PRML 5.1~5.3.1 です(一年前に発表したものですが) ※ https://www.slideshare.net/t_koshikawa/prml-5-pp227pp247 の方が出来が良いです(そちらを参考にしてください).なので,1年前には乗っけなかったんですけど,なんとなく乗っけておきます(演習5.1の導出だけ違うようです)






![多層パーセプトロン
多層パーセプトロンって呼ぶけども・・・実際は?
×(不連続な非線形性を持つ=出力が 𝟎 𝒐𝒓 𝟏 )
複数のパーセプトロン
〇(連続的な非線形性を持つ=出力が [𝟎, 𝟏])
ロジスティック回帰モデルを多層化したもの
7
多層パーセプトロンは SVM と比べて,
コンパクトで処理が高速(浅いネットワークなら?)
尤度関数がモデルパラメータの凸関数とならない](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-7-320.jpg)



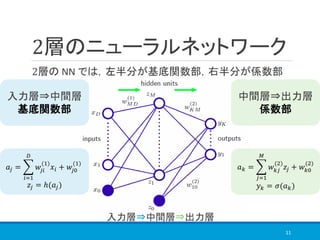

![2層の NN を数式で追うⅡ
入力⇒中間層で入力変数 𝑥1, … , 𝑥 𝐷 の線形和を作成・変換
𝑥0 = 1 を追加して簡単化すると,𝑎𝑗 = σ𝑖=0
𝐷
𝑤𝑗𝑖
(1)
𝑥𝑖
𝑧𝑗 = ℎ(σ𝑖=0
𝐷
𝑤𝑗𝑖
(1)
𝑥𝑖)
13
𝑎𝑗 = σ𝑖=1
𝐷
𝑤𝑗𝑖
(1)
𝑥𝑖 + 𝑤𝑗0
(1)
(5.2)
𝑧𝑗 = ℎ(𝑎𝑗) (5.3)
𝑎𝑗: 活性, 𝑗: [1, 𝑀], (1): 1層目のネットワーク
𝑤𝑗𝑖
(1)
: 重みパラメータ, 𝑤𝑗0
(1)
: バイアスパラメータ
𝑧𝑗: 基底関数の出力, ℎ: 微分可能な非線形活性化関数](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-13-320.jpg)
![2層の NN を数式で追うⅢ
中間⇒出力層で変数 𝑧1, … , 𝑧 𝑀 の線形和を作成・変換
𝑧0 = 1 を追加して簡単化すると,
𝑦 𝑘 = 𝜎(σ 𝑗=0
𝑀
𝑤 𝑘𝑗
(2)
𝑧𝑗)
14
𝑎 𝑘 = σ 𝑗=1
𝑀
𝑤 𝑘𝑗
(2)
𝑧𝑗 + 𝑤 𝑘0
(2)
(5.4)
𝑦 𝑘 = 𝜎(𝑎 𝑘) (5.5)
𝑎 𝑘: 活性, 𝑘: [1, 𝐾], (2): 2層目のネットワーク
𝑤 𝑘𝑗
(2)
: 重みパラメータ, 𝑤 𝑘0
(2)
: バイアスパラメータ
𝑦 𝑘: NN の出力, 𝜎: 活性化関数(sigmoid 関数)](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-14-320.jpg)








![ネットワークの拡張
ネットワークの層を増やすのは簡単.2⇒3層にすると
23
[1] https://towardsdatascience.com/applied-deep-learning-part-1-artificial-neural-
networks-d7834f67a4f6
図1. 3層のネットワーク
ネットワークの層数は重みを持つ層の数(入力層を除く)
※文献による](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-23-320.jpg)
















![ネットワーク訓練(2値分類)Ⅰ
入力 𝐱 が与えられた時の目標 𝑡 の条件付き分布は
𝑦 𝐱, 𝐰 は条件付き確率 𝑝(𝐶1|𝐱) と解釈可能なため
𝑝 𝐶2 𝐱 = 1 − 𝑦 𝐱, 𝐰
出力ユニットの活性化関数は logistic sigmoid 関数
𝑦 = 𝜎 𝑎 =
1
1+exp(−𝑎)
40
𝑡 = 1 がクラス 𝐶1, 𝑡 = 0 がクラス 𝐶2な1つの目標変数 𝑡
𝑝(𝑡|𝐱, 𝐰) = 𝑦 𝐱, 𝐰 𝑡
{1 − 𝑦 𝐱, 𝐰 }1−𝑡
𝑦 𝐱, 𝐰 : NN の出力[0,1], 𝑝(𝑡|𝐱, 𝐰):ベルヌーイ分布](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-40-320.jpg)

![ネットワーク訓練(2値分類)Ⅲ
𝐾 個の出力を持ち,各活性化関数に logistic sigmoid 関数
入力 𝐱 が与えられた時の目標 𝐭 の条件付き分布は
負の対数尤度を取ると,
𝐸 𝐰 = − σ 𝑛=1
𝑁 σ 𝑘=1
𝐾
𝑡 𝑛𝑘ln𝑦 𝑛𝑘 + 1 − 𝑡 𝑛𝑘 ln 1 − 𝑦 𝑛𝑘
誤差関数の微分は回帰同様,
𝜕𝐸
𝜕𝑎 𝑘
= 𝑦 𝑘 − 𝑡 𝑘
42
(ラベルが独立な)𝐾 個の異なる2値分類問題を解く
𝑝(𝐭|𝐱, 𝐰) = ෑ
𝑘=1
𝐾
𝑦 𝑘 𝐱, 𝐰 𝑡 𝑘{1 − 𝑦 𝑘 𝐱, 𝐰 }1−𝑡 𝑘
𝑦 𝐱, 𝐰 : NN の出力[0,1], 𝐭: 目標値の集合 𝑡 𝑘 , 𝑡 𝑘 ∈ {0,1}
※この線形クラス分類モデルでは重みが独立だが NN では共有](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-42-320.jpg)




![パラメータ最適化Ⅱ
停留点: 勾配が0になる点 𝐰 (𝛻𝐸 𝐰 = 0)
極小点:連続関数が減少から増加に変わる点
極大点:連続関数が増加から減少に変わる点
鞍点:ある方向では極大点,別の方向では極小点
重み空間対称性より,𝑀 個のユニットを持つ2層の NN には
等価な極小点が 2 𝑀 𝑀! 個存在
47
誤差関数 𝐸 𝐰 を最小化する重み 𝐰 を見つけたい
※図, [2]https://qiita.com/ishizakiiii/items/82cfa9522ceb20703f2b](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-47-320.jpg)

![パラメータ最適化Ⅳ
基本的に,2ステップを繰り返す
① 初期値 𝑤(0) の選択
② 重み空間内の移動 𝑤(𝜏+1)
= 𝑤(𝜏)
+ ∆𝑤(𝜏)
𝜏: 反復ステップ数,∆𝑤(𝜏): 𝜏 時の重みベクトル更新量
最適化手法はいくつかあるが,結局 ∆𝑤(𝜏)
が違うだけ
⇒ 更新時によく使用される勾配情報の重要性をチェック!
49
解析的に解くのはあまりに厳しいので反復手順で考える
※図, [2]https://qiita.com/ishizakiiii/items/82cfa9522ceb20703f2b](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-49-320.jpg)



















![誤差関数微分の評価Ⅱ
出力 𝑦 𝑘 が入力変数 𝑥𝑖 の線形和の単純な線形モデルだと
𝑦 𝑘 = σ𝑖 𝑤 𝑘𝑖 𝑥𝑖
ある特定の入力パターン 𝑛 に対する誤差関数は
𝑦 𝑛𝑘 = 𝑦 𝑘(𝐱 𝑛, 𝐰) として,𝐸 𝑛 =
1
2
σ 𝑘 𝑦 𝑛𝑘 − 𝑡 𝑛𝑘
2
この誤差関数の重み 𝑤𝑗𝑖 に関する勾配は
𝜕𝐸 𝑛
𝜕𝑤 𝑗𝑖
= 𝑦 𝑛𝑗 − 𝑡 𝑛𝑗 𝑥 𝑛𝑖
70
局所的な計算
[重みに関する勾配] = [出力側の誤差信号] × [入力側の変数]](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-70-320.jpg)

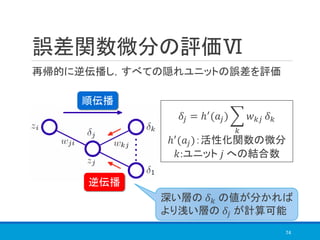
![誤差関数微分の評価Ⅳ
𝐸 𝑛の重み 𝑤𝑗𝑖 に関する微分の評価をしていく(逆伝播)
𝐸 𝑛 はユニット 𝑗 への入力和 𝑎𝑗 を通して重み 𝑤𝑗𝑖 に依存
𝜕𝐸 𝑛
𝜕𝑤 𝑗𝑖
=
𝜕𝐸 𝑛
𝜕𝑎 𝑗
𝜕𝑎 𝑗
𝜕𝑤 𝑗𝑖
誤差 𝛿𝑗 ≡
𝜕𝐸 𝑛
𝜕𝑎 𝑗
であり, 𝑎𝑗 = σ𝑖 𝑤𝑗𝑖 𝑧𝑖 であるから,
𝜕𝑎 𝑗
𝜕𝑤 𝑗𝑖
= 𝑧𝑖
𝜕𝐸 𝑛
𝜕𝑤 𝑗𝑖
= 𝛿𝑗 𝑧𝑖
72
単純な線形モデルから一般的な feed-forward NN に拡張
※特定の入力パターン 𝑛 に依存するが,省略
[微分の値] = [出力側の値] × [入力側の値]](https://image.slidesharecdn.com/prml5-190907085637/85/PRML_from5-1to5-3-1-72-320.jpg)