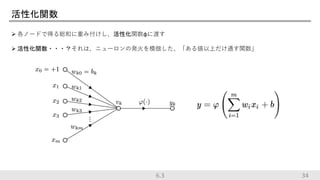
34.
活性化関数 各ノードで得る総和に重み付けし、活性化関数φに渡す 活性化関数・・・?それは、ニューロンの発火を模倣した、「ある値以上だけ通す関数」 346.3
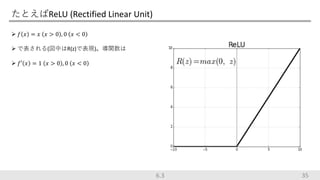
35.
たとえばReLU (Rectified Linear
Unit) 𝑓 𝑥 = 𝑥 𝑥 > 0 , 0 𝑥 < 0 で表される(図中はR(z)で表現)。導関数は 𝑓′ 𝑥 = 1 𝑥 > 0 , 0 𝑥 < 0 356.3
36.
様々な活性化関数 step: 50年代流行
sigmoid: 80年代 tanh: 90年代流行 現在: ReLU主流 Sigmoidも勾配消失する (導関数の最大値が1/4なので 乗算を続けると値が0に近づいていく) Sigmoidの導関数は計算が容易 𝑓′(𝑥) = 𝑓(𝑥)(1 − 𝑓 𝑥 ) 366.3
37.
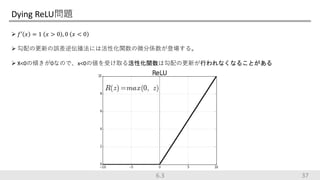
Dying ReLU問題 𝑓′
𝑥 = 1 𝑥 > 0 , 0 𝑥 < 0 勾配の更新の誤差逆伝播法には活性化関数の微分係数が登場する。 X<0の傾きが0なので、x<0の値を受け取る活性化関数は勾配の更新が行われなくなることがある 376.3
38.
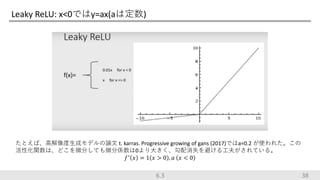
Leaky ReLU: x<0ではy=ax(aは定数) 38 たとえば、高解像度生成モデルの論文
t. karras. Progressive growing of gans (2017)ではa=0.2 が使われた。この 活性化関数は、どこを微分しても微分係数は0より大きく、勾配消失を避ける工夫がされている。 𝑓′ 𝑥 = 1 𝑥 > 0 , 𝑎 𝑥 < 0 6.3
39.
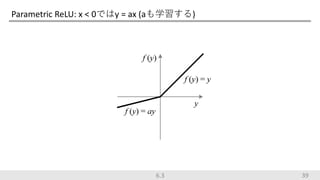
Parametric ReLU: x
< 0ではy = ax (aも学習する) 396.3
40.
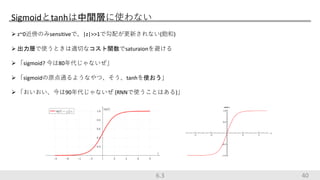
Sigmoidとtanhは中間層に使わない z~0近傍のみsensitiveで、|z|>>1で勾配が更新されない(飽和) 出力層で使うときは適切なコスト関数でsaturaionを避ける
「sigmoid? 今は80年代じゃないぜ」 「sigmoidの原点通るようなやつ、そう、tanhを使おう」 「おいおい、今は90年代じゃないぜ (RNNで使うことはある)」 406.3
41.
活性化関数を使うと非線形になる 活性化関数を使わないDNNは、1層と変わらない 入力のベクトルをx,
隠れ層の重さ行列をW, W’, …, とすると、出力PはXの線形変換で表されてしまう! P=W’’’…W’WX = (W’’’…W’W)X しかし、非線形な活性化関数σをレイヤー出力に作用させると P=σW’’’σ…σW’σWX となり、線形変換にならず、複雑なモデルを構築できる 416.3
42.
42 ネットワークの構造設計 6.4
43.
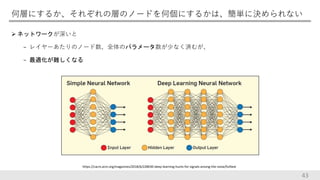
何層にするか、それぞれの層のノードを何個にするかは、簡単に決められない ネットワークが深いと − レイヤーあたりのノード数、全体のパラメータ数が少なく済むが、 −
最適化が難しくなる 43 https://cacm.acm.org/magazines/2018/6/228030-deep-learning-hunts-for-signals-among-the-noise/fulltext
44.
44 誤差逆伝播
45.
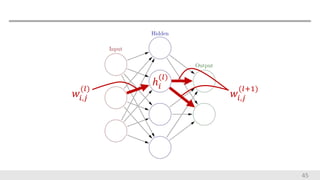
45 𝑤𝑖,𝑗 (𝑙) 𝑤𝑖,𝑗 (𝑙+1) ℎ𝑖 (𝑙)
46.
逆誤差伝播法の漸化式 𝐿: 損失関数の値
ℎ𝑖 (𝑙) : l層目の隠れ層の値 𝜑: 活性化関数 𝑤𝑖,𝑗 (𝑙) : 𝑙層目の重さの値 𝑣𝑖 (𝑙+1) = 𝑗 𝑤𝑖,𝑗 (𝑙+1) ℎ𝑗 (𝑙) ℎ𝑖 (𝑙) = 𝜑(𝑣𝑖 (𝑙) ) 𝜕𝐿 𝜕𝑣𝑖 (𝑙) が逆伝播の漸化式を構成 46 𝜕𝐿 𝜕𝑤𝑖,𝑗 (𝑙) = 𝜕𝐿 𝜕𝑣𝑖 (𝑙) 𝜕𝑣𝑖 (𝑙) 𝜕𝑤𝑖,𝑗 (𝑙) = 𝜕𝐿 𝜕𝑣𝑖 (𝑙) ℎ𝑖 (𝑙) 𝜕𝐿 𝜕𝑣𝑖 (𝑙) = 𝜕𝐿 𝜕ℎ𝑖 (𝑙) 𝜕ℎ𝑖 (𝑙) 𝜕𝑣𝑖 (𝑙) = 𝑗 𝜕𝐿 𝜕𝑣𝑗 (𝑙+1) 𝜕𝑣𝑗 (𝑙+1) 𝜕ℎ𝑖 (𝑙) 𝜕ℎ𝑖 (𝑙) 𝜕𝑣𝑖 (𝑙) = 𝑗 𝜕𝐿 𝜕𝑣𝑗 (𝑙+1) 𝑤𝑖,𝑗 (𝑙+1) 𝜑′(𝑣𝑖 (𝑙) )
47.
47 ディープラーニングの 正則化手法 7.1.1
48.
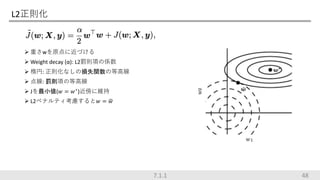
L2正則化 7.1.1 48 重さwを原点に近づける
Weight decay (α): L2罰則項の係数 楕円: 正則化なしの損失関数の等高線 点線: 罰則項の等高線 Jを最小値(𝑤 = 𝑤∗ )近傍に維持 L2ペナルティ考慮すると𝑤 = 𝑤
49.
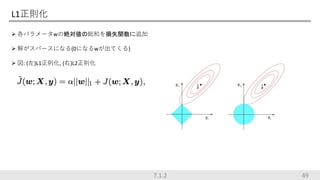
L1正則化 各パラメータwの絶対値の総和を損失関数に追加 解がスパースになる(0になるwが出てくる)
図: (左)L1正則化, (右)L2正則化 7.1.2 49
50.
50 水増し (Augmentation) 7.4
51.
データ集合の拡張 Augmentationや水増しとも呼ばれる。手持ちのデータを加工してデータの数を増やす 水平判定、輝度変化、傾き、回転、ノイズなど
次ページに具体例 7.4 51
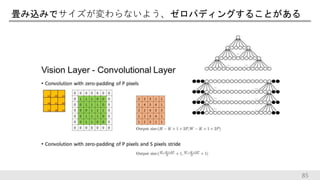
52.
527.4 https://github.com/aleju/imgaug
53.
53 ノイズ 7.5
54.
ノイズに対する頑健性 入力に対するノイズ − 無限小𝜀2 の分散を持つノイズを入力に与えるとことは、重さの大きさ
𝒘 に制限を与えるのと等価 − 隠れ層へノイズを与えるとさらに強力 (パラメータ数縮小より強力) − ℎ𝑖 (𝑙+1) = 𝜎 𝑤𝑖,𝑗 (𝑙) ℎ𝑗 (𝑙) + 𝑏𝑖 (𝑙) + 𝑁(0, 𝜀2 ) − Dropoutはこれに基づく正則化手法 重さに対するノイズ − ある仮定のもとでは正則化の効果 − 損失関数の、平坦な中にある窪み(極小値)にたどり着くこともある 出力層に対するノイズ − 正解ラベルがそもそも正しくないこともある − K個分類の場合、y = 0 → 𝑦 = 𝜀 𝑘−1 , 𝑦 = 1 → 𝑦 = 1 − 𝜀 547.5
55.
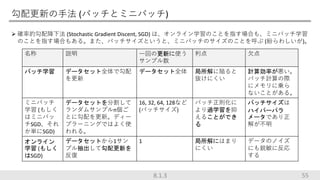
勾配更新の手法 (バッチとミニバッチ) 55 名称 説明
一回の更新に使う サンプル数 利点 欠点 バッチ学習 データセット全体で勾配 を更新 データセット全体 局所解に陥ると 抜けにくい 計算効率が悪い。 バッチ計算の際 にメモリに乗ら ないことがある。 ミニバッチ 学習 (もしく はミニバッ チSGD、それ か単にSGD) データセットを分割して ランダムサンプルn個ご とに勾配を更新。ディー プラーニングではよく使 われる。 16, 32, 64, 128など (バッチサイズ) バッチ正則化に より過学習を抑 えることができ る バッチサイズは ハイパーパラ メータであり正 解が不明 オンライン 学習 (もしく はSGD) データセットから1サン プル抽出して勾配更新を 反復 1 局所解にはまり にくい データのノイズ にも鋭敏に反応 する 8.1.3 確率的勾配降下法 (Stochastic Gradient Discent, SGD) は、オンライン学習のことを指す場合も、ミニバッチ学習 のことを指す場合もある。また、バッチサイズというと、ミニバッチのサイズのことを呼ぶ (紛らわしいが)。
56.
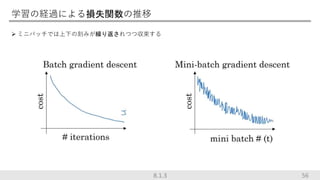
学習の経過による損失関数の推移 ミニバッチでは上下の刻みが繰り返されつつ収束する 568.1.3
57.
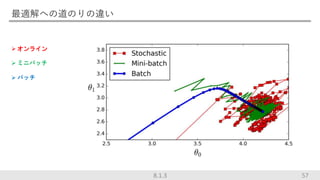
最適解への道のりの違い オンライン ミニバッチ
バッチ 578.1.3
58.
悪条件 ヘッセ行列は「悪条件」のこともある (パラメータの小さな更新Δwが、損失コストの値を大きく増やす)
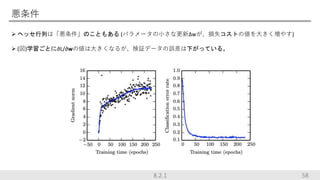
(図)学習ごとに∂L/∂wの値は大きくなるが、検証データの誤差は下がっている。 588.2.1
59.
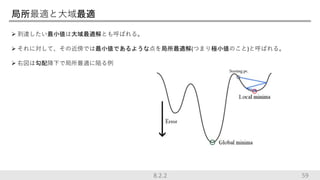
局所最適と大域最適 到達したい最小値は大域最適解とも呼ばれる。 それに対して、その近傍では最小値であるような点を局所最適解(つまり極小値のこと)と呼ばれる。
右図は勾配降下で局所最適に陥る例 598.2.2
60.
鞍点とプラトー x1にとっては極大値、X2にとっては極小値となるような点は鞍点(saddle point)と呼ばれる。 (x1,
x2は任意のパラメーター) 608.2.3
61.
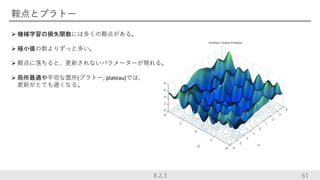
鞍点とプラトー 機械学習の損失関数には多くの鞍点がある。 極小値の数よりずっと多い。
鞍点に落ちると、更新されないパラメーターが現れる。 局所最適や平坦な箇所(プラトー, plateau)では、 更新がとても遅くなる。 618.2.3
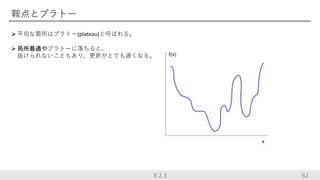
62.
鞍点とプラトー 平坦な箇所はプラトー(plateau)と呼ばれる。 局所最適やプラトーに落ちると、 抜けられないこともあり、更新がとても遅くなる。 628.2.3
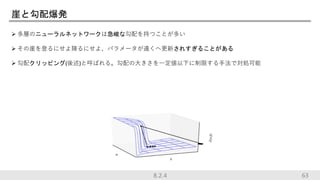
63.
崖と勾配爆発 多層のニューラルネットワークは急峻な勾配を持つことが多い その崖を登るにせよ降るにせよ、パラメータが遠くへ更新されすぎることがある
勾配クリッピング(後述)と呼ばれる。勾配の大きさを一定値以下に制限する手法で対処可能 638.2.4
64.
不正確な勾配 ほとんどの最適化アルゴリズムは、正確な勾配やヘッセ行列を前提としている 実際には、ノイズやバイアスのある推定を行うほかない
目的関数やその微分が扱いづらい場合もある。 その場合、導関数を近似することがある 648.2.6
65.
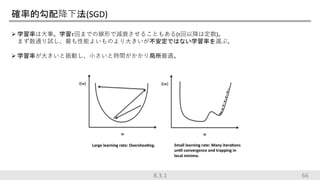
確率的勾配降下法(SGD) 機械学習でもディープラーニングでもよく使われる最適化手法 ミニバッチの勾配の平均を計算して勾配の不偏推定量を得る 658.3.1
66.
確率的勾配降下法(SGD) 学習率は大事。学習𝜏回までの線形で減衰させることもある(τ回以降は定数)。 まず数通り試し、最も性能よいものより大きいが不安定ではない学習率を選ぶ。 学習率が大きいと振動し、小さいと時間がかかり局所最適。 668.3.1
67.
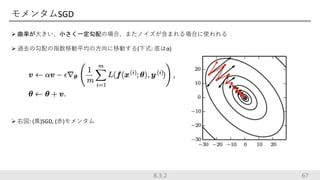
モメンタムSGD 曲率が大きい、小さく一定勾配の場合、またノイズが含まれる場合に使われる 過去の勾配の指数移動平均の方向に移動する(下式:
底はα) 右図: (黒)SGD, (赤)モメンタム 678.3.2
68.
AdaGrad 各パラメータごとに更新の大きさが異なる。勾配が大きくなりやすいパラメータと、小さくなりやすいパラ メータの間で学習の速さを等しくする。学習率は学習とともに減少しゼロに漸近する。 𝑔𝑡 𝑖 = ∇
𝜃 𝐽 𝜃𝑡 𝑖 , 𝜃𝑡+1 𝑖 = 𝜃𝑡 𝑖 − 𝜂 𝐺𝑡 𝑖𝑖 + 𝜀 ∙ 𝑔𝑡 𝑖 ここで、 𝐺𝑡 𝑖𝑖 は時刻tまでの𝜃 𝑖 による勾配であり、 𝜀はゼロ除算を避けるための微小定数、𝜂は学習率であるが、 AdaGradでは学習率のチューニングが不要である。この計算は、ベクトル表記にすることもできる。ただし、 Gについての-1/2乗の計算は成分ごとに行う。 𝜃𝑡+1 = 𝜃𝑡 − 𝜂 𝐺𝑡 + 𝜀 𝑔𝑡 8.5.1 68
69.
RMSprop AdaGradの改良版。勾配の二乗の指数移動平均をとるよう変更(より直近の勾配更新を優先して計算する)。 698.5.2
70.
Adam AdaGradやRMSpropやAdaDelta(説明略)の改良版。指数移動平均のバイアスを 𝑚,
𝑣で打ち消している 708.5.3
71.
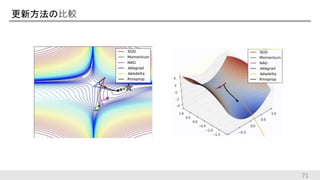
更新方法の比較 71
72.
Batch Normalization (バッチ正則化)
各レイヤーのノード数が1のネットワークを例に考える 𝑦 = 𝑤𝑙 … 𝑤2 𝑤1 𝑥 各wの勾配をgとすると更新後は 𝑦 = (𝑤𝑙−𝜀𝑔𝑙) … (𝑤2−𝜀𝑔2)(𝑤1 − 𝜀𝑔1)𝑥 右辺を展開すると、たとえば、 |g|>1のとき、 |𝜀2 𝑤1 𝑤2 𝑔3 … 𝑔𝑙| ≫ 1となり、適切な更新を邪魔する 各勾配は他のパラメータを固定して計算するので、大域的に誤った更新をすることがある 二回微分で防ぐこともできるが、計算コストが合わない 入力値の分布が後半の層では違う分布になり、各層ではその分布変化に対応することに懸命になり、学習が なかなか進まない 各隠れ層の出力の分布を同じくすることで解決させる 728.7.1
73.
Batch Normalization (バッチ正則化)
ミニバッチ内ごとに処理 出力層を平均β、標準偏差γに変換 73
74.
Batch Normalization (バッチ正則化)
これまで、後半の層は前半の層の分布変化の影響を受けてた 先ほどの例では、出力層はl-1層以前の影響を無視できるようになるので、BNでは 𝑦 = 𝑤𝑙ℎ𝑙−1 として線形に扱 うことができる。 L2正則化や、学習時間が長くなるDropoutの必要性が下がる 74
75.
Batch Normalizationの効果比較 75
76.
76 Convolutional Neural Network 畳み込みニューラルネットワーク
77.
例)ネコの画像分類 77 [('Abyssinian', 0.621), ('Bengal',
0.144), ('Sphynx', 0.087)] [('Bengal', 0.583), ('Egyptian_Mau', 0.107), ('Persian', 0.092)] [('Russian_Blue', 0.581), ('British_Shorthair', 0.226), ('Abyssinian', 0.057)] The Oxford-IIIT-Pet dataset 9.1
78.
画像におけるニューラルネットワーク 畳み込み層 (線形変換)
活性化関数(非線形) Pooling(エッジ検出) の3つセットの繰り返しで構成されることが典型的。次スライドから順に見ていく 78
79.
光はRed, Green, Blueの三原色で表せる 79
80.
RGBそれぞれは行列で表現される 80
81.
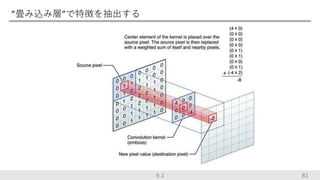
81 ”畳み込み層”で特徴を抽出する 9.1
82.
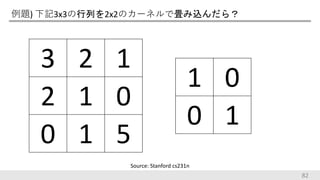
例題) 下記3x3の行列を2x2のカーネルで畳み込んだら? 82 3 2
1 2 1 0 0 1 5 1 0 0 1 Source: Stanford cs231n
83.
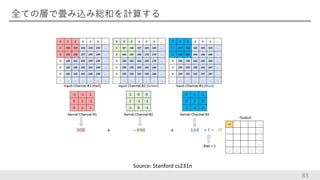
全ての層で畳み込み総和を計算する 83 Source: Stanford cs231n
84.
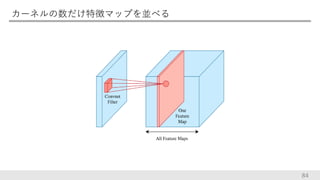
カーネルの数だけ特徴マップを並べる 84
85.
畳み込みでサイズが変わらないよう、ゼロパディングすることがある 85
86.
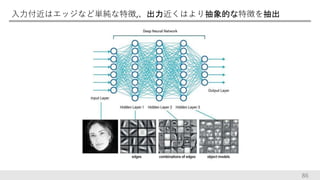
入力付近はエッジなど単純な特徴,、出力近くはより抽象的な特徴を抽出 86
87.
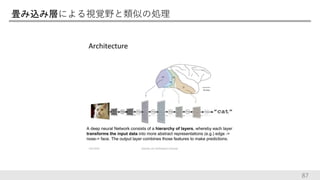
畳み込み層による視覚野と類似の処理 87
88.
Pooling層 (Max Pooling,
Average Pooling) Sliding-windowの最大値もしくは平均値をとる (図は最大値) 計算量が減る ロバスト性を持つ 889.3
89.
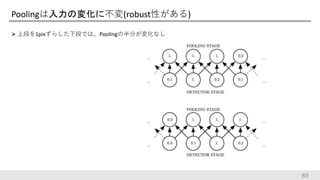
Poolingは入力の変化に不変(robust性がある) 上段を1pixずらした下段では、Poolingの半分が変化なし 89
90.
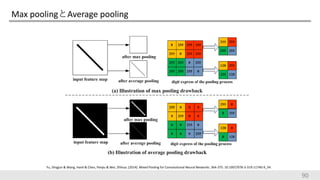
Max poolingとAverage pooling 90 Yu,
Dingjun & Wang, Hanli & Chen, Peiqiu & Wei, Zhihua. (2014). Mixed Pooling for Convolutional Neural Networks. 364-375. 10.1007/978-3-319-11740-9_34.
91.
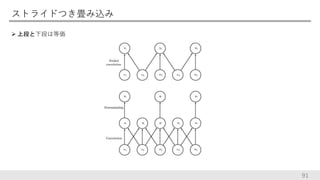
ストライドつき畳み込み 上段と下段は等価 91
92.
全結合層 92
93.
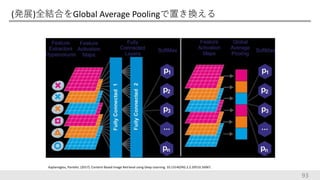
(発展)全結合をGlobal Average Poolingで置き換える 93 Kaplanoglou,
Pantelis. (2017). Content-Based Image Retrieval using Deep Learning. 10.13140/RG.2.2.29510.16967.
94.
ピクセル単位でクラス分けすることも可能 94 farabet et al,
2013 9.6
95.
畳み込みは様々なデータの形式に対応 音声: (t)
(t=time) フーリエ変換: (t, f) (t=time; f=frequency) 白黒画像: (w, h) (w=width; h=height) 画像: (c, w, h) (c=r, g, b; w=width; h=height) 動画: (t, c, w, h) (t=time; c=r, g, b; w=width; h=height) 95 source: subsubroutine.com 9.7
96.
96 よく使われるモデルの紹介
97.
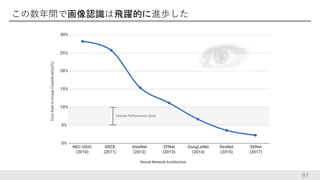
この数年間で画像認識は飛躍的に進歩した 97
98.
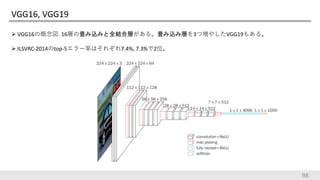
VGG16, VGG19 VGG16の概念図.
16層の畳み込みと全結合層がある。畳み込み層を3つ増やしたVGG19もある。 ILSVRC-2014のtop-5エラー率はそれぞれ7.4%, 7.3%で2位。 98
99.
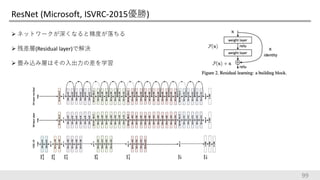
ResNet (Microsoft, ISVRC-2015優勝)
ネットワークが深くなると精度が落ちる 残差層(Residual layer)で解決 畳み込み層はその入出力の差を学習 99
100.
100 End of slides
Download




































![例)ネコの画像分類
77
[('Abyssinian', 0.621), ('Bengal', 0.144), ('Sphynx', 0.087)]
[('Bengal', 0.583), ('Egyptian_Mau', 0.107), ('Persian', 0.092)] [('Russian_Blue', 0.581), ('British_Shorthair', 0.226),
('Abyssinian', 0.057)]
The Oxford-IIIT-Pet dataset
9.1](https://image.slidesharecdn.com/shibuya20191219-191219115037/85/Deep-learning-basics-described-77-320.jpg)