アジェンダ
p BNNの応用例
n モデルの不確実性,データの不確実性, 予測の不確実性
n 不確実性の評価指標:相互情報量, 変動率, 予測エントロピー
n 能動学習
n 敵対的例の検知
n Out Of Distribution
n モデル圧縮
n 逐次学習
p 推論手法 ( BBB, MC dropout, SGLD, MNF, Bayesian Ensemble, Hyper Net)
p 比較実験(モデルパラメータの事前分布を通した関数のサンプリング,回帰の予測分布比較)
3
アジェンダ
n BNNの応用例
n モデルの不確実性,データの不確実性, 予測の不確実性
n 不確実性の評価指標:相互情報量, 変動率, 予測エントロピー
n 能動学習
n 敵対的例の検知
n Out Of Distribution
n モデル圧縮
n 逐次学習
n 推論手法 ( BBB, MC dropout, SGLD, MNF, Bayesian Ensemble, Hyper Net)
n 比較実験(モデルパラメータの事前分布を通した関数のサンプリング,回帰の予測分布比較)
9
10.
不確実性の種類
n ノイズの多いデータ(偶然性の不確実性:Aleatoric uncertainty)
n モデルパラメータの不確実性(認識の不確実性:Epistemic uncertainty )
n 予測の不確実性=偶然性の不確実性+認識の不確実性
n 不確実性を知る利点
p 意思決定プロセス内で意図しない行動を防ぐ鍵となる可能性がある.
p 医療の画像診断,車の自動運転,時系列データの異常検知 [Zhu 17]
[Kendall & Gal 17]
10
画像における偶然と認識(モデル)の不確実性の比較
[Kendall and Gal17]
偶然 認識
n 偶然性の不確実性:物体の境界やカメラから遠いところで不確実性が増大.
n 認識の不確実性:モデルが過去のデータから判断できない領域で不確実性が増大.
セグメンテーションの失敗例
画像のノイズが原因ではなく,
学習データに似たような画像が
なかったのが原因.
13
アジェンダ
p BNNの応用例
n モデルの不確実性,データの不確実性, 予測の不確実性
n 不確実性の評価指標:相互情報量, 変動率, 予測エントロピー
n 能動学習
n 敵対的例の検知
n Out Of Distribution
n モデル圧縮
n 逐次学習
p 推論手法 ( BBB, MC dropout, SGLD, MNF, Bayesian Ensemble, Hyper Net)
p 比較実験(モデルパラメータの事前分布を通した関数のサンプリング,回帰の予測分布比較)
20
OUT OF DISTRIBUTION検出
¡ 背景: 学習データの分布と異なるデータ分布からのサンプルに対してモデルは知らないと返さない.
¡ 対策: BNNを用いて,学習データと分布が異なることを不確実性を高くして示す.
ü 一般的に,OODや訓練とテストデータの違いは,認識の不確実性を利用することが多い.
https://github.com/brendenlake/omniglot/blob/master/omniglot_grid.jpg
MNISTOMNIGLOT
データ分布異なる
24
アジェンダ
p BNNの応用例
n モデルの不確実性,データの不確実性, 予測の不確実性
n 不確実性の評価指標:相互情報量, 変動率, 予測エントロピー
n 能動学習
n 敵対的例の検知
n Out Of Distribution
n モデル圧縮
n 逐次学習
p 推論手法 ( BBB, MC dropout, SGLD, MNF, Bayesian Ensemble, Hyper Net)
p 比較実験(モデルパラメータの事前分布を通した関数のサンプリング,回帰の予測分布比較)
26
アジェンダ
p BNNの応用例
n モデルの不確実性,データの不確実性, 予測の不確実性
n 不確実性の評価指標:相互情報量, 変動率, 予測エントロピー
n 能動学習
n 敵対的例の検知
n Out Of Distribution
n モデル圧縮
n 逐次学習
p 推論手法 ( BBB, MC dropout, SGLD, MNF, Bayesian Ensemble, Hyper Net)
p 比較実験(モデルパラメータの事前分布を通した関数のサンプリング,回帰の予測分布比較)
32
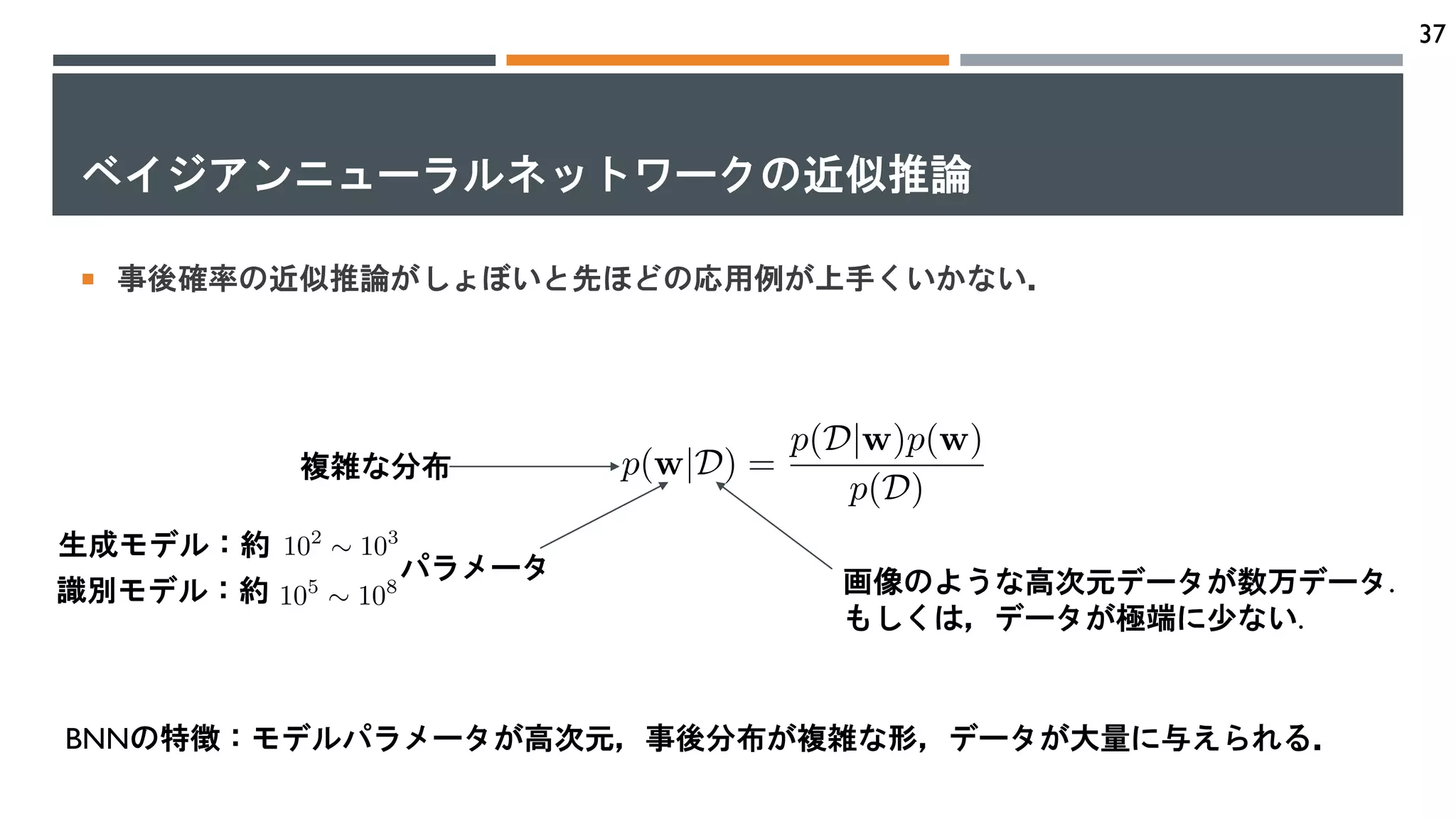
アジェンダ
p BNNの応用例
n モデルの不確実性,データの不確実性, 予測の不確実性
n 不確実性の評価指標:相互情報量, 変動率, 予測エントロピー
n 能動学習
n 敵対的例の検知
n Out Of Distribution
n モデル圧縮
n 逐次学習
p 推論手法 ( BBB, MC dropout, SGLD, MNF, Bayesian Ensemble, Hyper Net)
p 比較実験(モデルパラメータの事前分布を通した関数のサンプリング,回帰の予測分布比較)
36
アジェンダ
p BNNの応用例
n モデルの不確実性,データの不確実性, 予測の不確実性
n 不確実性の評価指標:相互情報量, 変動率, 予測エントロピー
n 能動学習
n 敵対的例の検知
n Out Of Distribution
n モデル圧縮
n 逐次学習
p 推論手法 ( BBB, MC dropout, SGLD, MNF, Bayesian Ensemble, Hyper Net)
p 比較実験(モデルパラメータの事前分布を通した関数のサンプリング,回帰の予測分布比較)
51
¡ Deep| Bayes
SUMMERSCHOOL ON DEEP LEARNING AND BAYESIAN METHODS
資料がダウンロードできて内容が濃い. 最近の話題も豊富!!
URL: https://deepbayes.ru/
DEEP | BAYES
62
63.
参考文献1
¡ Adler, J.,& Öktem, O. (2018). Deep Bayesian Inversion. arXiv preprint arXiv:1811.05910. 敵対的学習 逆問題
¡ Atanov,A.,Ashukha,A., Struminsky, K.,Vetrov, D., & Welling, M. (2018).The Deep Weight Prior. Modeling a prior distribution for
CNNs using generative models. arXiv preprint arXiv:1810.06943. 事前分布 転移学習
¡ Balan,A. K., Rathod,V., Murphy, K. P., & Welling, M. (2015). Bayesian dark knowledge. In Advances in Neural Information Processing
Systems (pp. 3438-3446). モンテカルロ 知識蒸留
¡ Blundell, C., Cornebise, J., Kavukcuoglu, K., & Wierstra, D. (2015).Weight uncertainty in neural networks. arXiv preprint
arXiv:1505.05424. 変分推論・R Trick
¡ Depeweg, S., Hernández-Lobato, J. M., Doshi-Velez, F., & Udluft, S. (2017). Decomposition of uncertainty in bayesian deep learning
for efficient and risk-sensitive learning. arXiv preprint arXiv:1710.07283. 潜在変数・不確実性
¡ Depeweg, S., Hernández-Lobato, J. M., Doshi-Velez, F., & Udluft, S. (2017). Uncertainty decomposition in bayesian neural networks
with latent variables. arXiv preprint arXiv:1706.08495.潜在変数・不確実性
¡ Kingma, D. P., Salimans,T., Jozefowicz, R., Chen, X., Sutskever, I., & Welling, M. (2016). Improved variational inference
with inverse autoregressive flow. In Advances in neural information processing systems (pp. 4743-4751). IAF
63
64.
参考文献2
¡ Dikov, G.,van der Smagt, P., & Bayer, J. (2019). Bayesian Learning of Neural Network Architectures. arXiv preprint
arXiv:1901.04436. モデル圧縮
¡ Dmitry Molchanov.,(2018) Bayesian neural networks (andVI in implicit models) Samsung AI Center, Samsung-HSE Laboratory
まとめ
¡ Farquhar, S., & Gal,Y. (2019).A Unifying BayesianView of Continual Learning. arXiv preprint arXiv:1902.06494. 逐次学習
¡ Feinman, R., Curtin, R. R., Shintre, S., & Gardner,A. B. (2017). Detecting adversarial samples from artifacts. arXiv preprint
arXiv:1703.00410.敵対的サンプル検出
¡ Flam-Shepherd, D., Requeima, J., & Duvenaud, D. (2017). Mapping gaussian process priors to bayesian neural networks. In NIPS Bayesian
deep learning workshop. GP・事前分布
¡ Ghosh, S.,Yao, J., & Doshi-Velez, F. (2018). Structured variational learning of Bayesian neural networks with horseshoe priors. arXiv preprint
arXiv:1806.05975. 変分推論・事前分布 horseshoe
¡ Ghosh, S., & Doshi-Velez, F. (2017). Model selection in bayesian neural networks via horseshoe priors. arXiv preprint arXiv:1705.10388. モ
デル選択・事前分布 horseshoe
¡ Gal,Y. (2016). Uncertainty in deep learning (Doctoral dissertation, PhD thesis, University of Cambridge). まとめ
64
65.
参考文献3
¡ Hafner, D.,Tran,D., Irpan,A., Lillicrap,T., & Davidson, J. (2018). Reliable uncertainty estimates in deep neural networks using noise
contrastive priors. arXiv preprint arXiv:1807.09289. OOD 不確実性 事前分布
¡ Henning, C., von Oswald, J., Sacramento, J., Surace, S. C., Pfister, J. P., & Grewe, B. F. (2018).Approximating the Predictive
Distribution via Adversarially-Trained Hypernetworks. In Bayesian Deep LearningWorkshop, NeurIPS (Spotlight) 2018. GAN &ハイ
パーネット
¡ Huszár, F. (2017).Variational inference using implicit distributions. arXiv preprint arXiv:1702.08235. GAN 変分推論
¡ Karaletsos,T., Dayan, P., & Ghahramani, Z. (2018). Probabilistic meta-representations of neural networks. arXiv preprint
arXiv:1810.00555. 潜在変数
¡ Kendall,A., & Gal,Y. (2017).What uncertainties do we need in bayesian deep learning for computer vision?. In Advances in neural
information processing systems (pp. 5574-5584). CV応用
¡ Kingma, D. P., Salimans,T., & Welling, M. (2015).Variational dropout and the local reparameterization trick. In Advances in Neural
Information Processing Systems (pp. 2575-2583). VI 変分推論
¡ Krueger, D., Huang, C.W., Islam, R.,Turner, R., Lacoste,A., & Courville,A. (2017). Bayesian hypernetworks. arXiv preprint
arXiv:1710.04759. ハイパーネットワーク
65
66.
参考文献4
¡ Kochurov, M.,Garipov,T., Podoprikhin, D., Molchanov, D.,Ashukha,A., &Vetrov, D. (2018). Bayesian incremental learning for
deep neural networks. arXiv preprint arXiv:1802.07329. 逐次学習
¡ Lacoste,A., Oreshkin, B., Chung,W., Boquet,T., Rostamzadeh, N., & Krueger, D. (2018). Uncertainty in multitask transfer
learning. arXiv preprint arXiv:1806.07528. 応用・転移学習
¡ Lacoste,A., Boquet,T., Rostamzadeh, N., Oreshkin, B., Chung,W., & Krueger, D. (2017). Deep prior. arXiv preprint
arXiv:1712.05016. 事前確率
¡ Lakshminarayanan, B., Pritzel,A., & Blundell, C. (2017). Simple and scalable predictive uncertainty estimation using deep
ensembles. In Advances in Neural Information Processing Systems (pp. 6402-6413). アンサンブル
¡ Louizos, C., Ullrich, K., & Welling, M. (2017). Bayesian compression for deep learning. In Advances in Neural Information
Processing Systems (pp. 3288-3298). モデル圧縮
¡ Louizos, C., & Welling, M. (2017,August). Multiplicative normalizing flows for variational bayesian neural networks.
In Proceedings of the 34th International Conference on Machine Learning-Volume 70 (pp. 2218-2227). JMLR. org. 変分推論・NF
¡ Nalisnick, E.T. (2018). On Priors for Bayesian Neural Networks. PhD thesis. 事前分布まとめ
¡ Nguyen, C.V., Li,Y., Bui,T. D., & Turner, R. E. (2017).Variational continual learning. arXiv preprint arXiv:1710.10628. 逐次学習
66
67.
参考文献5
¡ Malinin,A., &Gales, M. (2018). Predictive uncertainty estimation via prior networks. In Advances in Neural Information Processing
Systems (pp. 7047-7058). OODの検知
¡ Pawlowski, N., Brock,A., Lee, M. C., Rajchl, M., & Glocker, B. (2017). Implicit weight uncertainty in neural networks. arXiv preprint
arXiv:1711.01297.ハイパーネット
¡ Pearce,T., Zaki, M., and Neely,A. (2018). Bayesian Neural Network Ensembles. In Bayesian Deep LearningWorkshop, NeurIPS (NIPS)
2018. アンサンブル
¡ Pearce,T., Zaki, M., Brintrup,A., & Neel,A. (2018). Uncertainty in neural networks: Bayesian ensembling. arXiv preprint
arXiv:1810.05546. アンサンブル
¡ Pearce,T., Zaki, M., Brintrup,A., & Neely,A. (2019). Expressive Priors in Bayesian Neural Networks: Kernel Combinations and
Periodic Functions. arXiv preprint arXiv:1905.06076. カーネル
¡ Ranganath, R.,Tran, D., & Blei, D. (2016, June). Hierarchical variational models. In International Conference on Machine Learning (pp.
324-333).変分推論テクニック
¡ Sensoy, M., Kaplan, L., & Kandemir, M. (2018). Evidential deep learning to quantify classification uncertainty. In Advances in Neural
Information Processing Systems (pp. 3179-3189). クラス分類の不確かさ
67
68.
参考文献6
¡ Sheikh,A. S.,Rasul, K., Merentitis,A., & Bergmann, U. (2017). Stochastic maximum likelihood optimization via hypernetworks. arXiv preprint
arXiv:1712.01141. 事前確率・ハイパーネットワーク
¡ Shin, H., Lee, J. K., Kim, J., & Kim, J. (2017). Continual learning with deep generative replay. In Advances in Neural Information Processing
Systems (pp. 2990-2999). 逐次学習
¡ Thulasidasan, S., Bhattacharya,T., Bilmes, J., Chennupati, G., & Mohd-Yusof, J. (2018). Knows When it Doesn’t Know: Deep Abstaining
Classifiers.クラス分類の不確かさ
¡ Ullrich, K., Meeds, E., & Welling, M. (2017). Soft weight-sharing for neural network compression. arXiv preprint arXiv:1702.04008. モデル圧
縮
¡ Vadera, M. P., & Marlin, B. M. (2019).Assessing the Robustness of Bayesian Dark Knowledge to Posterior Uncertainty. arXiv preprint
arXiv:1906.01724.知識蒸留
¡ Wang, K. C.,Vicol, P., Lucas, J., Gu, L., Grosse, R., & Zemel, R. (2018).Adversarial distillation of bayesian neural network posteriors. arXiv
preprint arXiv:1806.10317. 事後確率・敵対的学習
¡ Welling, M., & Teh,Y.W. (2011). Bayesian learning via stochastic gradient Langevin dynamics. In Proceedings of the 28th international conference
on machine learning (ICML-11) (pp. 681-688). サンプリング SGLD
¡ Zhu, L., & Laptev, N. (2017, November). Deep and confident prediction for time series at uber. In 2017 IEEE International Conference on Data
MiningWorkshops (ICDMW) (pp. 103-110). IEEE. 異常検知
68



![¡ NNの出力に不確実性を持たせるため,決定的なNNから確率的なNNへ.
BNN:ベイジアンニューラルネットワーク
NN (ex: RNN, CNN, GNN)
[Charles+ 15]
BNNNN
確率的に出力が変化.
モデル
事前確率
に対する事前の信念.
4](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-4-2048.jpg)

![BNNにおけるQ &A 1/3
¡ NNをベイズ化することは何が嬉しい?
¡ 正則化,アンサンブル,不確実性の推定,モデル選択,逐次学習
¡ BNNの応用問題って何があるの?
¡ 能動学習,敵対的サンプルの検出,OOD検出,モデル圧縮,転移学習[Lacoste 18],強化学習[Gal 16]
¡ モデルパラメータの事前分布は標準ガウス分布でいいの?
¡ 学習データに事前知識があっても,モデルパラメータに事前知識がないため,正則化として使われがち.
¡ Implicitな確率分布[Lacoste 17]やスパース性を意識した事前 分布[Ghosh 17]もある.
¡ GPの事前分布と対応づけようとする研究[Flam-Shepherd 17]もある.
¡ BNNの事前確率のまとめ[Nalisnick 18].
6](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-6-2048.jpg)
![BNNにおけるQ &A 2/3
¡ 事後分布は解析的にもとまるの?
¡ NO,そのためサンプリングか変分推論がおこなわれる. (後者が近年は人気.)
¡ Deep Generative Modelの方で,確率的なNNの近似推論系の話は良くまとめられている.スライド[61,62]
¡ 近似事後分布はガウス分布でいいの?
¡ ELBOのKL項の計算が解析的にもとまるから利用されがち.
¡ NNのパラメータ間の相関を捉えたり,分布の多峰性を捉えるような表現力を高める研究が多い.
¡ 例:Normalizing Flowによる簡単な分布の変形[Krueger 17]やGANを用いたimplicitな分布[Adler 18].
¡ 各重みパラメータの近似事後分布はそれぞれ独立でいいの?
¡ 予測性能と不確かさが悪くなるから微妙.各重みパラメータの相関も考慮する研究がある.
¡ 例:重みパラメータに潜在変数を導入するか[Karaletsos 18], Hyper Network[Pawlowski 18]を導入し実現.
7](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-7-2048.jpg)
![BNNにおけるQ &A 3/3
¡ 活性化関数の選択は予測に影響しないの?
¡ 関数の概形が大きく影響する.実験で色々な活性化関数で条件を変えて関数をサンプリングした.
¡ [Gal 16]の4章Uncertainty Quality にも図付きでたくさん実験結果がのっている.
¡ GPのカーネルを設定するのと 似ている部分についても言及されている[Pearce 19].
¡ 計算時間はかかるの?
¡ サンプリングすると計算時間はかかる.サンプル数を多く取らないと予測分散が過小評価される.
¡ テスト時の計算時間を減らす知識蒸留[Balan 15]がある.
¡ 予測分布は不確かさを表現しているの?
¡ 近似はどうしても精度と不確かさが犠牲になる. 比較した実験をスライド[57-59]紹介.
¡ 分類問題において不確かさを示すベイズ推論を用いない研究[Sensoy 18][Thulasidasan 18]がある.
8](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-8-2048.jpg)

![不確実性の種類
n ノイズの多いデータ(偶然性の不確実性:Aleatoric uncertainty )
n モデルパラメータの不確実性(認識の不確実性:Epistemic uncertainty )
n 予測の不確実性=偶然性の不確実性+認識の不確実性
n 不確実性を知る利点
p 意思決定プロセス内で意図しない行動を防ぐ鍵となる可能性がある.
p 医療の画像診断,車の自動運転,時系列データの異常検知 [Zhu 17]
[Kendall & Gal 17]
10](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-10-2048.jpg)
![偶然性の不確実性
¡ 多くのデータを観測しても不確実性は減少しない.
¡ 測定精度が向上すると不確実性は減少する.
ü 偶然性の不確実性の捉え方( 特に不均一な不確実性)
¡ 入力に依存する出力のノイズ変数
¡ シンプルな入力ノイズ(潜在変数)BNN+LVモデル
[Depeweg 17]
[Kendall and Gal 17]
[Depeweg 17]
観測されていない確率的特徴をz が捉える.
観測ノイズが大きい
小 小
入力によってノイズ量が違うとき
Heteroscedastic uncertainty(不均一な不確実性)
11](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-11-2048.jpg)
![認識(モデル)の不確実性
¡ 多くのデータを観測すると不確実性は減少する.
¡ 回帰の予測分散
,
偶然の不確実性(均一) 認識の不確実性
[Pearce 18]
認識の不確実性大
偶然の不確実性小
12](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-12-2048.jpg)
![画像における偶然と認識(モデル)の不確実性の比較
[Kendall and Gal 17]
偶然 認識
n 偶然性の不確実性:物体の境界やカメラから遠いところで不確実性が増大.
n 認識の不確実性:モデルが過去のデータから判断できない領域で不確実性が増大.
セグメンテーションの失敗例
画像のノイズが原因ではなく,
学習データに似たような画像が
なかったのが原因.
13](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-13-2048.jpg)
![偶然性の不確実性の均一性と不均一性を仮定した場合の比較
観測ノイズを小さく均一と仮定 観測ノイズが大きく均一と仮定 観測ノイズを不均一と仮定
詳しい詳細は[Gal 16]の4.6節
n [左] 訓練データに適合しており,予測分散が小さい.
n [中央] 予測平均が平滑化されている.データのあるところでも分散が大きくなっている.
n [右] 予測平均は平滑化され,予測分散は位置に応じて異なる.
14](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-14-2048.jpg)
![認識(モデル)の不確実性と予測の不確実性の違い
¡ ある犬猫のクラス分類を学習したBNNが,テストデータに対して3つの出力パターンを示した.
詳細:事後確率からサンプルしたモデルパラメータの10個の出力確率の結果.
1. 全て犬の予測確率が1の場合 { (1, 0), (1, 0),…,(1, 0)}
2. 全ての予測確率が0.5 の場合 { (0.5, 0.5), (0.5, 0.5),…,(0.5, 0.5)}
3. 半分1で半分0の場合 { (1, 0), (0, 1),…, (0, 1), (1, 0)}
問
¡ モデル不確実性が高いのは何番? Ans. 3
¡ 予測の不確実性が高いのは何番? Ans. 2, 3
2, 3の違いはなんだろう?そのための指標を紹介.
M = 10
15
[Gal 16]](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-15-2048.jpg)


![相互情報量
予測エントロピー
¡ 予測分布とモデルパラメータの事後分布との相互情報量の大きさは認識の不確実性を意味する.
データの不確実性
[Depeweg 18]
生データ xの生成の確率密度 予測分布
学習データがない領域
生データのばらつきが大きい箇所
予測エントロピー データの不確実性 相互情報量
18](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-18-2048.jpg)




![敵対的例の検出
¡ 背景:敵対的サンプルを検出するのは誤検知で重要になる.
¡ 対策:敵対的サンプルを予測モデルに入力した場合,予測の不確実性が大きくなることで検出.
[Feinman 17]不確実性
頻
度
敵対的サンプル
右図:MNINSTデータを用いて, LeNet convnetをMC dropoutで学習.
テストデータのモデルの不確かさをプロット
normal
noizy
adversarial (BIM)
23](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-23-2048.jpg)

![OOD検出の研究
¡ OOD専用の不確実性 Prior Networksの提案 [Malinin 18]
¡ データの入出力関係の不確実性 Data priorsの提案 [Hafner 18]
¡ パラメータに分布を仮定せず,OODの不確実性を計算する手法 [Sensoy 18]
[Sensoy 18]の手法
単純なソフトマックスを使ったクラス分類 OOD
25](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-25-2048.jpg)


![圧縮の思想の紹介
混合ガウス分布を用いた経験ベイズ法 スキップ接続やマスクを確率変数にしたベイズアプローチ
Horseshoe priorを用いて疎にする手法.
[Dikov 19]
[Ghosh 17]
[Ullrich 17]
知識蒸留
層ごと
ユニットごと
ハーフ
コーシー
[Balan 15]
[Vadera 19]
再学習時,w=0
多くなるように
x y
28](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-28-2048.jpg)




![逐次学習
¡ 背景:事後分布を簡単な分布で近似するBNNの場合,逐次学習がうまくいかない.
¡ 対策:Prior-focused Continual Learning [Nguyen 17] , Likelihood-focused Continual Learning [Shin 17]
事前確率(一期前の事後確率)
逐次学習
Multi-headed Split MNIST.
0/1 2/3 4/5 6/7 8/9
右図:近年の手法だと過去の状態を保持し,性能が極端に落ちていない.
[Farquhar 19]
逐次のメリット:過去のデータを保持し続ける必要がない.
例えば,患者のデータなど永遠に保持したくない場合がある.
33](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-33-2048.jpg)

![LIKELIHOOD-FOCUSED CONTINUAL LEARNING の補足
¡ [Shin 17]はGeneratorに過去のデータを記憶させようとしている.
¡ 一期前のパラメータの近似事後分布を近似しなくなったが, Generator の学習がうまくいくのか疑問.
の生成方法
[Shin 17]
35](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-35-2048.jpg)




![BAYES BY BACKPROP
¡ Gaussian reparameterisation trick を用いて近似事後分布の変分パラメータを学習.
分解された近似事後分布
ELBOを最適化
詳しい式は [Blundell 15]
41](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-41-2048.jpg)
![MC DROPOUT
:変分パラメータ
:期待値
¡ NNの正則化手法のドロップアウトが変分推論としてみることができる.
ELBO
[Gal 16]
42](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-42-2048.jpg)

![MULTIPLICATIVE NORMALIZING FLOWS (MNF)
¡ 各ユニットごとに与える潜在変数z を用いて重みパラメータ間の非線形な依存関係と
分布の多峰性をを捉える.
近似事後分布
階層モデル
…
例
FactorizedVIモデル
[Louizos 17]
44](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-44-2048.jpg)
![MNFの目的関数
積分消去できない.
ベイズの定理を用いる.
補助事後分布の近似
ELBO (1)
(1)に代入.
[Ranganath 16]
学習するパラメータ
補助事後分布のパラメータ
のNFパラメータ
の平均と分散
45](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-45-2048.jpg)
![HYPER NETWORK
FactorizedVI の弱点
¡ 近似分布を各モデルパラメータで独立にすると,モデルパラメータの相関を捉えられない.
¡ 近似分布をガウス分布に固定すると単峰性になり,真の事後分布の多峰性を捉えられない.
Hyper network:main netのパラメータを出力するNN.
¡ 近似分布にHyper Net を使用することで,パラメータ間の相関と多峰性を捉える.
¡ Main Network のパラメータ数が高次元になるとメモリを食う上にHyper Netの学習に苦しむ.
[Pawlowski 17]
46](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-46-2048.jpg)
![IMPLICIT WEIGHT UNCERTAINTY IN NEURAL NETWORKS
¡ 近似事後分布にHypernetを用い,KL項を工夫した手法 Bayes by Hypernet (BbH).
¡ 最近の近似推論と比較した論文.
¡ 計算時間はかかるが,各層ごとにHypernetを用いた方が精度は出る.
BbHの2層目の重みの事後分布から
100サンプルとったヒストグラム.
Hypernet
多峰性を捉えている
[Pawlowski 17]
47](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-47-2048.jpg)
![BAYESIAN HYPERNETWORKS
[Krueger 17]
近似分布
積分計算を避けるため,
¡ Hypernetを用いた別の研究を紹介. 先ほどのHypernetと意味が異なる.
¡ 近似事後分布に可逆可能なNormalizing FlowのIAF[Kingma 16]を導入し, ノイズ分布の周辺化を避けた.
ハイパーネットワーク
真の分布
モデル
右図パラメータの多峰性をHyperNetは捉えている.
48](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-48-2048.jpg)
![BAYESIAN ENSAMBLE
¡ (一部の条件を加えた)NNのアンサンブルによって,モデルパラメータの事後分布からサンプ
リングしたものとみれる.
¡ 条件:各NNの損失関数に以下の正則化項を加える.
[Pearce 18]
モデルパラメータの事前分布
固定学習
アンサンブル数は,
実験では5~10
49](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-49-2048.jpg)
![BAYESIAN ENSAMBLE
[Pearce 18]
Randomised Anchored MAP Sampling:事後分布からのサンプリング.
の場合
解析的にもとまる.(NN:できない)
50](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-50-2048.jpg)


![活性化関数を変えてNNの出力を比較
¡ NNのアーキテクチャ 1層 100ユニット 全結合,事前分布:標準ガウス分布 分散1.0
tanh
ReLU
RBF
periodic
sigmoid
sign
53
[Flam-Shepherd 17]にGPと対応させた関数サンプリングの図があります.](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-53-2048.jpg)



![近似推論の予測分布結果
NNアーキテクチャ
1層100ユニット
relu関数
事前分布:標準ガウス分布
BBB [Blundell 15]BbH [Pawlowski 17]MNF [Louizos 17]
MC dropout[Gal 16] Ensemble [Lakshminarayanan 17]MAP
コード元
https://github.com/pawni/BayesByHypernet/.
57](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-57-2048.jpg)
![近似推論の予測分布結果
NNアーキテクチャ
2層 300-300ユニット
relu関数=>tanh関数
事前分布:標準ガウス分布
BBB [Blundell 15]BbH [Pawlowski 17]MNF [Louizos 17]
MC dropout[Gal 16] Ensemble [Lakshminarayanan 17]MAP
58](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-58-2048.jpg)
![近似推論の予測分布結果
NNアーキテクチャ
2層 500-500ユニット
relu関数=>relu関数
事前分布:標準ガウス分布
BBB [Blundell 15]BbH [Pawlowski 17]MNF [Louizos 17]
MC dropout[Gal 16] Ensemble [Lakshminarayanan 17]MAP
59](https://image.slidesharecdn.com/bayesianneuralnetwork-190704004637/75/Bayesian-Neural-Networks-Survey-59-2048.jpg)













![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Bayesian Uncertainty Estimation for Batch Normalized Deep Networks](https://cdn.slidesharecdn.com/ss_thumbnails/190719dlver2-190719035734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)



![[論文紹介] 機械学習システムの安全性における未解決な問題](https://cdn.slidesharecdn.com/ss_thumbnails/random-211002234309-thumbnail.jpg?width=640&height=640&fit=bounds)









