More Related Content

PDF
![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir... 
PPTX

PDF

PDF

PDF
Attentionの基礎からTransformerの入門まで ![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Neural Ordinary Differential Equations 
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化 What's hot

PDF

PPTX
近年のHierarchical Vision Transformer 
PDF
Skip Connection まとめ(Neural Network) 
PPTX
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF

PDF

PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks - 
PDF
Anomaly detection 系の論文を一言でまとめた ![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute... 
PDF

PPTX
【論文紹介】How Powerful are Graph Neural Networks? ![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜 
PPTX

PDF
Domain Adaptation 発展と動向まとめ(サーベイ資料) ![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ 
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー 
PDF

PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話 
PDF

PDF
Network weight saving_20190123 Viewers also liked

PDF
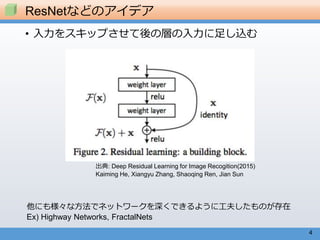
Deep Residual Learning (ILSVRC2015 winner) 
PDF

PPTX

PPTX

PDF
Deep Forest: Towards An Alternative to Deep Neural Networks 
PPTX

PPTX
Globally and Locally Consistent Image Completion 
PPTX

PDF
Deeply-Recursive Convolutional Network for Image Super-Resolution 
PPTX

PPTX

PPTX
Colorful image colorization 
PPTX

PPTX
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network 
PPTX
A simple neural network mnodule for relation reasoning 
PDF
Generating Videos with Scene Dynamics 
PDF

PDF
【2016.01】(1/3)cvpaper.challenge2016 
PPTX

PPTX
Similar to Densely Connected Convolutional Networks

PDF

PDF
(2022年3月版)深層学習によるImage Classificaitonの発展 ![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Dense Captioning分野のまとめ 
PDF
2値化CNN on FPGAでGPUとガチンコバトル(公開版) 
PDF
(2021年8月版)深層学習によるImage Classificaitonの発展 
PDF
Deep residual learning for image recognition 
PPTX
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東) ![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF

PDF
社内論文読み会資料 Image-to-Image Retrieval by Learning Similarity between Scene Graphs 
PPTX
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク 
PPTX
Image net classification with Deep Convolutional Neural Networks 
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016 
PDF

PDF
DeepLearningDay2016Summer 
PDF

PDF

PDF

PDF
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio... 
PPTX
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」 
PPTX
More from harmonylab

PDF
Mixture-of-Personas Language Models for Population Simulation 
PDF
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Lea... 
PDF
Data Scaling Laws for End-to-End Autonomous Driving 
PDF
TransitReID: Transit OD Data Collection with Occlusion-Resistant Dynamic Pass... 
PDF
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving 
PDF
Mixture-of-Personas Language Models for Population Simulation 
PDF
Efficient anomaly detection in tabular cybersecurity data using large languag... 
PDF
【卒業論文】LLMを用いたMulti-Agent-Debateにおける反論の効果に関する研究 
PDF
AECR: Automatic attack technique intelligence extraction based on fine-tuned ... 
PDF
Can Large Language Models perform Relation-based Argument Mining? 
PDF
CTINexus: Automatic Cyber Threat Intelligence Knowledge Graph Construction Us... 
PDF
Multiple Object Tracking as ID Prediction 
PDF
Encoding and Controlling Global Semantics for Long-form Video Question Answering 
PDF
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models throu... 
PDF
QuASAR: A Question-Driven Structure-Aware Approach for Table-to-Text Generation 
PDF
APT-LLM Embedding-Based Anomaly Detection of Cyber Advanced Persistent Threat... 
PDF
Towards Scalable Human-aligned Benchmark for Text-guided Image Editing 
PDF
Large Language Model based Multi-Agents: A Survey of Progress and Challenges 
PDF
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving? 
PDF
Collaborative Document Simplification Using Multi-Agent Systems Recently uploaded

PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研) 
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」 
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望 
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf 
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S... 
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版 
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信 
PDF
PMBOK 7th Edition Project Management Process Scrum 
PDF
PMBOK 7th Edition_Project Management Context Diagram 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis 
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard 
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development Densely Connected Convolutional Networks
- 1.
- 2.
1
論文情報
• タイトル
• DenselyConnected Convolutional Networks
• 投稿日
• 2016/8/25(ver1)
• 2016/11/29(ver2)
• 2016/12/3(ver3)
• 2017/8/27(ver4)
• 発表学会
• CVPR2017
• Best Paper Awards
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
11
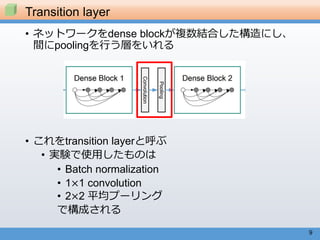
• Bottleneckの導入
• Denseblockの𝐻𝑙をBN-ReLU-Conv(1×1)-BN-ReLU-
Conv(3×3)に変更
• Compression
• Transition layerで特徴量マップの数を減らす
• Transition layer内のconvolution層で出力マップサイズを
𝜃倍にする(0 < 𝜃 ≤ 1)
• 今回の実験では𝜃 = 0.5とした
効率化手法
これらを導入したものと
導入していないものの両方について実験
出典: https://liuzhuang13.github.io/posters/DenseNet.pdf
- 13.
12
• CIFAR, SVHN用
•ベーシックなdense net (𝐿 = 40)
実験で用いたネットワーク
Layers detail
Initial Convolution [3×3 conv (output channel=16)]
Dense Block(1) [3×3 conv]×12
Transition(1) [1×1 conv]
[2×2 average pool stride=2]
Dense Block(2) [3×3 conv]×12
Transition(2) [1×1 conv]
[2×2 average pool stride=2]
Dense Block(3) [3×3 conv]×12
Classification [global average pool]
[softmax]
3×3Conv層では
ゼロパディング
𝐿は3𝑛 + 4でなければならない
3×Dense block + Initial conv + 2×transition + classification
- 14.
13
• 実験ではgrowth rate𝑘 = 12, 24 𝐿 = 40,100のもので実験
• {𝐿 = 40, 𝑘 = 12}, {𝐿 = 100, 𝑘 = 12}, {𝐿 = 100, 𝑘 = 24}
• Bottleneck layerを採用したものに対しては以下のような
設定で実験
• {𝐿 = 100, 𝑘 = 12}, {𝐿 = 250, 𝑘 = 24}, {𝐿 = 190, 𝑘 = 40}
実験で用いたネットワーク
- 15.
14
• ImageNet用
• DenseNetwith bottleneck and compressionを使用
• Dense blockの数は4
• 後述のResNetとの比較のため、最初のconv層と最
後の判別層の形を合わせてある
実験で用いたネットワーク
- 16.
- 17.
16
• CIFARとSVHNに対して実験をおこなった
• SVHN
•Street View House Numbers
• Google street viewから抽出した数字の画像
• 32×32 カラー画像
• Train: 73257枚+531131枚, Test: 26032枚
• Trainのうち6000枚をvalidationに
実験1 CIFAR and SVHN
- 18.
17
• 最適化手法: SGD
•Mini-batchサイズ64
• エポック数 CIFAR: 300, SVHN:40
• 学習率は学習の進み具合で変化させる
• 初期0.1, 50%学習後0.01, 75%学習後0.001
• 重み減衰10−4
• Nesterov momentum 0.9
• データの拡張を行っていないデータセットに対しては
各conv層の後に0.2のドロップアウト層を追加
訓練詳細
- 19.
- 20.
19
• Accuracy
• CIFAR
•ResNetやその他のネットワークよりも低いエ
ラー率を達成
• SVHN
• L=100, k=24のDenseNetでResNetよりも低いエ
ラー率
• DenseNet-BCではあまり性能が良くなっていな
いが、これはSVHNが簡単な問題のためoverfitし
やすいという理由が考えられる
結果について
- 21.
20
• Capacity
• 基本的に𝐿,𝑘が大きくなればなるほど性能が良く
なっている
• DenseNetでは大きく深いモデルの表現力を利用で
きている
• つまりoverfitting, 最適化の困難が発生しにくい
結果について
- 22.
- 23.
- 24.
23
• Train: 1.2millionvalidation: 50000
• データ拡張をおこなう
• Validation setに対するエラー率を調査
• 訓練
• バッチサイズ256, 90エポック
• 学習率は初期0.1,30エポック後0.01, 60エポック後
0.001
• GPUメモリの制約によりDenseNet-161ではバッチ
サイズを128, エポック数を100に
• 90エポック後に学習率を0.0001にする
実験2 ImageNet
- 25.
- 26.
- 27.
- 28.
27
特徴量の再利用性
• すべての層で重みが同ブロックの多くの入力に分散している
• 浅い層の出力特徴量がdenseblock全体で使われている
• Transition layerでも重みが分散している
• 最初の層の情報が直接最後の層に伝わっている
• Dense block2,3ではtransition layerからの出力がほとんど利用されていない
• Transition layerの出力は冗長
• DenseNet-BCで出力を圧縮してうまくいくことと合致している
• Classification layerでは最後の方の出力を重視している
• 最後の方の層で高レベルな特徴を抽出できている
- 29.










![12
• CIFAR, SVHN用
• ベーシックなdense net (𝐿 = 40)
実験で用いたネットワーク
Layers detail
Initial Convolution [3×3 conv (output channel=16)]
Dense Block(1) [3×3 conv]×12
Transition(1) [1×1 conv]
[2×2 average pool stride=2]
Dense Block(2) [3×3 conv]×12
Transition(2) [1×1 conv]
[2×2 average pool stride=2]
Dense Block(3) [3×3 conv]×12
Classification [global average pool]
[softmax]
3×3Conv層では
ゼロパディング
𝐿は3𝑛 + 4でなければならない
3×Dense block + Initial conv + 2×transition + classification](https://image.slidesharecdn.com/b4ba2ff618dbf8a2f3a4d5629b821b761-171026020810/85/Densely-Connected-Convolutional-Networks-13-320.jpg)