Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
harmonylab
PPTX, PDF
14,353 views
A3C解説
DQNを開発したチームによる非同期並列な深層教科学習アルゴリズムの論文を紹介しています。
Technology
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 44 times
1
/ 14
2
/ 14
Most read
3
/ 14
4
/ 14
Most read
5
/ 14
6
/ 14
7
/ 14
8
/ 14
Most read
9
/ 14
10
/ 14
11
/ 14
12
/ 14
13
/ 14
14
/ 14
More Related Content
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
多様な強化学習の概念と課題認識
by
佑 甲野
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PPTX
[DL輪読会]World Models
by
Deep Learning JP
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
Optimizer入門&最新動向
by
Motokawa Tetsuya
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
多様な強化学習の概念と課題認識
by
佑 甲野
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PRML学習者から入る深層生成モデル入門
by
tmtm otm
[DL輪読会]World Models
by
Deep Learning JP
What's hot
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PPTX
[DL輪読会] マルチエージェント強化学習と心の理論
by
Deep Learning JP
PPTX
Triplet Loss 徹底解説
by
tancoro
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
音声認識と深層学習
by
Preferred Networks
PPTX
強化学習 DQNからPPOまで
by
harmonylab
PPTX
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PPTX
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
by
hoxo_m
PDF
機械学習におけるオンライン確率的最適化の理論
by
Taiji Suzuki
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
PDF
Deeplearning輪読会
by
正志 坪坂
PPTX
強化学習における好奇心
by
Shota Imai
PPTX
Generative Adversarial Imitation Learningの紹介(RLアーキテクチャ勉強会)
by
Yusuke Nakata
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
[DL輪読会] マルチエージェント強化学習と心の理論
by
Deep Learning JP
Triplet Loss 徹底解説
by
tancoro
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
音声認識と深層学習
by
Preferred Networks
強化学習 DQNからPPOまで
by
harmonylab
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
深層生成モデルと世界モデル
by
Masahiro Suzuki
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
by
hoxo_m
機械学習におけるオンライン確率的最適化の理論
by
Taiji Suzuki
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
Deeplearning輪読会
by
正志 坪坂
強化学習における好奇心
by
Shota Imai
Generative Adversarial Imitation Learningの紹介(RLアーキテクチャ勉強会)
by
Yusuke Nakata
Viewers also liked
PDF
Introduction to A3C model
by
WEBFARMER. ltd.
PPTX
Mobilenet
by
harmonylab
PPTX
Densely Connected Convolutional Networks
by
harmonylab
PDF
AI勉強会用スライド
by
harmonylab
PPTX
勉強会用スライド
by
harmonylab
PDF
A3Cという強化学習アルゴリズムで遊んでみた話
by
mooopan
PDF
Deep Forest: Towards An Alternative to Deep Neural Networks
by
harmonylab
PPTX
勉強会用スライド
by
harmonylab
PPTX
Globally and Locally Consistent Image Completion
by
harmonylab
PDF
Continuous control with deep reinforcement learning (DDPG)
by
Taehoon Kim
PPTX
DeepLoco
by
harmonylab
PDF
Deeply-Recursive Convolutional Network for Image Super-Resolution
by
harmonylab
PPTX
DLゼミ20170522
by
harmonylab
PPTX
Deep voice
by
harmonylab
PPTX
Colorful image colorization
by
harmonylab
PPTX
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network
by
harmonylab
PDF
Generating Videos with Scene Dynamics
by
harmonylab
PPTX
7月10日(月)dl
by
harmonylab
PPTX
A simple neural network mnodule for relation reasoning
by
harmonylab
PPTX
Ai勉強会20170127
by
harmonylab
Introduction to A3C model
by
WEBFARMER. ltd.
Mobilenet
by
harmonylab
Densely Connected Convolutional Networks
by
harmonylab
AI勉強会用スライド
by
harmonylab
勉強会用スライド
by
harmonylab
A3Cという強化学習アルゴリズムで遊んでみた話
by
mooopan
Deep Forest: Towards An Alternative to Deep Neural Networks
by
harmonylab
勉強会用スライド
by
harmonylab
Globally and Locally Consistent Image Completion
by
harmonylab
Continuous control with deep reinforcement learning (DDPG)
by
Taehoon Kim
DeepLoco
by
harmonylab
Deeply-Recursive Convolutional Network for Image Super-Resolution
by
harmonylab
DLゼミ20170522
by
harmonylab
Deep voice
by
harmonylab
Colorful image colorization
by
harmonylab
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network
by
harmonylab
Generating Videos with Scene Dynamics
by
harmonylab
7月10日(月)dl
by
harmonylab
A simple neural network mnodule for relation reasoning
by
harmonylab
Ai勉強会20170127
by
harmonylab
Similar to A3C解説
PDF
分散型強化学習手法の最近の動向と分散計算フレームワークRayによる実装の試み
by
SusumuOTA
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
PPTX
Deep Recurrent Q-Learning(DRQN) for Partially Observable MDPs
by
Hakky St
PPTX
Batch Reinforcement Learning
by
Takuma Oda
PDF
Rainbow: Combining Improvements in Deep Reinforcement Learning (AAAI2018 unde...
by
Toru Fujino
PPTX
機械学習 論文輪読会 Hybrid Reward Architecture for Reinforcement Learning
by
Yuko Ishizaki
PPTX
Paper intoduction "Playing Atari with deep reinforcement learning"
by
Hiroshi Tsukahara
PDF
強化学習勉強会・論文紹介(Kulkarni et al., 2016)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
[DL輪読会]Hyper parameter agnostic methods in reinforcement learning
by
Deep Learning JP
PPTX
1017 論文紹介第四回
by
Kohei Wakamatsu
PPTX
北大調和系 DLゼミ A3C
by
Tomoya Oda
PDF
Rainbow
by
Takahiro Yoshinaga
PPTX
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
PDF
Discriminative Deep Dyna-Q: Robust Planning for Dialogue Policy Learning
by
TomoyasuOkada
PPTX
Deep reinforcement learning for imbalanced classification
by
Ogushi Masaya
PDF
論文紹介: Offline Q-Learning on diverse Multi-Task data both scales and generalizes
by
atsushi061452
PDF
introduction to double deep Q-learning
by
WEBFARMER. ltd.
PDF
20180830 implement dqn_platinum_data_meetup_vol1
by
Keisuke Nakata
PDF
強化学習とは (MIJS 分科会資料 2016/10/11)
by
Akihiro HATANAKA
PDF
introduction to Deep Q Learning
by
WEBFARMER. ltd.
分散型強化学習手法の最近の動向と分散計算フレームワークRayによる実装の試み
by
SusumuOTA
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
Deep Recurrent Q-Learning(DRQN) for Partially Observable MDPs
by
Hakky St
Batch Reinforcement Learning
by
Takuma Oda
Rainbow: Combining Improvements in Deep Reinforcement Learning (AAAI2018 unde...
by
Toru Fujino
機械学習 論文輪読会 Hybrid Reward Architecture for Reinforcement Learning
by
Yuko Ishizaki
Paper intoduction "Playing Atari with deep reinforcement learning"
by
Hiroshi Tsukahara
強化学習勉強会・論文紹介(Kulkarni et al., 2016)
by
Sotetsu KOYAMADA(小山田創哲)
[DL輪読会]Hyper parameter agnostic methods in reinforcement learning
by
Deep Learning JP
1017 論文紹介第四回
by
Kohei Wakamatsu
北大調和系 DLゼミ A3C
by
Tomoya Oda
Rainbow
by
Takahiro Yoshinaga
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
Discriminative Deep Dyna-Q: Robust Planning for Dialogue Policy Learning
by
TomoyasuOkada
Deep reinforcement learning for imbalanced classification
by
Ogushi Masaya
論文紹介: Offline Q-Learning on diverse Multi-Task data both scales and generalizes
by
atsushi061452
introduction to double deep Q-learning
by
WEBFARMER. ltd.
20180830 implement dqn_platinum_data_meetup_vol1
by
Keisuke Nakata
強化学習とは (MIJS 分科会資料 2016/10/11)
by
Akihiro HATANAKA
introduction to Deep Q Learning
by
WEBFARMER. ltd.
More from harmonylab
PDF
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Lea...
by
harmonylab
PDF
Data Scaling Laws for End-to-End Autonomous Driving
by
harmonylab
PDF
Mixture-of-Personas Language Models for Population Simulation
by
harmonylab
PDF
Mixture-of-Personas Language Models for Population Simulation
by
harmonylab
PDF
TransitReID: Transit OD Data Collection with Occlusion-Resistant Dynamic Pass...
by
harmonylab
PDF
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
by
harmonylab
PDF
Efficient anomaly detection in tabular cybersecurity data using large languag...
by
harmonylab
PDF
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
by
harmonylab
PDF
Multiple Object Tracking as ID Prediction
by
harmonylab
PDF
Encoding and Controlling Global Semantics for Long-form Video Question Answering
by
harmonylab
PDF
Can Large Language Models perform Relation-based Argument Mining?
by
harmonylab
PDF
Towards Scalable Human-aligned Benchmark for Text-guided Image Editing
by
harmonylab
PDF
【卒業論文】LLMを用いたMulti-Agent-Debateにおける反論の効果に関する研究
by
harmonylab
PDF
CTINexus: Automatic Cyber Threat Intelligence Knowledge Graph Construction Us...
by
harmonylab
PDF
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models throu...
by
harmonylab
PDF
AECR: Automatic attack technique intelligence extraction based on fine-tuned ...
by
harmonylab
PDF
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
by
harmonylab
PDF
APT-LLM Embedding-Based Anomaly Detection of Cyber Advanced Persistent Threat...
by
harmonylab
PDF
QuASAR: A Question-Driven Structure-Aware Approach for Table-to-Text Generation
by
harmonylab
PDF
Collaborative Document Simplification Using Multi-Agent Systems
by
harmonylab
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Lea...
by
harmonylab
Data Scaling Laws for End-to-End Autonomous Driving
by
harmonylab
Mixture-of-Personas Language Models for Population Simulation
by
harmonylab
Mixture-of-Personas Language Models for Population Simulation
by
harmonylab
TransitReID: Transit OD Data Collection with Occlusion-Resistant Dynamic Pass...
by
harmonylab
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
by
harmonylab
Efficient anomaly detection in tabular cybersecurity data using large languag...
by
harmonylab
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
by
harmonylab
Multiple Object Tracking as ID Prediction
by
harmonylab
Encoding and Controlling Global Semantics for Long-form Video Question Answering
by
harmonylab
Can Large Language Models perform Relation-based Argument Mining?
by
harmonylab
Towards Scalable Human-aligned Benchmark for Text-guided Image Editing
by
harmonylab
【卒業論文】LLMを用いたMulti-Agent-Debateにおける反論の効果に関する研究
by
harmonylab
CTINexus: Automatic Cyber Threat Intelligence Knowledge Graph Construction Us...
by
harmonylab
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models throu...
by
harmonylab
AECR: Automatic attack technique intelligence extraction based on fine-tuned ...
by
harmonylab
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
by
harmonylab
APT-LLM Embedding-Based Anomaly Detection of Cyber Advanced Persistent Threat...
by
harmonylab
QuASAR: A Question-Driven Structure-Aware Approach for Table-to-Text Generation
by
harmonylab
Collaborative Document Simplification Using Multi-Agent Systems
by
harmonylab
Recently uploaded
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
A3C解説
1.
Volodymyr Mnih,Adrià Puigdomènech
Badia,Mehdi Mirza,et al. arXiv:1602.01783v2 [cs.LG] 16 Jun 2016 Asynchronous Methods for Deep Reinforcement Learning DeepLearningゼミ M1小川一太郎
2.
DQNおさらい • 𝑄 𝑠,
𝑎 ← 𝑄 𝑠, 𝑎 + 𝛼( 𝑟 + 𝛾𝑚𝑎𝑥𝑄∗ 𝑠′ , 𝑎′ − 𝑄(𝑠, 𝑎)) • 行動したあとの状態をもとに、報酬(r)と遷移後の行動価値(Q*)を判断する • Experience Replay 学習データをランダムに選択 • 学習データの相関をなくす • Reword Clipping • 報酬を±1に(大きさの固定) • Target Network • 教師データのNNを遅れて更新 • Loss Clipping • Qの更新時の勾配の大きさの最大最小値を±1に(大きな更新を防ぐ)
3.
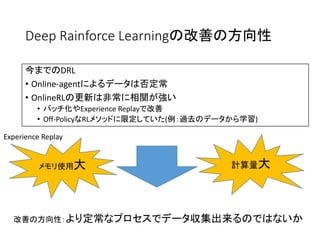
Deep Rainforce Learningの改善の方向性 今までのDRL •
Online-agentによるデータは否定常 • OnlineRLの更新は非常に相関が強い • バッチ化やExperience Replayで改善 • Off-PolicyなRLメソッドに限定していた(例:過去のデータから学習) Experience Replay メモリ使用大 計算量大 改善の方向性:より定常なプロセスでデータ収集出来るのではないか
4.
非同期並列な学習 • データを非同期並列に学習する • エージェント&学習部の探索方針が違う 利点:学習が安定化 •
学習時間がactor-learnerの分だけ減らせる • Experience Replayに頼らないため、on-poicyなメソッドを使用できる Off-Policy ON-Policy Q学習 • Sarsa • n-step methods • Actor-Critic methods メソッド例
5.
On-Policyなメソッド① Sarsa • ほぼQ学習と同じ • 更新式𝑄
𝑠, 𝑎 ← 𝑄 𝑠, 𝑎 + 𝛼 𝑟 + 𝛾𝑄 𝑠′ , 𝑎′ − 𝑄 𝑠, 𝑎 • maxQ*ではなく、実際の行動a’を使用 N-step Q-Learning • 更新式(変化部分だけ) (𝑟𝑡+𝛾𝑟𝑡+1 + 𝛾2 𝑟𝑡+2 + ⋯ + 𝛾 𝑛−1 𝑟𝑡+𝑛−1) + 𝛾 𝑛 𝑚𝑎𝑥𝑄∗ 𝑠𝑡+𝑛, 𝑎 𝑡+𝑛 − 𝑄 𝑠, 𝑎 • N回分まで実際に得た報酬を使用して学習
6.
On-Policyなメソッド② Actor-Critic • 状態の表現方法 • 価値関数とは別に方策を表現する •
行動選択(P:状態sで行動aとる確率) • 𝜋 𝑡 𝑠, 𝑎 = 𝑃𝑟 𝑎 𝑡 = 𝑎 𝑠𝑡 = 𝑠 = 𝑒 𝑃(𝑠,𝑎) 𝑏 𝑒 𝑃(𝑠,𝑏) • 状態価値観数 • 𝑉 𝑠𝑡 ← 𝑉 𝑠𝑡 + 𝛼[𝑟𝑡+1 + 𝛾𝑉 𝑠𝑡+1 − 𝑉(𝑠𝑡)] • 𝑃 𝑠𝑡, 𝑎 𝑡 ← 𝑃 𝑠𝑡, 𝑎 𝑡 + 𝛽𝛿𝑡
7.
非同期並列な強化学習(Q学習) ローカルなQネット(θ)を使用して それぞれのacter-learnerで勾配を蓄積 一定回数ごとにTネット(θ-)を グローバルなQネット(θ)から更新 蓄積した勾配をもとに、一定回数ごとに グローバルなQネット(θ)を更新 異なる探索方式が存在しているた め、ロバスト性が改善される
8.
A3C asynchronous advantage
actor-critic 規定の回数まで行動する 行動にはθを用いる 報酬計算はθ’を用いる 終了から報酬を逆算する θとθ’を更新 CNN層のみ共有し、出力は 方策:ソフトマックス 価値:線形結合
9.
実験 Atari2600 • DQNと同様にAtari2600のスコアを計算 •
グラフの縦軸はスコア、横軸は時間 • 16スレッド • エピソード長5 同期頻度5 NNの構造 • 16filter 8*8size stride4 • 32filter 4*4size stride2 • 256 hidden 57ゲームにおいて人間のスコアと比較。 A3CにLSTM層を追加したものが非常に 高い値を記録している。
10.
実験 Atari2600 • 各手法でゲームをしたときのスコアを比較 •
それぞれの値は提唱された論文に記載のものを使用 • 57種類のゲームのうち最大の点数となったもの • A3C FF, 1day 3種類 • A3C FF 4種類 • L3C LSTM 19種類 (最後に256のLSTM層) 他手法との比較(例)
11.
TORCS Car Racing
Simulator • Atariの時と同じアーキテクチャ • 12時間の学習 • 人のテスターが得たスコアのだいたい75%~90%を得ることができる
12.
Labyrinth • りんごを獲得 1pt •
ゴールに到達 10pt • 60秒で1エピソード
13.
まとめ • 非同期並列なDRLの方法を提唱した • A3Cは既存の手法よりも良い結果を残した •
ARLの利点として • Experience Replayを使用しないため探索に方策を持つことができる • エージェント、学習部の探索方針が違うため、学習データの相関が減少 • マルチCPUで動作するため、通信コストが削減
14.
参考資料 • Asynchronous Methods
for Deep Reinforcement Learning (紹介論文) Volodymyr Mnih,Adrià Puigdomènech Badia,Mehdi Mirza,et al. https://arxiv.org/pdf/1602.01783.pdf • 強化学習の基礎 小池 康晴 東京工業大学 精密工学研究所 鮫島 和行 科学技術振興事業団 ERATO 川人学習動態脳プロジェク ト http://www.jnns.org/previous/niss/2000/text/koike2.pdf
Download
![Volodymyr Mnih,Adrià Puigdomènech Badia,Mehdi Mirza,et al.
arXiv:1602.01783v2 [cs.LG] 16 Jun 2016
Asynchronous Methods for Deep
Reinforcement Learning
DeepLearningゼミ M1小川一太郎](https://image.slidesharecdn.com/dla3c-170613050925/85/A3C-1-320.jpg)



![On-Policyなメソッド②
Actor-Critic
• 状態の表現方法
• 価値関数とは別に方策を表現する
• 行動選択(P:状態sで行動aとる確率)
• 𝜋 𝑡 𝑠, 𝑎 = 𝑃𝑟 𝑎 𝑡 = 𝑎 𝑠𝑡 = 𝑠 =
𝑒 𝑃(𝑠,𝑎)
𝑏 𝑒 𝑃(𝑠,𝑏)
• 状態価値観数
• 𝑉 𝑠𝑡 ← 𝑉 𝑠𝑡 + 𝛼[𝑟𝑡+1 + 𝛾𝑉 𝑠𝑡+1 − 𝑉(𝑠𝑡)]
• 𝑃 𝑠𝑡, 𝑎 𝑡 ← 𝑃 𝑠𝑡, 𝑎 𝑡 + 𝛽𝛿𝑡](https://image.slidesharecdn.com/dla3c-170613050925/85/A3C-6-320.jpg)








![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[DL輪読会]Hyper parameter agnostic methods in reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/hyperparameteragnosticmethodsinreinforcementlearning-180622004902-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)






































