Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Kensuke Otsuki
PDF, PPTX
7,080 views
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
これからディープラーニングを学ぶ方のための資料を作りました。応用先としては画像処理・自然言語処理に絞って解説を行っています。
Technology
◦
Related topics:
Deep Learning
•
Read more
12
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 94
2
/ 94
3
/ 94
4
/ 94
Most read
5
/ 94
6
/ 94
7
/ 94
8
/ 94
9
/ 94
10
/ 94
11
/ 94
Most read
12
/ 94
13
/ 94
Most read
14
/ 94
15
/ 94
16
/ 94
17
/ 94
18
/ 94
19
/ 94
20
/ 94
21
/ 94
22
/ 94
23
/ 94
24
/ 94
25
/ 94
26
/ 94
27
/ 94
28
/ 94
29
/ 94
30
/ 94
31
/ 94
32
/ 94
33
/ 94
34
/ 94
35
/ 94
36
/ 94
37
/ 94
38
/ 94
39
/ 94
40
/ 94
41
/ 94
42
/ 94
43
/ 94
44
/ 94
45
/ 94
46
/ 94
47
/ 94
48
/ 94
49
/ 94
50
/ 94
51
/ 94
52
/ 94
53
/ 94
54
/ 94
55
/ 94
56
/ 94
57
/ 94
58
/ 94
59
/ 94
60
/ 94
61
/ 94
62
/ 94
63
/ 94
64
/ 94
65
/ 94
66
/ 94
67
/ 94
68
/ 94
69
/ 94
70
/ 94
71
/ 94
72
/ 94
73
/ 94
74
/ 94
75
/ 94
76
/ 94
77
/ 94
78
/ 94
79
/ 94
80
/ 94
81
/ 94
82
/ 94
83
/ 94
84
/ 94
85
/ 94
86
/ 94
87
/ 94
88
/ 94
89
/ 94
90
/ 94
91
/ 94
92
/ 94
93
/ 94
94
/ 94
More Related Content
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
線形計画法入門
by
Shunji Umetani
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PDF
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
最適輸送の計算アルゴリズムの研究動向
by
ohken
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
線形計画法入門
by
Shunji Umetani
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
What's hot
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PPTX
畳み込みニューラルネットワークの研究動向
by
Yusuke Uchida
PDF
最適輸送の解き方
by
joisino
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
by
Kosuke Shinoda
PDF
因果推論の奥へ: "What works" meets "why it works"
by
takehikoihayashi
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
モデル高速化百選
by
Yusuke Uchida
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
pymcとpystanでベイズ推定してみた話
by
Classi.corp
PDF
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
PDF
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
PDF
【メタサーベイ】Video Transformer
by
cvpaper. challenge
PDF
[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...
by
Deep Learning JP
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PPTX
【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
by
Deep Learning JP
PDF
機械学習モデルのハイパパラメータ最適化
by
gree_tech
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
生成モデルの Deep Learning
by
Seiya Tokui
畳み込みニューラルネットワークの研究動向
by
Yusuke Uchida
最適輸送の解き方
by
joisino
不均衡データのクラス分類
by
Shintaro Fukushima
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
by
Kosuke Shinoda
因果推論の奥へ: "What works" meets "why it works"
by
takehikoihayashi
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
モデル高速化百選
by
Yusuke Uchida
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
pymcとpystanでベイズ推定してみた話
by
Classi.corp
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
【メタサーベイ】Video Transformer
by
cvpaper. challenge
[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...
by
Deep Learning JP
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
by
Deep Learning JP
機械学習モデルのハイパパラメータ最適化
by
gree_tech
Optimizer入門&最新動向
by
Motokawa Tetsuya
Similar to ディープラーニング入門 ~ 画像処理・自然言語処理について ~
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PPTX
Deep learning basics described
by
Naoki Watanabe
PDF
確率的深層学習における中間層の改良と高性能学習法の提案
by
__106__
PDF
Deep learning入門
by
magoroku Yamamoto
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PPTX
深層学習の基礎と導入
by
Kazuki Motohashi
PPTX
エンジニアのための機械学習の基礎
by
Daiyu Hatakeyama
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PPTX
DNNの曖昧性に関する研究動向
by
Naoki Matsunaga
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PDF
PRML_from5.1to5.3.1
by
禎晃 山崎
PPTX
PRML Chapter 5
by
Masahito Ohue
PDF
NN, CNN, and Image Analysis
by
Yuki Shimada
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PDF
社内機械学習勉強会 #5
by
shingo suzuki
PPT
Deep Learningの技術と未来
by
Seiya Tokui
PDF
20160329.dnn講演
by
Hayaru SHOUNO
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
PDF
ディープニューラルネット入門
by
TanUkkii
深層学習の数理
by
Taiji Suzuki
20170422 数学カフェ Part1
by
Kenta Oono
Deep learning basics described
by
Naoki Watanabe
確率的深層学習における中間層の改良と高性能学習法の提案
by
__106__
Deep learning入門
by
magoroku Yamamoto
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
深層学習の基礎と導入
by
Kazuki Motohashi
エンジニアのための機械学習の基礎
by
Daiyu Hatakeyama
Deep learning実装の基礎と実践
by
Seiya Tokui
DNNの曖昧性に関する研究動向
by
Naoki Matsunaga
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PRML_from5.1to5.3.1
by
禎晃 山崎
PRML Chapter 5
by
Masahito Ohue
NN, CNN, and Image Analysis
by
Yuki Shimada
W8PRML5.1-5.3
by
Masahito Ohue
社内機械学習勉強会 #5
by
shingo suzuki
Deep Learningの技術と未来
by
Seiya Tokui
20160329.dnn講演
by
Hayaru SHOUNO
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
ディープニューラルネット入門
by
TanUkkii
More from Kensuke Otsuki
PDF
ものづくりに活かす数学 (2024 年 1 月 26 日 N/S 高等学校での数学の授業)
by
Kensuke Otsuki
PDF
競プロは人生の役に立つ!
by
Kensuke Otsuki
PDF
人それぞれの競プロとの向き合い方
by
Kensuke Otsuki
PDF
アルゴリズムを楽しく!@PiyogrammerConference
by
Kensuke Otsuki
PDF
区間分割の仕方を最適化する動的計画法 (JOI 2021 夏季セミナー)
by
Kensuke Otsuki
PDF
「現実世界に活かす数学」 (麻布高等学校、教養総合、数学講義 5 回目)
by
Kensuke Otsuki
PDF
JOI春季ステップアップセミナー 2021 講義スライド
by
Kensuke Otsuki
PDF
IT エンジニア本大賞 2021 講演資料
by
Kensuke Otsuki
PDF
210122 msi dp
by
Kensuke Otsuki
PDF
Optimization night 4_dp
by
Kensuke Otsuki
PDF
『問題解決力を鍛える!アルゴリズムとデータ構造』出版記念講演
by
Kensuke Otsuki
PDF
虫食算に学ぶ、深さ優先探索アルゴリズム (combmof, 2018/12/23)
by
Kensuke Otsuki
PDF
二部グラフの最小点被覆と最大安定集合と最小辺被覆の求め方
by
Kensuke Otsuki
PDF
2部グラフの最小点被覆の求め方
by
Kensuke Otsuki
PDF
虫食算を作るアルゴリズム 公表Ver
by
Kensuke Otsuki
ものづくりに活かす数学 (2024 年 1 月 26 日 N/S 高等学校での数学の授業)
by
Kensuke Otsuki
競プロは人生の役に立つ!
by
Kensuke Otsuki
人それぞれの競プロとの向き合い方
by
Kensuke Otsuki
アルゴリズムを楽しく!@PiyogrammerConference
by
Kensuke Otsuki
区間分割の仕方を最適化する動的計画法 (JOI 2021 夏季セミナー)
by
Kensuke Otsuki
「現実世界に活かす数学」 (麻布高等学校、教養総合、数学講義 5 回目)
by
Kensuke Otsuki
JOI春季ステップアップセミナー 2021 講義スライド
by
Kensuke Otsuki
IT エンジニア本大賞 2021 講演資料
by
Kensuke Otsuki
210122 msi dp
by
Kensuke Otsuki
Optimization night 4_dp
by
Kensuke Otsuki
『問題解決力を鍛える!アルゴリズムとデータ構造』出版記念講演
by
Kensuke Otsuki
虫食算に学ぶ、深さ優先探索アルゴリズム (combmof, 2018/12/23)
by
Kensuke Otsuki
二部グラフの最小点被覆と最大安定集合と最小辺被覆の求め方
by
Kensuke Otsuki
2部グラフの最小点被覆の求め方
by
Kensuke Otsuki
虫食算を作るアルゴリズム 公表Ver
by
Kensuke Otsuki
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
1.
© 2017 NTT
DATA Mathematical Systems Inc. ディープラーニング 入門 株式会社NTTデータ数理システム 2017 年度版 大槻 兼資
2.
2© 2017 NTT
DATA Mathematical Systems Inc. 2 イントロ ディープラーニングとは ディープラーニングの特徴 ディープラーニングの構成要素 ディープラーニングのチューニング技法 ディープラーニングを用いた画像処理 ディープラーニングを用いた自然言語処理 ディープラーニングを用いたマルチモーダル学習 内容
3.
3© 2017 NTT
DATA Mathematical Systems Inc. 3 イントロ ディープラーニングとは ディープラーニングの特徴 ディープラーニングの構成要素 ディープラーニングのチューニング技法 ディープラーニングを用いた画像処理 ディープラーニングを用いた自然言語処理 ディープラーニングを用いたマルチモーダル学習 内容
4.
4© 2017 NTT
DATA Mathematical Systems Inc. 4 機械学習の一手法 ディープラーニングとは 機械学習 ディープラーニング データの背後に潜むパターンを推測 データの理解・未来の予測が目標 脳を模した機械学習手法 画像認識、音声認識、自然言語処理、強化学習 などでブレイクスルーを起こす
5.
5© 2017 NTT
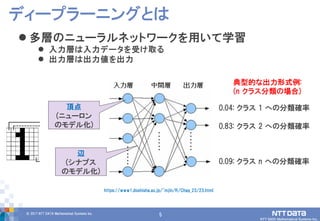
DATA Mathematical Systems Inc. 5 多層のニューラルネットワークを用いて学習 入力層は入力データを受け取る 出力層は出力値を出力 ディープラーニングとは https://www1.doshisha.ac.jp/~mjin/R/Chap_23/23.html 頂点 (ニューロン のモデル化) 辺 (シナプス のモデル化) 0.04: クラス 1 への分類確率 0.83: クラス 2 への分類確率 0.09: クラス n への分類確率 典型的な出力形式例: (n クラス分類の場合)
6.
6© 2017 NTT
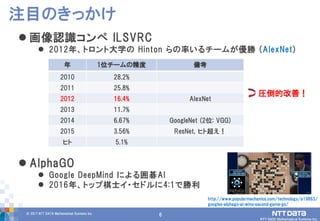
DATA Mathematical Systems Inc. 6 画像認識コンペ ILSVRC 2012年、トロント大学の Hinton らの率いるチームが優勝 (AlexNet) AlphaGO Google DeepMind による囲碁AI 2016年、トップ棋士イ・セドルに4:1で勝利 注目のきっかけ 圧倒的改善! 年 1位チームの精度 備考 2010 28.2% 2011 25.8% 2012 16.4% AlexNet 2013 11.7% 2014 6.67% GoogleNet (2位: VGG) 2015 3.56% ResNet, ヒト超え! ヒト 5.1% http://www.popularmechanics.com/technology/a19863/ googles-alphago-ai-wins-second-game-go/
7.
7© 2017 NTT
DATA Mathematical Systems Inc. 7 1943年: ニューロン素子モデル登場 1958年: パーセプトロン登場 1986年: 誤差逆伝播法 多層のニューラルネットワークの学習法! 2006年: 層ごとの事前学習 高い汎化能力! ニューラルネットワークのブームと冬の時代 McCulloch--Pitts Rosenblatt 過学習問題, 勾配消失問題などがあって 再び冬の時代, SVMなどの盛り上がり Rumelhart (1層の)単純パーセプトロンは 線形分離不可能なパターンを識別不能問題 いう問題を克服できず…冬の時代へ Hinton, Bengio, LeCun ら ※ 現在では Dropout といったテクニックや、ReLU といった活性化関数、GPU などのハードウェアの進歩、 また大量のデータから学習ができるようになったことなどもあり、事前学習はあまり使われなくなった
8.
8© 2017 NTT
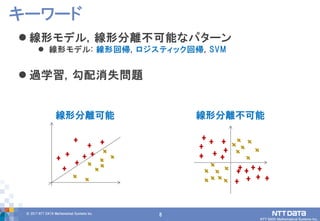
DATA Mathematical Systems Inc. 8 線形モデル, 線形分離不可能なパターン 線形モデル: 線形回帰, ロジスティック回帰, SVM 過学習, 勾配消失問題 キーワード 線形分離可能 線形分離不可能
9.
9© 2017 NTT
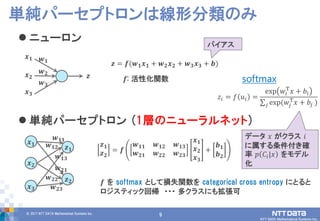
DATA Mathematical Systems Inc. 9 ニューロン 単純パーセプトロン (1層のニューラルネット) 単純パーセプトロンは線形分類のみ 𝒙 𝟏 𝒙 𝟐 𝒙 𝟑 𝒛 𝒘 𝟏 𝒘 𝟐 𝒘 𝟑 𝒛 = 𝒇(𝒘 𝟏 𝒙 𝟏 + 𝒘 𝟐 𝒙 𝟐 + 𝒘 𝟑 𝒙 𝟑 + 𝒃) 𝒇: 活性化関数 𝒙 𝟏 𝒙 𝟐 𝒙 𝟑 𝒛 𝟏 𝒛 𝟐 𝒘 𝟏𝟏 𝒘 𝟏𝟐 𝒘 𝟏𝟑 𝒘 𝟐𝟏 𝒘 𝟐𝟐 𝒘 𝟐𝟑 𝒛 𝟏 𝒛 𝟐 = 𝒇 𝒘 𝟏𝟏 𝒘 𝟏𝟐 𝒘 𝟏𝟑 𝒘 𝟐𝟏 𝒘 𝟐𝟐 𝒘 𝟐𝟑 𝒙 𝟏 𝒙 𝟐 𝒙 𝟑 + 𝒃 𝟏 𝒃 𝟐 𝒇 を softmax として損失関数を categorical cross entropy にとると ロジスティック回帰 ・・・ 多クラスにも拡張可 𝑧𝑖 = 𝑓 𝑢𝑖 = exp 𝑤𝑖 T 𝑥 + 𝑏𝑖 exp(𝑤𝑗 T 𝑥 + 𝑏𝑗 )𝑗 softmax データ 𝑥 がクラス 𝑖 に属する条件付き確 率 𝑝 𝐶𝑖|𝑥 をモデル 化 バイアス
10.
10© 2017 NTT
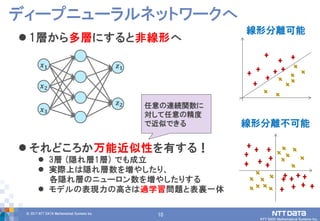
DATA Mathematical Systems Inc. 10 1層から多層にすると非線形へ それどころか万能近似性を有する! 3層 (隠れ層1層) でも成立 実際上は隠れ層数を増やしたり、 各隠れ層のニューロン数を増やしたりする モデルの表現力の高さは過学習問題と表裏一体 ディープニューラルネットワークへ 線形分離可能 線形分離不可能 𝒙 𝟏 𝒙 𝟐 𝒙 𝟑 𝒛 𝟏 𝒛 𝟐 任意の連続関数に 対して任意の精度 で近似できる
11.
11© 2017 NTT
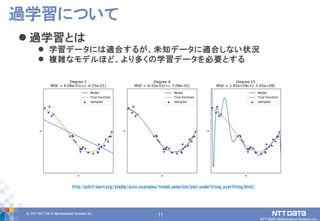
DATA Mathematical Systems Inc. 11 過学習とは 学習データには適合するが、未知データに適合しない状況 複雑なモデルほど、より多くの学習データを必要とする 過学習について http:/scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html/
12.
12© 2017 NTT
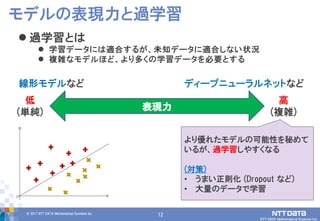
DATA Mathematical Systems Inc. 12 過学習とは 学習データには適合するが、未知データに適合しない状況 複雑なモデルほど、より多くの学習データを必要とする モデルの表現力と過学習 表現力 低 (単純) 高 (複雑) 線形モデルなど ディープニューラルネットなど より優れたモデルの可能性を秘めて いるが、過学習しやすくなる (対策) • うまい正則化 (Dropout など) • 大量のデータで学習
13.
13© 2017 NTT
DATA Mathematical Systems Inc. 13 カーネルSVM カーネルトリックを用いて線形モデルな SVM を非線形分類可能に 低バリアンスで汎化性能高め (過学習を抑えやすい) ランダムフォレスト メジャーでお手軽 分散させやすい 勾配ブースティング いわゆる XGBoost Kaggle などでデファクトになった強力な分類器 チューニングコスト低め その他の非線形分類器たち
14.
14© 2017 NTT
DATA Mathematical Systems Inc. 14 大量のデータを活かせる モデルの表現力が高く過学習しやすい一方 大量のデータがあれば活かせる 特徴量の自動獲得 画像, 音声, テキストといった生モノに強い ex. Googleの猫 (猫に反応するニューロン) ディープラーニングの強み https://googleblog.blogspot.jp/2012/06/using -large-scale-brain-simulations-for.html https://www.slideshare.net/ExtractConf/a ndrew-ng-chief-scientist-at-baidu/30 http://www.deeplearningbook.org/contents /intro.html
15.
15© 2017 NTT
DATA Mathematical Systems Inc. 15 過学習しやすい 大量の学習データが必要 機械学習しようとするときにいつも悩む 膨大な計算機リソースが必要 チューニングが難しい 特徴量を自動獲得する反面、ブラックボックスでもあり 人間が持っている知識を組み込みづらい ディープラーニングの代償
16.
16© 2017 NTT
DATA Mathematical Systems Inc. 16 イントロ ディープラーニングとは ディープラーニングの特徴 ディープラーニングの構成要素 ディープラーニングのチューニング技法 ディープラーニングを用いた画像処理 ディープラーニングを用いた自然言語処理 ディープラーニングを用いたマルチモーダル学習 内容
17.
17© 2017 NTT
DATA Mathematical Systems Inc. 17 モデル ニューラルネットワークモデル (ネットワーク構造, 層数, 活性化関数) 損失関数 (モデルの予測結果が、正解にどれだけ近いかを示すもの) 学習 (確率的勾配降下法) 学習率 ミニバッチサイズ Optimizer ディープラーニングの構成要素
18.
18© 2017 NTT
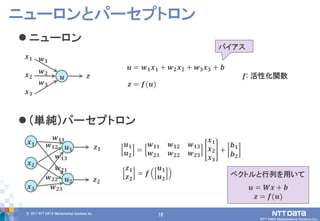
DATA Mathematical Systems Inc. 18 ニューロン (単純)パーセプトロン ニューロンとパーセプトロン 𝒙 𝟏 𝒙 𝟐 𝒙 𝟑 𝒛 𝒘 𝟏 𝒘 𝟐 𝒘 𝟑 𝒛 = 𝒇(𝒖) 𝒇: 活性化関数 𝒙 𝟏 𝒙 𝟐 𝒙 𝟑 𝒖 𝟏 𝒖 𝟐 𝒘 𝟏𝟏 𝒘 𝟏𝟐 𝒘 𝟏𝟑 𝒘 𝟐𝟏 𝒘 𝟐𝟐 𝒘 𝟐𝟑 𝒛 𝟏 𝒛 𝟐 = 𝒇 𝒖 𝟏 𝒖 𝟐 𝒖 𝟏 𝒖 𝟐 = 𝒘 𝟏𝟏 𝒘 𝟏𝟐 𝒘 𝟏𝟑 𝒘 𝟐𝟏 𝒘 𝟐𝟐 𝒘 𝟐𝟑 𝒙 𝟏 𝒙 𝟐 𝒙 𝟑 + 𝒃 𝟏 𝒃 𝟐 𝒛 𝟏 𝒛 𝟐 𝒖 𝒖 = 𝒘 𝟏 𝒙 𝟏 + 𝒘 𝟐 𝒙 𝟐 + 𝒘 𝟑 𝒙 𝟑 + 𝒃 バイアス ベクトルと行列を用いて 𝒖 = 𝑾𝒙 + 𝒃 𝒛 = 𝒇(𝒖)
19.
19© 2017 NTT
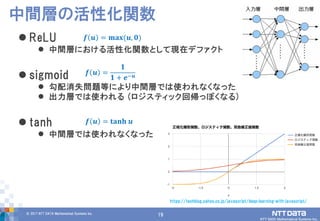
DATA Mathematical Systems Inc. 19 ReLU 中間層における活性化関数として現在デファクト sigmoid 勾配消失問題等により中間層では使われなくなった 出力層では使われる (ロジスティック回帰っぽくなる) tanh 中間層では使われなくなった 中間層の活性化関数 𝒇 𝒖 = 𝐦𝐚𝐱(𝒖, 𝟎) 𝒇 𝒖 = 𝟏 𝟏 + 𝒆−𝒖 https://techblog.yahoo.co.jp/javascript/deep-learning-with-javascript/ 𝒇 𝒖 = 𝐭𝐚𝐧𝐡 𝒖
20.
20© 2017 NTT
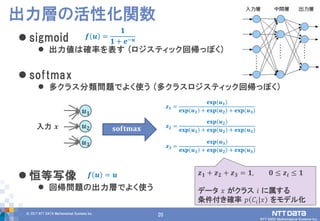
DATA Mathematical Systems Inc. 20 sigmoid 出力値は確率を表す (ロジスティック回帰っぽく) softmax 多クラス分類問題でよく使う (多クラスロジスティック回帰っぽく) 恒等写像 回帰問題の出力層でよく使う 出力層の活性化関数 𝒇 𝒖 = 𝟏 𝟏 + 𝒆−𝒖 𝒇 𝒖 = 𝒖 𝒖 𝟏 𝒖 𝟐 𝒖 𝟑 𝒛 𝟏 = 𝐞𝐱𝐩 𝒖 𝟏 𝐞𝐱𝐩 𝒖 𝟏 + 𝐞𝐱𝐩 𝒖 𝟐 + 𝐞𝐱𝐩(𝒖 𝟑) 𝐬𝐨𝐟𝐭𝐦𝐚𝐱 𝒛 𝟐 = 𝐞𝐱𝐩 𝒖 𝟐 𝐞𝐱𝐩 𝒖 𝟏 + 𝐞𝐱𝐩 𝒖 𝟐 + 𝐞𝐱𝐩(𝒖 𝟑) 𝒛 𝟑 = 𝐞𝐱𝐩 𝒖 𝟑 𝐞𝐱𝐩 𝒖 𝟏 + 𝐞𝐱𝐩 𝒖 𝟐 + 𝐞𝐱𝐩(𝒖 𝟑) 𝒛 𝟏 + 𝒛 𝟐 + 𝒛 𝟑 = 𝟏, 𝟎 ≤ 𝒛𝒊 ≤ 𝟏 データ 𝑥 がクラス 𝑖 に属する 条件付き確率 𝑝 𝐶𝑖|𝑥 をモデル化 入力 𝒙
21.
21© 2017 NTT
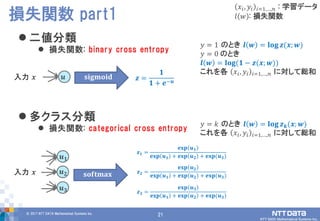
DATA Mathematical Systems Inc. 21 二値分類 損失関数: binary cross entropy 多クラス分類 損失関数: categorical cross entropy 損失関数 part1 𝒖 𝐬𝐢𝐠𝐦𝐨𝐢𝐝 𝒛 = 𝟏 𝟏 + 𝒆−𝒖 𝒖 𝟏 𝒖 𝟐 𝒖 𝟑 𝒛 𝟏 = 𝐞𝐱𝐩 𝒖 𝟏 𝐞𝐱𝐩 𝒖 𝟏 + 𝐞𝐱𝐩 𝒖 𝟐 + 𝐞𝐱𝐩(𝒖 𝟑) 𝐬𝐨𝐟𝐭𝐦𝐚𝐱 𝒛 𝟐 = 𝐞𝐱𝐩 𝒖 𝟐 𝐞𝐱𝐩 𝒖 𝟏 + 𝐞𝐱𝐩 𝒖 𝟐 + 𝐞𝐱𝐩(𝒖 𝟑) 𝒛 𝟑 = 𝐞𝐱𝐩 𝒖 𝟑 𝐞𝐱𝐩 𝒖 𝟏 + 𝐞𝐱𝐩 𝒖 𝟐 + 𝐞𝐱𝐩(𝒖 𝟑) 入力 𝒙 入力 𝒙 𝑥𝑖, 𝑦𝑖 𝑖=1,…,𝑛 : 学習データ 𝑙 𝑤 : 損失関数 𝑦 = 1 のとき 𝒍 𝒘 = 𝐥𝐨𝐠 𝒛(𝒙; 𝒘) 𝑦 = 0 のとき 𝒍 𝒘 = 𝐥𝐨𝐠(𝟏 − 𝒛(𝒙; 𝒘)) これを各 𝑥𝑖, 𝑦𝑖 𝑖=1,…,𝑛 に対して総和 𝑦 = 𝑘 のとき 𝒍 𝒘 = 𝐥𝐨𝐠 𝒛 𝒌(𝒙; 𝒘) これを各 𝑥𝑖, 𝑦𝑖 𝑖=1,…,𝑛 に対して総和
22.
22© 2017 NTT
DATA Mathematical Systems Inc. 22 回帰 損失関数: 二乗誤差 損失関数 part2 𝒖 活性化 𝒛入力 𝒙 𝑥𝑖, 𝑦𝑖 𝑖=1,…,𝑛 : 学習データ 𝑙 𝑤 : 損失関数 𝒍 𝒘 = (𝒚 − 𝒛(𝒙; 𝒘)) 𝟐 これを各 𝑥𝑖, 𝑦𝑖 𝑖=1,…,𝑛 に対して総和
23.
23© 2017 NTT
DATA Mathematical Systems Inc. 23 モデル ニューラルネットワークモデル (ネットワーク構造, 層数, 活性化関数) 損失関数 (モデルの予測結果が、正解にどれだけ近いかを示すもの 学習 (確率的勾配降下法) 学習率 ミニバッチサイズ Optimizer ディープラーニングの構成要素 (再掲)
24.
24© 2017 NTT
DATA Mathematical Systems Inc. 24 損失関数は例えば回帰問題では 勾配降下法: 関数の最小値を求める一般的なテク 勾配降下法 𝑥𝑖, 𝑦𝑖 𝑖=1,…,𝑛 : 学習データ 𝑙𝑖 𝑤 : 損失関数 𝐌𝐢𝐧𝐢𝐦𝐢𝐳𝐞 𝒘: 𝑳 𝒘 = 𝒍𝒊(𝒘) 𝒏 𝒊=𝟏 = 𝒚𝒊 − 𝒛𝒊 𝒙; 𝒘 𝟐 𝒏 𝒊=𝟏 • 初期値 𝒘 𝟎 を用意 • 更新式 𝒘 𝒕+𝟏 = 𝒘 𝒕 − 𝝐 𝛁𝑳(𝒘 𝒕 ) に従って 重みを更新していく 学習率
25.
25© 2017 NTT
DATA Mathematical Systems Inc. 25 勾配降下法の更新式を書き直すと 確率的勾配降下法 毎回 𝑛 個のデータのうちの 𝐾 個をサンプリング (𝑖1, 𝑖2, … , 𝑖 𝐾) 望まない局所極小解から抜け出せなくなるリスクを軽減 学習途中でデータを追加できる 確率的勾配降下法 (SGD) 𝒘 𝒕+𝟏 = 𝒘 𝒕 − 𝝐 𝜵𝒍𝒊(𝒘) 𝒏 𝒊=𝟏 𝑥𝑖, 𝑦𝑖 𝑖=1,…,𝑛 : 学習データ 𝑙𝑖 𝑤 : 損失関数 1回の更新で 𝑛 個の全データ必要 ミニバッチサイズ 𝒘 𝒕+𝟏 = 𝒘 𝒕 − 𝝐 𝜵𝒍𝒊 𝒌 (𝒘) 𝑲 𝒌=𝟏 1回の更新では 𝑛 個のデータのうち、 𝑘 個のみを使用
26.
26© 2017 NTT
DATA Mathematical Systems Inc. 26 学習率 小さすぎると学習に時間がかかる 大きすぎると loss が下がりにくくなる ミニバッチサイズ 10~100程度とすることが多い 多クラス分類問題の場合、クラス数より多くしたい ただし、クラス数が多すぎる場合は10~100程度に Optimizer: SGDの亜種たち AdaGrad AdaDelta Adam RMSprop チューニングパラメータ 𝒘 𝒕+𝟏 = 𝒘 𝒕 − 𝝐 𝜵𝒍𝒊 𝒌 (𝒘) 𝑲 𝒌=𝟏 ミニバッチサイズ 学習率
27.
27© 2017 NTT
DATA Mathematical Systems Inc. 27 イントロ ディープラーニングとは ディープラーニングの特徴 ディープラーニングの構成要素 ディープラーニングのチューニング技法 ディープラーニングを用いた画像処理 ディープラーニングを用いた自然言語処理 ディープラーニングを用いたマルチモーダル学習 内容
28.
28© 2017 NTT
DATA Mathematical Systems Inc. 28 データを分割 (7 : 3 くらいに) 学習用データ: モデルの学習 テスト用データ: 実際にうまく分類できるかなどの評価 ハイパーパラメータチューニング テスト用データに対する精度が最も高くなるようにパラメータ調整した くなる (反則!!!) チューニングのために validation データを確保することも 学習データ Validationデータ テストデータ データの扱い
29.
29© 2017 NTT
DATA Mathematical Systems Inc. 29 2 つの誤差 経験損失: 学習データに対する推論の正解とのズレ 期待損失: 未知のデータに対する推論の正解とのズレ (の期待値) 経験損失を小さくする ことで期待損失を小さくしたい 期待損失は実際は計算できないので、テスト誤差を近 似的に期待損失と考える 機械学習の目的: 期待損失の最小化 過学習とは、経験損失は小さいが 期待損失が大きい状態
30.
30© 2017 NTT
DATA Mathematical Systems Inc. 30 上手くいっていない状況を把握 Underfit? / Overfit? / そもそもデータの限界? 学習データに対してもダメなとき とにかくまずは過学習させちゃう! Optimizer, 学習率, ミニバッチサイズ, モデルをより複雑に 学習データに対してはOKでテストデータはダメなとき 正則化 学習データの増やし方 モデルそのものの改善 モデル規模の適性化 ディープラーニングのチューニング
31.
31© 2017 NTT
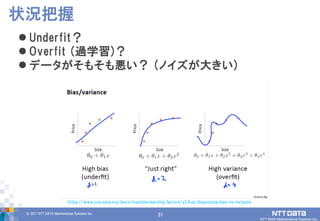
DATA Mathematical Systems Inc. 31 Underfit? Overfit (過学習)? データがそもそも悪い? (ノイズが大きい) 状況把握 https://www.coursera.org/learn/machine-learning/lecture/yCAup/diagnosing-bias-vs-variance
32.
32© 2017 NTT
DATA Mathematical Systems Inc. 32 学習データに対してフィットしないと何も始まらない この状況で学習データ増やしても改善しない 過学習させてでもフィットさせよう! 学習率の調整!!! Optimizers を変えてみる モデルをもっと複雑にしてみる ミニバッチサイズを変えてみる Underfit 経験損失 (学習データとのズレ) が小さくなっていない 学習データに対しても正しく推定できない
33.
33© 2017 NTT
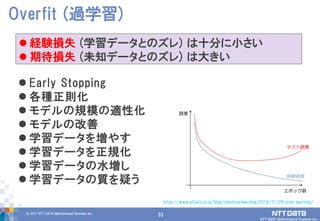
DATA Mathematical Systems Inc. 33 Early Stopping 各種正則化 モデルの規模の適性化 モデルの改善 学習データを増やす 学習データを正規化 学習データの水増し 学習データの質を疑う Overfit (過学習) 経験損失 (学習データとのズレ) は十分に小さい 期待損失 (未知データとのズレ) は大きい https://www.altus5.co.jp/blog/machine-learning/2016/11/28/over-learning/
34.
34© 2017 NTT
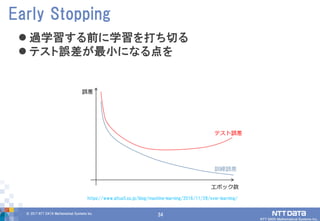
DATA Mathematical Systems Inc. 34 過学習する前に学習を打ち切る テスト誤差が最小になる点を Early Stopping https://www.altus5.co.jp/blog/machine-learning/2016/11/28/over-learning/
35.
35© 2017 NTT
DATA Mathematical Systems Inc. 35 重みの L2 / L1 正則化 Dropout Batch Normalization 2015年あたりに提案された強力な正規化層 各種正則化 model = Sequential() model.add( Conv2D(32, kernel_size = (3, 3), activation = ‘relu’, input_shape = input_shape) ) model.add( MaxPooling2D(pool_size = (2, 2)) ) model.add( Dropout(0.25) ) model.add( Flatten() ) model.add( Dense(128, activation = ‘relu’, W_regularizer = l2(0.0001)) ) model.add( Dense(num_classes, activation = ‘softmax’) ) Keras での例
36.
36© 2017 NTT
DATA Mathematical Systems Inc. 36 モデルをシンプルにする 層数を減らすなど モデル圧縮技術 一度あるモデルで学習したあと、ネットワークの削ってもいい箇所を見 出し、削ったネットワークを用いて再学習 ネットワークが小さくなるだけでなく精度も上がったり モデルの規模の適性化
37.
37© 2017 NTT
DATA Mathematical Systems Inc. 37 現在最先端の研究でしのぎを削っている 「よりよい ネットワークを考えました」 選手権そのもの より性能がよいと知られているモデルを使う ResNet より性能が出ると知られている機構を取り入れる Attention Bi-directional LSTM Batch Normalization Pointer Networks モデルの改善
38.
38© 2017 NTT
DATA Mathematical Systems Inc. 38 単純に精度が上がることが期待できる とはいえ... 学習データを新たに収集するのは大きな負担 モデルの改善や、学習データの水増しなどの方が重要 であることも多い 学習データを増やす
39.
39© 2017 NTT
DATA Mathematical Systems Inc. 39 画像での例 入力セルの値の平均が0、分散が1になるように テキストでの例 固有名詞など、低頻出単語は unk などのマクロ置換 文中の数値などは num などのマクロ置換する 顔文字などノイズは削る、()などの記号の書式を統一 学習データの正規化 けんちょんは(精神年齢)17歳なの~~ん(⋈◍>◡<◍)。✧♡ unkは(精神年齢)num歳なのーん
40.
40© 2017 NTT
DATA Mathematical Systems Inc. 40 画像にノイズを加えたものを新たなデータに 画像を少し変形をしたものを新たなデータに 左右反転 平行移動 拡大縮小 回転 濃淡を変える 色を少し変える GAN などで生成した画像を新たなデータに 進行中の研究課題 学習データの水増し (画像編)
41.
41© 2017 NTT
DATA Mathematical Systems Inc. 41 同じ意味の似た言い回しの文を新たに作る 文章要約タスクでは、(元文章, 要約文) のペアに対し て (要約文, 要約文) のペアを新たなデータに 学習データの水増し (テキスト編) 何歳ですか? / 17歳です 何歳なの? / 17歳です 何歳? / 17歳です 何歳でしょうか? / 17歳です
42.
42© 2017 NTT
DATA Mathematical Systems Inc. 42 特に人手で頑張って作ったデータでは誤りも多くある データに偏りがある場合も多い 場合によってはノイズの大きいデータは省いたり、デー タの正規化を頑張ったりする 学習データの質を疑う
43.
43© 2017 NTT
DATA Mathematical Systems Inc. 43 イントロ ディープラーニングとは ディープラーニングの特徴 ディープラーニングの構成要素 ディープラーニングのチューニング技法 ディープラーニングを用いた画像処理 ディープラーニングを用いた自然言語処理 ディープラーニングを用いたマルチモーダル学習 内容
44.
44© 2017 NTT
DATA Mathematical Systems Inc. 44 画像処理: CNN (Convolutional Neural Networks) 自然言語処理: RNN (Recurrent Neural Networks) マルチモーダル: これらを組み合わせたり 定番手法
45.
45© 2017 NTT
DATA Mathematical Systems Inc. 45 イントロ ディープラーニングとは ディープラーニングの特徴 ディープラーニングの構成要素 ディープラーニングのチューニング技法 ディープラーニングを用いた画像処理 ディープラーニングを用いた自然言語処理 ディープラーニングを用いたマルチモーダル学習 内容
46.
46© 2017 NTT
DATA Mathematical Systems Inc. 46 1958年、猫の視覚野に特定の傾きをもつ線分を見せ たときにだけ反応する細胞の発見 (単純型細胞) 単純型細胞で検知した情報を取りまとめて、線分の位 置がずれたりしたものも検出 (複雑型細胞) さらにこれらの細胞が多層に なって複雑なパターン検出 この階層仮説がヒントに なって CNN が誕生! Hubel--Wiesel の階層仮説 瀧雅人「これならわかる深層学習入門」より 単純型 複雑型
47.
47© 2017 NTT
DATA Mathematical Systems Inc. 47 1958年: Hubel--Wiesel の階層仮説 1979年: Fukushima のネオコグニトロン 単純型細胞と複雑型細胞に対応したユニットを導入 1989年: LeCun らの CNN 現在の CNN とほとんど同じもの CNN に誤差逆伝播法を適応して高い性能を実現! 2012年: Hinton らが CNN を用いてコンペ優勝 画像認識コンペ ILSVRC Convolutional Neural Networks の歴史
48.
48© 2017 NTT
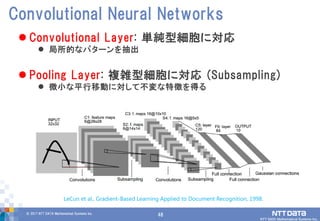
DATA Mathematical Systems Inc. 48 Convolutional Layer: 単純型細胞に対応 局所的なパターンを抽出 Pooling Layer: 複雑型細胞に対応 (Subsampling) 微小な平行移動に対して不変な特徴を得る Convolutional Neural Networks LeCun et al., Gradient-Based Learning Applied to Document Recognition, 1998.
49.
49© 2017 NTT
DATA Mathematical Systems Inc. 49 Keras での例 model = Sequential() model.add( Conv2D(6, kernel_size = (5, 5), activation = ‘relu’, input_shape = (1, 32, 32)) ) model.add( MaxPooling2D(pool_size = (2, 2)) ) model.add( Conv2D(16, kernel_size = (5, 5), activation = ‘relu’) ) model.add( MaxPooling2D(pool_size = (2, 2)) ) model.add( Dropout(0.25) ) model.add( Flatten() ) model.add( Dense(120, activation = ‘relu’)) ) model.add( Dense(84, activation = ‘relu’)) ) model.add( Dropout(0.5) ) model.add( Dense(10, activation = ‘softmax’) ) LeCun et al., Gradient-Based Learning Applied to Document Recognition, 1998.
50.
50© 2017 NTT
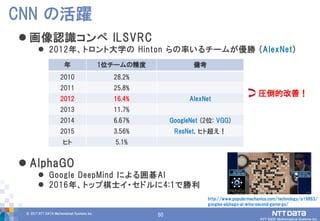
DATA Mathematical Systems Inc. 50 画像認識コンペ ILSVRC 2012年、トロント大学の Hinton らの率いるチームが優勝 (AlexNet) AlphaGO Google DeepMind による囲碁AI 2016年、トップ棋士イ・セドルに4:1で勝利 CNN の活躍 圧倒的改善! 年 1位チームの精度 備考 2010 28.2% 2011 25.8% 2012 16.4% AlexNet 2013 11.7% 2014 6.67% GoogleNet (2位: VGG) 2015 3.56% ResNet, ヒト超え! ヒト 5.1% http://www.popularmechanics.com/technology/a19863/ googles-alphago-ai-wins-second-game-go/
51.
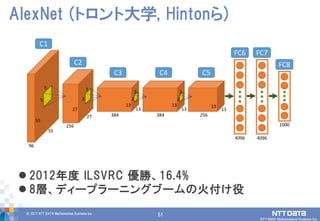
51© 2017 NTT
DATA Mathematical Systems Inc. 51 2012年度 ILSVRC 優勝、16.4% 8層、ディープラーニングブームの火付け役 AlexNet (トロント大学, Hintonら)
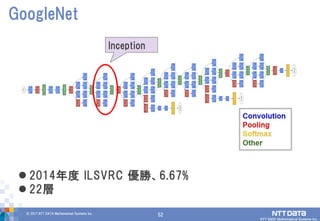
52.
52© 2017 NTT
DATA Mathematical Systems Inc. 52 2014年度 ILSVRC 優勝、6.67% 22層 GoogleNet Inception
53.
53© 2017 NTT
DATA Mathematical Systems Inc. 53 2014年度 ILSVRC 準優勝、7.32% 19層 VGG (オックスフォード大)
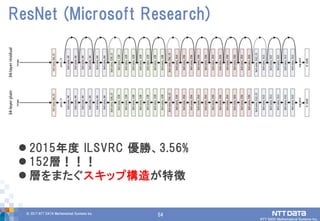
54.
54© 2017 NTT
DATA Mathematical Systems Inc. 54 2015年度 ILSVRC 優勝、3.56% 152層!!! 層をまたぐスキップ構造が特徴 ResNet (Microsoft Research)
55.
55© 2017 NTT
DATA Mathematical Systems Inc. 55 物体認識 (ここまで) 画像が表すものは何か 物体検出 画像から物体の位置も特定 セグメンテーション 画像のピクセルごとにどのクラスに属するかを出力 最近は... 画像生成、画像ドメイン変換 GAN の爆発的流行 画像処理タスク
56.
56© 2017 NTT
DATA Mathematical Systems Inc. 56 物体認識 Krizhevsky et al., ImageNet Classification with Deep Convolutional Neural Networks, 2012.
57.
57© 2017 NTT
DATA Mathematical Systems Inc. 57 物体検出 He et al., Mask R-CNN, 2017. 画像から物体の位置も特定
58.
58© 2017 NTT
DATA Mathematical Systems Inc. 58 テキスト検出 Wang et al., End-to-End Text Recognition with Convolutional Neural Networks, 2012. Alsharif and Pineau., End-to-End Text Recognition with Hybrid HMM Maxout Models, 2013.
59.
59© 2017 NTT
DATA Mathematical Systems Inc. 59 セグメンテーション Badrinarayanan et al., SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling, 2015. 画像のピクセルごとにどのクラスに属するかを出力
60.
60© 2017 NTT
DATA Mathematical Systems Inc. 60 2014年、GAN (Goodfellow et al., Generative Adversarial Networks) が発表されて以来爆発的流行 Generator と Discriminator を戦わせて学習 本物と見分けられない偽札作りと、取締り警察との戦いに例えられる 画像生成 Radford et al., Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015. DCGAN による画像生成
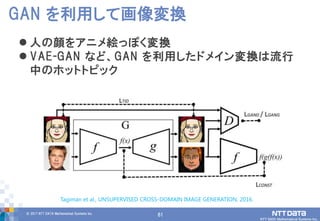
61.
61© 2017 NTT
DATA Mathematical Systems Inc. 61 GAN を利用して画像変換 人の顔をアニメ絵っぽく変換 VAE-GAN など、GAN を利用したドメイン変換は流行 中のホットトピック Tagiman et al., UNSUPERVISED CROSS-DOMAIN IMAGE GENERATION, 2016.
62.
62© 2017 NTT
DATA Mathematical Systems Inc. 62 CycleGAN 「馬をシマウマに、シマウマを馬に」 といった変換 Zhu et al., Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
63.
63© 2017 NTT
DATA Mathematical Systems Inc. 63 pix2pix ピクセルごとに画像変換する GAN 一世を風靡した PaintsChainer は少し改変したもの Isola et al., Image-to-Image Translation with Conditional Adversarial Networks, 2016. Paint Chainer (https://qiita.com/taizan/items/cf77fd37ec3a0bef5d9d)
64.
64© 2017 NTT
DATA Mathematical Systems Inc. 64 超高解像度な画像生成 そして2017年、高解像度な画像生成が飛躍的進化 画像ラベルマップから高解像度の画像合成!!! Wang et al., High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs, 2017.
65.
65© 2017 NTT
DATA Mathematical Systems Inc. 65 イントロ ディープラーニングとは ディープラーニングの特徴 ディープラーニングの構成要素 ディープラーニングのチューニング技法 ディープラーニングを用いた画像処理 ディープラーニングを用いた自然言語処理 ディープラーニングを用いたマルチモーダル学習 内容
66.
66© 2017 NTT
DATA Mathematical Systems Inc. 66 長さ 𝑇 の時系列データ 𝑥1, 𝑥2, … , 𝑥 𝑇 を扱う 代表例はテキスト This is an apple. 𝑥1 = “This”, 𝑥2 = “is”, 𝑥3 = “an”, 𝑥4 = “apple 文脈をとらえたい This is an と来たら、次は形容詞か名詞 RNN (Recurrent Neural Networks) がよく使われる CNN を使うこともある テキストは系列データ
67.
67© 2017 NTT
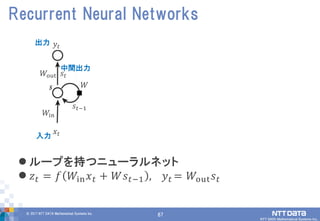
DATA Mathematical Systems Inc. 67 ループを持つニューラルネット 𝑧 𝑡 = 𝑓 𝑊in 𝑥 𝑡 + 𝑊𝑠 𝑡−1 , 𝑦 𝑡 = 𝑊out 𝑠 𝑡 Recurrent Neural Networks 𝑊in 𝑥𝑡 𝑦𝑡 𝑠𝑡−1 出力 入力 中間出力 𝑠𝑡 𝑊 𝑊out
68.
68© 2017 NTT
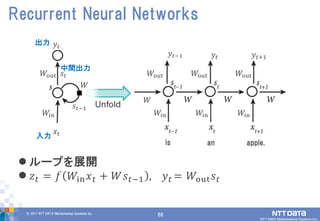
DATA Mathematical Systems Inc. 68 ループを展開 𝑧 𝑡 = 𝑓 𝑊in 𝑥 𝑡 + 𝑊𝑠 𝑡−1 , 𝑦 𝑡 = 𝑊out 𝑠 𝑡 Recurrent Neural Networks 𝑊in 𝑊in 𝑊in 𝑦𝑡−1 𝑦𝑡 𝑦𝑡+1 𝑊in 𝑥𝑡 𝑦𝑡 𝑠𝑡−1 出力 入力 中間出力 𝑠𝑡 𝑊 𝑊out 𝑊out𝑊out𝑊out 𝑊 is an apple.
69.
69© 2017 NTT
DATA Mathematical Systems Inc. 69 RNN の大きな弱点 文章が長いと、最初の方のことを忘れたり、最初の方のことの情報が 強すぎて後の方のことが頭に入ってこなかったり 改良された亜種たち LSTM (Long Short-Term Memory) GRU (Gated Recurrent Unit) RNN の亜種たち
70.
70© 2017 NTT
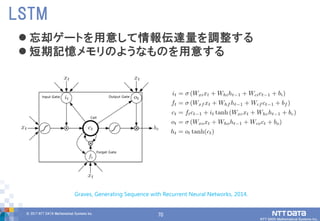
DATA Mathematical Systems Inc. 70 忘却ゲートを用意して情報伝達量を調整する 短期記憶メモリのようなものを用意する LSTM Graves, Generating Sequence with Recurrent Neural Networks, 2014.
71.
71© 2017 NTT
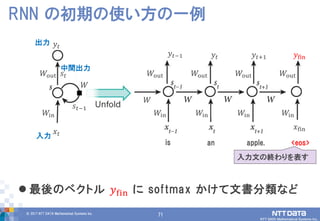
DATA Mathematical Systems Inc. 71 最後のベクトル 𝑦fin に softmax かけて文書分類など RNN の初期の使い方の一例 𝑊in 𝑊in 𝑊in 𝑦𝑡−1 𝑦𝑡 𝑦𝑡+1 𝑊in 𝑥𝑡 𝑦𝑡 𝑠𝑡−1 出力 入力 中間出力 𝑠𝑡 𝑊 𝑊out 𝑊out𝑊out𝑊out 𝑊 is an 𝑦fin 𝑥fin 𝑊in 𝑊out apple. <eos> 入力文の終わりを表す
72.
72© 2017 NTT
DATA Mathematical Systems Inc. 72 記事のトピック分類など {政治, 技術, 国内} の 3 クラス分類を判別 Keras での例 EMBEDDING_DIM = 256 # 埋め込みベクトルサイズ MAX_LENGTH = 100 # 入力される文章の長さ (の最大値) NUM_VOCAB = 1000 # 語彙数 # 2 層の GRU model = Sequential() model.add( Embedding(NUM_VOCAB, EMBEDDING_DIM, input_shape = (MAX_LENGTH,)) ) model.add( GRU(EMBEDDING_DIM, return_sequences = True) ) # y_1, y_2, ..., y_fin を次の層へ model.add( GRU(EMBEDDING_DIM, return_sequences = False) ) # y_fin のみを取り出す model.add( Dropout(0.25) ) model.add( Dense(3, activation = ‘softmax’) )
73.
73© 2017 NTT
DATA Mathematical Systems Inc. 73 文章の特徴抽出 履歴情報を用いたレコメンデーション 音声認識 古くから深層学習が成功していた分野で、RNN が基盤技術として用いら れることも多いです 曲生成、演奏 最新の Deep Voice 3 については CNN ベース 文章生成 言語モデル構築から小説生成まで 参考記事: http://karpathy.github.io/2015/05/21/rnn-effectiveness/ お絵描き、演奏 Sketch RNN https://experiments.withgoogle.com/ai/sketch-rnn-demo Performance RNN https://magenta.tensorflow.org/performance-rnn その他の RNN の使い道
74.
74© 2017 NTT
DATA Mathematical Systems Inc. 74 分類だけでない!系列データから系列データへの学習 さらに踏み込んで 「なんらかのデータをベクトルに埋め込んだもの」 か ら系列データへの学習も (マルチモーダルへの道) 機械翻訳 (日本語から英語へ) 対話 (言われたことから発話へ) 文章要約 (オリジナル文から要約文へ) Question Answering (質問文から応答文へ) 画像キャプション生成 (画像から画像キャプションへ) Visual Question Answering (画像を見て応答) 人間の話し言葉を理解して対話 さらなる RNN の現代的な使い方
75.
75© 2017 NTT
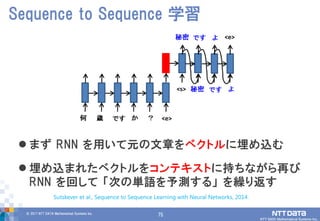
DATA Mathematical Systems Inc. 75 まず RNN を用いて元の文章をベクトルに埋め込む 埋め込まれたベクトルをコンテキストに持ちながら再び RNN を回して 「次の単語を予測する」 を繰り返す Sequence to Sequence 学習 Sutskever et al., Sequence to Sequence Learning with Neural Networks, 2014.
76.
76© 2017 NTT
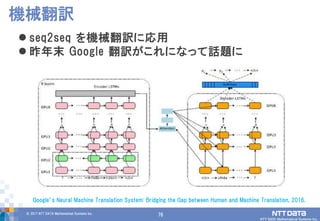
DATA Mathematical Systems Inc. 76 seq2seq を機械翻訳に応用 昨年末 Google 翻訳がこれになって話題に 機械翻訳 Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, 2016.
77.
77© 2017 NTT
DATA Mathematical Systems Inc. 77 seq2seq を対話に応用 Microsoft の女子高生AI りんななども 対話 Vinyals et al., A Neural Conversational Model, 2015. http://www.itmedia.co.jp/mobile/articles/1606/12/news005.html
78.
78© 2017 NTT
DATA Mathematical Systems Inc. 78 seq2seq を文章要約に応用 機械翻訳が成熟し始めた今、かなりのホットトピック 文章要約 Nallapati et al., Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond, 2015.
79.
79© 2017 NTT
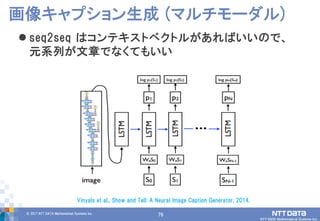
DATA Mathematical Systems Inc. 79 seq2seq はコンテキストベクトルがあればいいので、 元系列が文章でなくてもいい 画像キャプション生成 (マルチモーダル) Vinyals et al., Show and Tell: A Neural Image Caption Generator, 2014.
80.
80© 2017 NTT
DATA Mathematical Systems Inc. 80 画像キャプション生成 (マルチモーダル) Vinyals et al., Show and Tell: A Neural Image Caption Generator, 2014.
81.
81© 2017 NTT
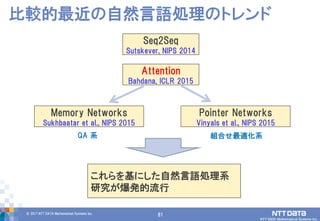
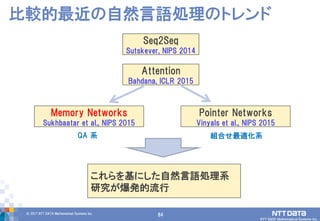
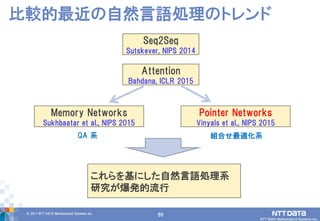
DATA Mathematical Systems Inc. 81 比較的最近の自然言語処理のトレンド Attention Bahdana, ICLR 2015 Memory Networks Sukhbaatar et al., NIPS 2015 Pointer Networks Vinyals et al., NIPS 2015 QA 系 組合せ最適化系 これらを基にした自然言語処理系 研究が爆発的流行 Seq2Seq Sutskever, NIPS 2014
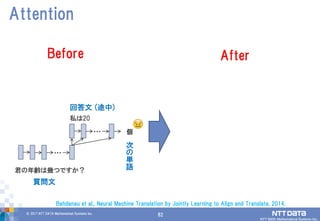
82.
82© 2017 NTT
DATA Mathematical Systems Inc. 82 Attention … 質問文 Before … 回答文 (途中) 次 の 単 語 個 私は20 君の年齢は幾つですか? After Bahdanau et al., Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
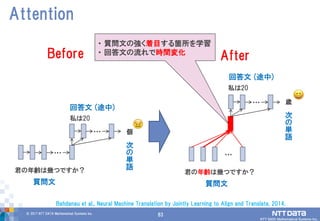
83.
83© 2017 NTT
DATA Mathematical Systems Inc. 83 Attention … 質問文 Before … 回答文 (途中) 次 の 単 語 個 私は20 君の年齢は幾つですか? … After … 回答文 (途中) 次 の 単 語 歳 私は20 質問文 君の年齢は幾つですか? Bahdanau et al., Neural Machine Translation by Jointly Learning to Align and Translate, 2014. ・ 質問文の強く着目する箇所を学習 ・ 回答文の流れで時間変化
84.
84© 2017 NTT
DATA Mathematical Systems Inc. 84 比較的最近の自然言語処理のトレンド Attention Bahdana, ICLR 2015 Memory Networks Sukhbaatar et al., NIPS 2015 Pointer Networks Vinyals et al., NIPS 2015 QA 系 組合せ最適化系 これらを基にした自然言語処理系 研究が爆発的流行 Seq2Seq Sutskever, NIPS 2014
85.
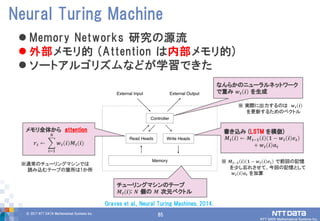
85© 2017 NTT
DATA Mathematical Systems Inc. 85 Memory Networks 研究の源流 外部メモリ的 (Attention は内部メモリ的) ソートアルゴリズムなどが学習できた Neural Turing Machine メモリ全体から attention 𝒓 𝒕 ← 𝒘 𝒕 𝒊 𝑴𝒕(𝒊) 𝑵 𝒊=𝟏 チューリングマシンのテープ 𝑴 𝒕(𝒊): 𝑵 個の 𝑴 次元ベクトル ※通常のチューリングマシンでは 読み込むテープの箇所は1か所 なんらかのニューラルネットワーク で重み 𝒘 𝒕 𝒊 を生成 書き込み (LSTM を模倣) 𝑴 𝒕 𝒊 ← 𝑴 𝒕−𝟏 𝒊 𝟏 − 𝒘 𝒕 𝒊 𝒆 𝒕 + 𝒘 𝒕 𝒊 𝒂 𝒕 ※ 𝑴𝒕−𝟏 𝒊 𝟏 − 𝒘 𝒕 𝒊 𝒆 𝒕 で前回の記憶 を少し忘れさせて、今回の記憶として 𝒘 𝒕 𝒊 𝒂 𝒕 を加算 ※ 実際に出力するのは 𝒘 𝒕 𝒊 を更新するためのベクトル Graves et al., Neural Turing Machines, 2014.
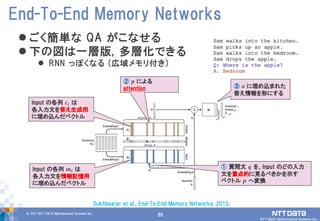
86.
86© 2017 NTT
DATA Mathematical Systems Inc. 86 ごく簡単な QA がこなせる 下の図は一層版, 多層化できる RNN っぽくなる (広域メモリ付き) End-To-End Memory Networks Sukhbaatar et al., End-To-End Memory Networks, 2015. Input の各列 𝒎𝒊 は 各入力文を情報記憶用 に埋め込んだベクトル ① 質問文 𝒒 を、Input のどの入力 文を重点的に見るべきかを示す ベクトル 𝒑 へ変換 Input の各列 𝒄𝒊 は 各入力文を答え生成用 に埋め込んだベクトル ② 𝒑 による attention ③ 𝒐 に埋め込まれた 答え情報を形にする
87.
87© 2017 NTT
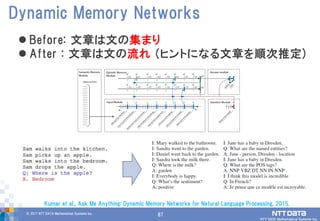
DATA Mathematical Systems Inc. 87 Before: 文章は文の集まり After : 文章は文の流れ (ヒントになる文章を順次推定) Dynamic Memory Networks Kumar et al., Ask Me Anything: Dynamic Memory Networks for Natural Language Processing, 2015.
88.
88© 2017 NTT
DATA Mathematical Systems Inc. 88 今までの Attention: 一方向 「質問文」 を読んで、「文章」 のどこが大事か 進化した Co-Attention: 双方向 「質問文」 を読んで、「文章」 のどこが大事か 「文章」 を読みながら、「質問文」 の聞き所を掴む Dynamic Coattention Networks Xiong et al., Ask Me Anything: Dynamic Memory Networks for Natural Language Processing, 2016.
89.
89© 2017 NTT
DATA Mathematical Systems Inc. 89 比較的最近の自然言語処理のトレンド Attention Bahdana, ICLR 2015 Memory Networks Sukhbaatar et al., NIPS 2015 Pointer Networks Vinyals et al., NIPS 2015 QA 系 組合せ最適化系 これらを基にした自然言語処理系 研究が爆発的流行 Seq2Seq Sutskever, NIPS 2014
90.
90© 2017 NTT
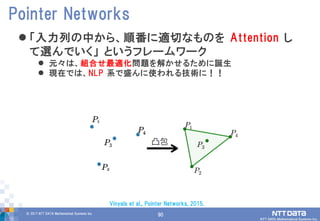
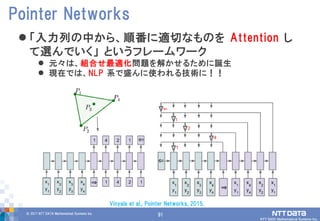
DATA Mathematical Systems Inc. 90 「入力列の中から、順番に適切なものを Attention し て選んでいく」 というフレームワーク 元々は、組合せ最適化問題を解かせるために誕生 現在では、NLP 系で盛んに使われる技術に!! Pointer Networks Vinyals et al., Pointer Networks, 2015.
91.
91© 2017 NTT
DATA Mathematical Systems Inc. 91 「入力列の中から、順番に適切なものを Attention し て選んでいく」 というフレームワーク 元々は、組合せ最適化問題を解かせるために誕生 現在では、NLP 系で盛んに使われる技術に!! Pointer Networks Vinyals et al., Pointer Networks, 2015.
92.
92© 2017 NTT
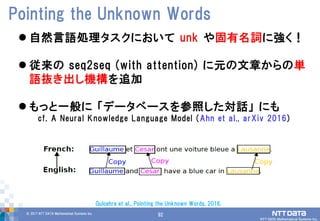
DATA Mathematical Systems Inc. 92 自然言語処理タスクにおいて unk や固有名詞に強く! 従来の seq2seq (with attention) に元の文章からの単 語抜き出し機構を追加 もっと一般に 「データベースを参照した対話」 にも cf. A Neural Knowledge Language Model (Ahn et al., arXiv 2016) Pointing the Unknown Words Gulcehre et al., Pointing the Unknown Words, 2016.
93.
93© 2017 NTT
DATA Mathematical Systems Inc. 93 “Pointing the Unknown Words” を先駆けとして、 seq2seq と pointer-networks を組合せるテクが流行 文章要約において強力 データベース参照しながらのチャットボットにも使えそう Pointer-Generator See et al., Get To The Point: Summarization with Pointer-Generator Networks, 2017. sigmoid で分岐など
94.
© 2017 NTT
DATA Mathematical Systems Inc.
Download
































































![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/171222stargan-171225064145-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)















